我正在编写代码,用于生成图书馆中不同书籍数量的置信区间(以及生成信息丰富的图表)。
我的表弟在小学,每周老师都会给他一本书。然后他读完后按时归还,以便下周再借一本。过了一段时间,我们开始注意到他借到了之前已经读过的书,而这种情况随着时间的推移变得越来越普遍。
假设图书馆中实际的书籍数为N,并且老师每周随机(有放回地)选择一本书籍送给你。如果在第t周,你已经收到x本已经读过的书籍,则我可以根据https://math.stackexchange.com/questions/615464/how-many-books-are-in-a-library的方法生成图书馆中书籍数量的最大似然估计。
例子: 假设图书馆有五本书A、B、C、D和E。如果你在连续七周内接收到[A、B、A、C、B、B、D]这几本书,那么在每一周结束时重复的次数x(即已读的书的数量)将分别为[0、0、1、1、2、3、3],这意味着在七周后,你已经收到了三本已经读过的书。
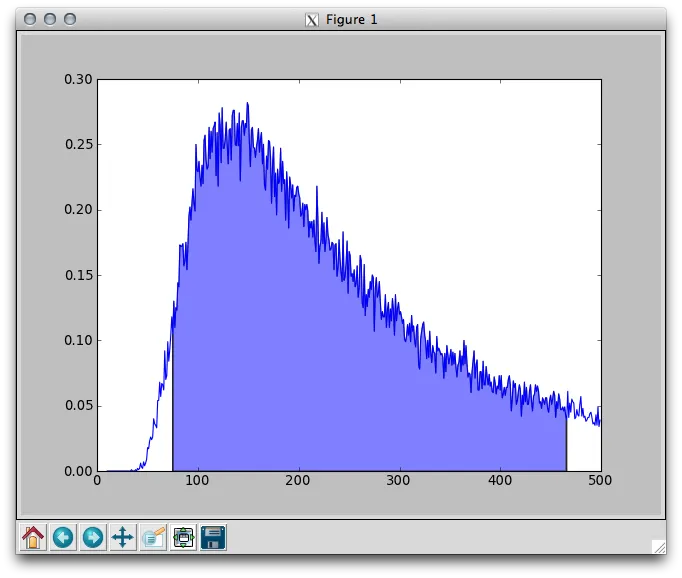
为了可视化似然函数(假设我正确理解了它),我编写了以下代码来绘制似然函数。最大值约为135,这确实是根据上面的MSE链接得出的最大似然估计。
from __future__ import division
import random
import matplotlib.pyplot as plt
import numpy as np
#N is the true number of books. t is the number of weeks.unk is the true number of repeats found
t = 30
unk = 3
def numberrepeats(N, t):
return t - len(set([random.randint(0,N) for i in xrange(t)]))
iters = 1000
ydata = []
for N in xrange(10,500):
sampledunk = [numberrepeats(N,t) for i in xrange(iters)].count(unk)
ydata.append(sampledunk/iters)
print "MLE is", np.argmax(ydata)
xdata = range(10, 500)
print len(xdata), len(ydata)
plt.plot(xdata,ydata)
plt.show()
输出结果如下:
问题如下:
- 有没有一种简单的方法来获取95%置信区间并在图表上绘制它? - 如何在图表上叠加平滑曲线? - 我的代码应该有更好的写法吗?它不太优雅,而且速度也很慢。
寻找95%置信区间意味着查找x轴的范围,以便我们通过抽样得到的经验最大似然估计(在此示例中应理论上为135)在95%的时间内落在其中。@mbatchkarov给出的答案目前未正确执行此操作。
现在在https://math.stackexchange.com/questions/656101/how-to-find-a-confidence-interval-for-a-maximum-likelihood-estimate上有一个数学答案。
 。
我会在有更多时间时尝试回答第三个问题 :)。
。
我会在有更多时间时尝试回答第三个问题 :)。