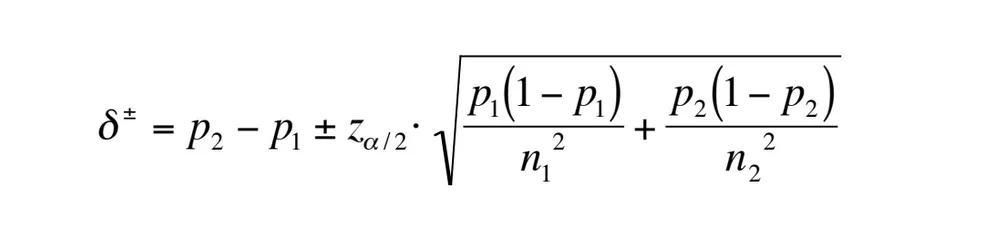例如,在AB测试中,A人群可能有1000个数据点,其中100个是成功的。而B可能有2000个数据点和220个成功。这使得A的成功比例为0.1,B为0.11,其差值为0.01。我如何在Python中计算此差异的置信区间?
统计模型可以为一个样本完成此操作,但似乎没有处理两个样本之间差异的软件包,这对于AB测试是必要的。(http://www.statsmodels.org/dev/generated/statsmodels.stats.proportion.proportion_confint.html)
统计模型可以为一个样本完成此操作,但似乎没有处理两个样本之间差异的软件包,这对于AB测试是必要的。(http://www.statsmodels.org/dev/generated/statsmodels.stats.proportion.proportion_confint.html)