如果你进行最大似然计算,第一步需要做的是:假设一个依赖于某些参数的分布。由于你会
生成数据(你甚至知道你的参数),你会"告诉"程序假设高斯分布。但是,你不会告诉程序你的参数(0和1),而是将它们预先保留未知,并在之后计算它们。
现在,你有了样本向量(我们称之为
x,其元素为
x[0]到
x[100]),你必须对它进行处理。为此,你需要计算以下内容(
f表示
高斯分布的概率密度函数):
f(x[0]) * ... * f(x[100])
如您在我给出的链接中所见,f使用两个参数(希腊字母µ和σ)。现在,您需要以某种方式计算µ和σ的值,使得f(x[0]) * ... * f(x[100])取最大可能值。
完成后,µ就是均值的最大似然值,σ是标准差的最大似然值。
请注意,我没有明确告诉您如何计算µ和σ的值,因为这是一个相当数学的过程,我手头没有(而且可能我也不会理解);我只是告诉您获取值的技术,该技术也可以应用于任何其他分布。
由于您想要最大化原始术语,因此您可以“简单地”最大化原始术语的对数-这样可以避免处理所有这些乘积,并将原始术语转换为具有一些求和项的总和。
如果您真的想计算它,可以进行一些简化,从而得到以下术语(希望我没有搞砸任何东西):
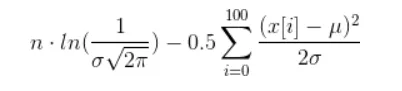
现在,你需要找到 µ 和 σ 的值,使得上述函数最大化。这是一个非常不平凡的任务,称为非线性优化。
一种简化的方法是:固定一个参数,尝试计算另一个参数。这样可以避免同时处理两个变量。