我正在使用一组介于 0 到 1000 之间的随机数创建 R 中的密度曲线,并着色小于或等于特定值的部分。有很多解决方案涉及到 geom_area 或 geom_ribbon,但它们都需要一个 y 值,而我没有(只是 1000 个数字的向量)。请问有什么办法可以做到这一点吗?
另外还有两个相关的问题:
- 对于累积分布函数是否也可以使用相同的方法(我目前正在使用
stat_ecdf生成它),或者可以着色吗? - 是否可以编辑
geom_vline让它只延伸到密度曲线的高度而非整个 y 轴?
代码:(geom_area 是修改我找到的一些代码的失败尝试。如果手动设置 ymax,则只会得到占据整个图形的列,而不是曲线下面的面积)
set.seed(100)
amount_spent <- rnorm(1000,500,150)
amount_spent1<- data.frame(amount_spent)
rand1 <- runif(1,0,1000)
amount_spent1$pdf <- dnorm(amount_spent1$amount_spent)
mean1 <- mean(amount_spent1$amount_spent)
#density/bell curve
ggplot(amount_spent1,aes(amount_spent)) +
geom_density( size=1.05, color="gray64", alpha=.5, fill="gray77") +
geom_vline(xintercept=mean1, alpha=.7, linetype="dashed", size=1.1, color="cadetblue4")+
geom_vline(xintercept=rand1, alpha=.7, linetype="dashed",size=1.1, color="red3")+
geom_area(mapping=aes(ifelse(amount_spent1$amount_spent > rand1,amount_spent1$amount_spent,0)), ymin=0, ymax=.03,fill="red",alpha=.3)+
ylab("")+
xlab("Amount spent on lobbying (in Millions USD)")+
scale_x_continuous(breaks=seq(0,1000,100))
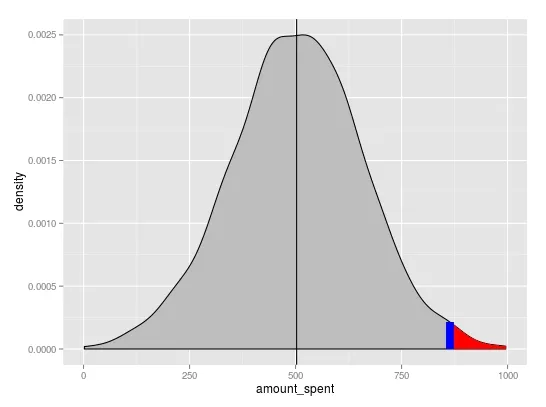
p是你的基本密度图:d <- ggplot_build(p)$data[[1]] ; p + geom_area(data = subset(d, x > rand1), aes(x=x, y=y), fill="red")。 - user20650