如何在SciPy中拟合分布时检查收敛性?
我的目标是将SciPy分布(即Johnson S_U分布)拟合到数十个数据集中,作为自动化数据监控系统的一部分。大多数情况下都可以正常工作,但有几个数据集是异常的,明显不符合Johnson S_U分布。这些数据集的拟合会默默地发散,即没有任何警告/错误/等!相反,如果我切换到R并尝试在那里进行拟合,我永远不会得到收敛,这是正确的 - 无论拟合设置如何,R算法都拒绝宣布收敛。
数据: 两个数据集可在Dropbox中下载:
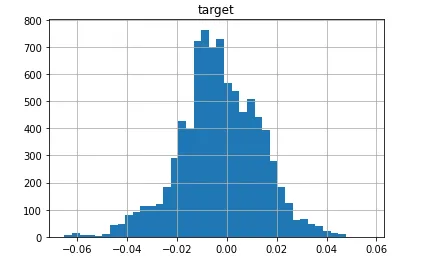
data-converging-fit.csv... 标准数据,拟合很好地收敛(您可能认为这是一个丑陋、偏斜且重心集中的块,但Johnson S_U足够灵活,可以适应这种情况!):
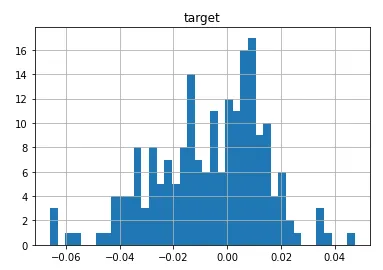
data-diverging-fit.csv... 一组异常数据,拟合发散:
适配分布的代码:
import pandas as pd
from scipy import stats
distribution_name = 'johnsonsu'
dist = getattr(stats, distribution_name)
convdata = pd.read_csv('data-converging-fit.csv', index_col= 'timestamp')
divdata = pd.read_csv('data-diverging-fit.csv', index_col= 'timestamp')
在良好的数据情况下,拟合参数具有相同的数量级:
a, b, loc, scale = dist.fit(convdata['target'])
a, b, loc, scale
[out]: (0.3154946859186918,
2.9938226613743932,
0.002176043693009398,
0.045430055488776266)
在异常数据上,拟合参数是不合理的:
a, b, loc, scale = dist.fit(divdata['target'])
a, b, loc, scale
[out]: (-3424954.6481554992,
7272004.43156841,
-71078.33596490842,
145478.1300979394)
仍然没有任何警告行,表明拟合失败了。
从StackOverflow上研究类似问题,我知道建议将我的数据分组,然后使用curve_fit。尽管它很实用,但我认为这种解决方案不正确,因为这不是我们拟合分布的方式:分组是任意的(bin的数量),并且会影响最终的拟合结果。一个更现实的选择可能是scipy.optimize.minimize和回调函数来学习收敛的进度;但我仍然不确定它是否最终会告诉我算法是否收敛。
fit()方法”)正是我想要的!我也感谢您提供的代码。 - Vojta F