4个回答
6
如果您不知道底层分布,那么我的第一想法是使用引导法(bootstrapping):https://zh.wikipedia.org/wiki/引导法
在伪代码中,假设
x是包含数据的numpy数组:import numpy as np
N = 10000
mean_estimates = []
for _ in range(N):
re_sample_idx = np.random.randint(0, len(x), x.shape)
mean_estimates.append(np.mean(x[re_sample_idx]))
mean_estimates现在是一个包含10000个该分布均值的估计值的列表。取这10000个数中的第2.5%和第97.5%的百分位数,就可以得到数据均值的置信区间:
sorted_estimates = np.sort(np.array(mean_estimates))
conf_interval = [sorted_estimates[int(0.025 * N)], sorted_estimates[int(0.975 * N)]]
- acdr
1
1我已经使用真实数据进行了测试,看起来有误。我得到的置信区间为[22.78, 69.93]。(np.array(x) < 22.79).sum() / len(x) - 0.91。91%的数据低于下限置信界限。算术平均值为40.78-这是一个棘手的真实世界数据集。 - Brans Ds
2
您可以使用Bootstrap方法来近似任何量,这些量也来自未知分布。
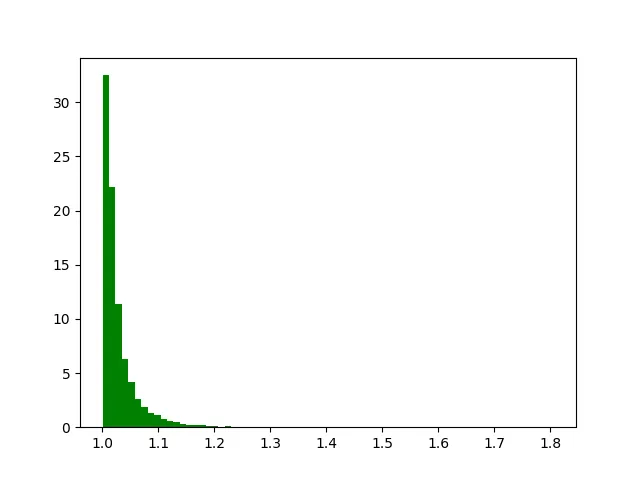
模拟从帕累托分布中获取的一些数据:
绘制结果。
"low_ci[0]"和"up_ci[0]"是形状参数的置信区间。
def bootstrap_ci(
data,
statfunction=np.average,
alpha = 0.05,
n_samples = 100):
"""inspired by https://github.com/cgevans/scikits-bootstrap"""
import warnings
def bootstrap_ids(data, n_samples=100):
for _ in range(n_samples):
yield np.random.randint(data.shape[0], size=(data.shape[0],))
alphas = np.array([alpha/2, 1 - alpha/2])
nvals = np.round((n_samples - 1) * alphas).astype(int)
if np.any(nvals < 10) or np.any(nvals >= n_samples-10):
warnings.warn("Some values used extremal samples; results are probably unstable. "
"Try to increase n_samples")
data = np.array(data)
if np.prod(data.shape) != max(data.shape):
raise ValueError("Data must be 1D")
data = data.ravel()
boot_indexes = bootstrap_ids(data, n_samples)
stat = np.asarray([statfunction(data[_ids]) for _ids in boot_indexes])
stat.sort(axis=0)
return stat[nvals]
模拟从帕累托分布中获取的一些数据:
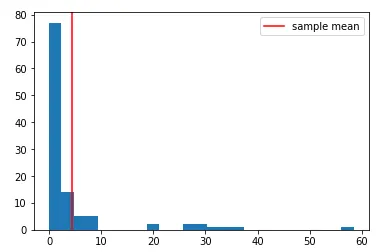
np.random.seed(33)
data = np.random.pareto(a=1, size=111)
sample_mean = np.mean(data)
plt.hist(data, bins=25)
plt.axvline(sample_mean, c='red', label='sample mean'); plt.legend()
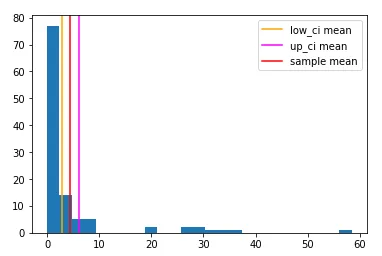
low_ci, up_ci = bootstrap_ci(data, np.mean, n_samples=1000)
绘制结果。
plt.hist(data, bins=25)
plt.axvline(low_ci, c='orange', label='low_ci mean')
plt.axvline(up_ci, c='magenta', label='up_ci mean')
plt.axvline(sample_mean, c='red', label='sample mean'); plt.legend()
from scipy.stats import pareto
true_params = pareto.fit(data)
low_ci, up_ci = bootstrap_ci(data, pareto.fit, n_samples=1000)
"low_ci[0]"和"up_ci[0]"是形状参数的置信区间。
low_ci[0], true_params[0], up_ci[0] ---> (0.8786, 1.0983, 1.4599)
- Marco Cerliani
1
从其他答案的讨论中,我假设您想要一个与总体均值有关的置信区间,是吗?(您必须对某个数量拥有置信区间,而不是分布本身。)
对于所有具有有限矩的分布,均值的抽样分布渐近地趋向于具有均值等于总体均值和方差等于总体方差除以n的正态分布。因此,如果您有大量数据,则 $\mu \pm \Phi^{-1}(p) \sigma / \sqrt{n}$ 应该是总体均值p置信区间的很好近似,即使分布不是正态分布。
- David Wright
0
当前的解决方案不起作用,因为randint似乎已经被弃用了
np.random.seed(10)
point_estimates = [] # Make empty list to hold point estimates
for x in range(200): # Generate 200 samples
sample = np.random.choice(a= x, size=x.shape)
point_estimates.append( sample.mean() )
sorted_estimates = np.sort(np.array(point_estimates))
conf_interval = [sorted_estimates[int(0.025 * N)], sorted_estimates[int(0.975 * N)]]
print(conf_interval, conf_interval[1] - conf_interval[0])
pd.DataFrame(point_estimates).plot(kind="density", legend= False)
- Rocketq
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接