这里使用
symfit试着解决这个问题。我选择从一个没有协方差的二元正态分布中进行抽样作为示例。"最初的回答"。
import numpy as np
import matplotlib.pyplot as plt
from symfit import Model, Fit, Parameter, Variable, integrate, oo
from symfit.distributions import Gaussian
from symfit.core.objectives import LogLikelihood
x = Variable('x')
y = Variable('y')
m = Variable('m')
x0 = Parameter('x0', value=0.6, min=0.5, max=0.7)
sig_x = Parameter('sig_x', value=0.1)
y0 = Parameter('y0', value=0.7, min=0.6, max=0.9)
sig_y = Parameter('sig_y', value=0.05)
pdf = Gaussian(x=x, mu=x0, sig=sig_x) * Gaussian(x=y, mu=y0, sig=sig_y)
marginal = integrate(pdf, (y, -oo, oo), conds='none')
print(pdf)
print(marginal)
model = Model({m: marginal})
mean = [0.59, 0.8]
cov = [[0.11**2, 0], [0, 0.23**2]]
xdata, ydata = np.random.multivariate_normal(mean, cov, 10000).T
fit = Fit(model, xdata, objective=LogLikelihood)
fit_result = fit.execute()
print(fit_result)
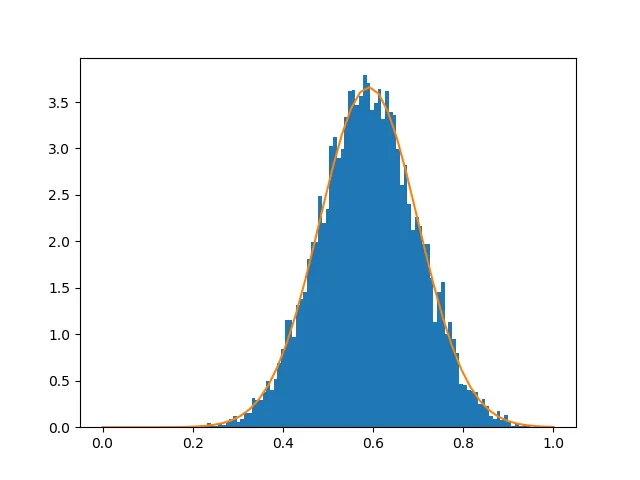
xaxis = np.linspace(0, 1.0)
plt.hist(xdata, bins=100, density=True)
plt.plot(xaxis, model(x=xaxis, **fit_result.params).m)
plt.show()
这将为PDF和边际分布打印以下内容:
这将在PDF和边际分布中打印以下内容:
>>> exp(-(-x0 + x)**2/(2*sig_x**2))*exp(-(-y0 + y)**2/(2*sig_y**2))/(2*pi*Abs(sig_x)*Abs(sig_y))
>>> sqrt(2)*sig_y*exp(-(-x0 + x)**2/(2*sig_x**2))/(2*sqrt(pi)*Abs(sig_x)*Abs(sig_y))
And for the fit results:
Parameter Value Standard Deviation
sig_x 1.089585e-01 7.704533e-04
sig_y 5.000000e-02 nan
x0 5.905688e-01 -0.000000e+00
Fitting status message: b'CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH'
Number of iterations: 9
Regression Coefficient: nan
你可以看到
x0和
sig_x已经被正确获得,但是关于
y参数的信息无法获得。我认为在这个例子中这是有道理的,因为没有相关性,但是我会让你自己去处理那些细节问题;)。
"最初的回答"

symfit能够帮助你,看看这个文档中的例子。然后,你就能够使用sympy风格的解析表达式,并且使用scipy将它们拟合到你的数据中,但是不必与scipy交互。注意:我是symfit的作者。 - tBuLi