当样本量很小,甚至样本量为1时,计算比例置信区间(CI)的更好方法是什么?
我目前使用以下方式计算单个样本中比例的CI: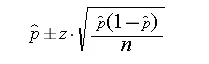 然而,我的样本量非常小,有时甚至只有1。我还尝试了使用以下公式来近似计算小样本中比例p的(1-α)100%置信区间:
然而,我的样本量非常小,有时甚至只有1。我还尝试了使用以下公式来近似计算小样本中比例p的(1-α)100%置信区间:
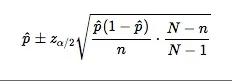
我目前使用以下方式计算单个样本中比例的CI:
然而,我的样本量非常小,有时甚至只有1。我还尝试了使用以下公式来近似计算小样本中比例p的(1-α)100%置信区间:
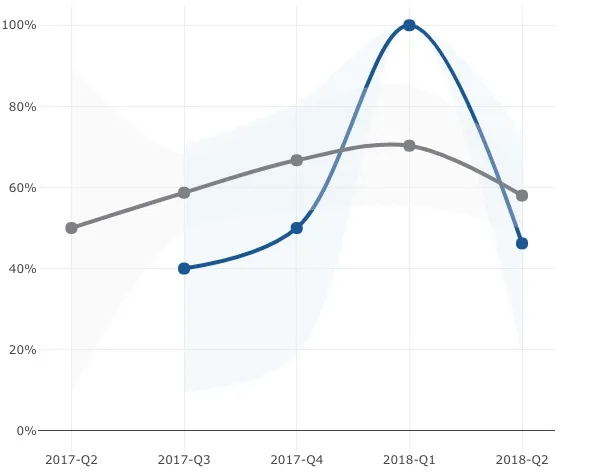
具体而言,我正在尝试实现这两个公式来计算比例的置信区间。如下图所示,在2018-Q1时,蓝色组没有置信区间,因为在2018-Q1有1个人选择了该项。如果使用有限人口修正(FPC),则在N等于1时不会修正CI。 因此,我的问题是什么是解决100%比例的小样本问题的最佳统计方法。
- 如果您能提供一个用Python计算它的包,那就太好了!谢谢!