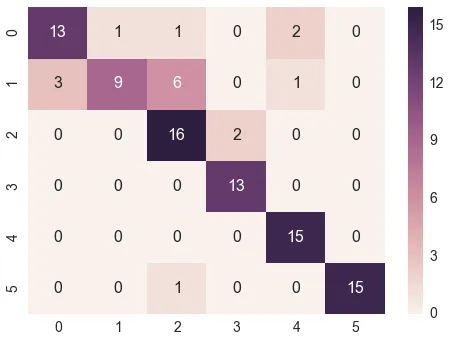
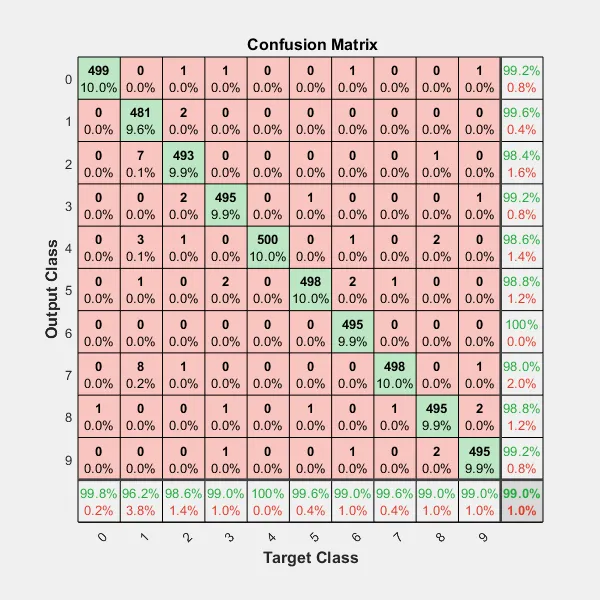
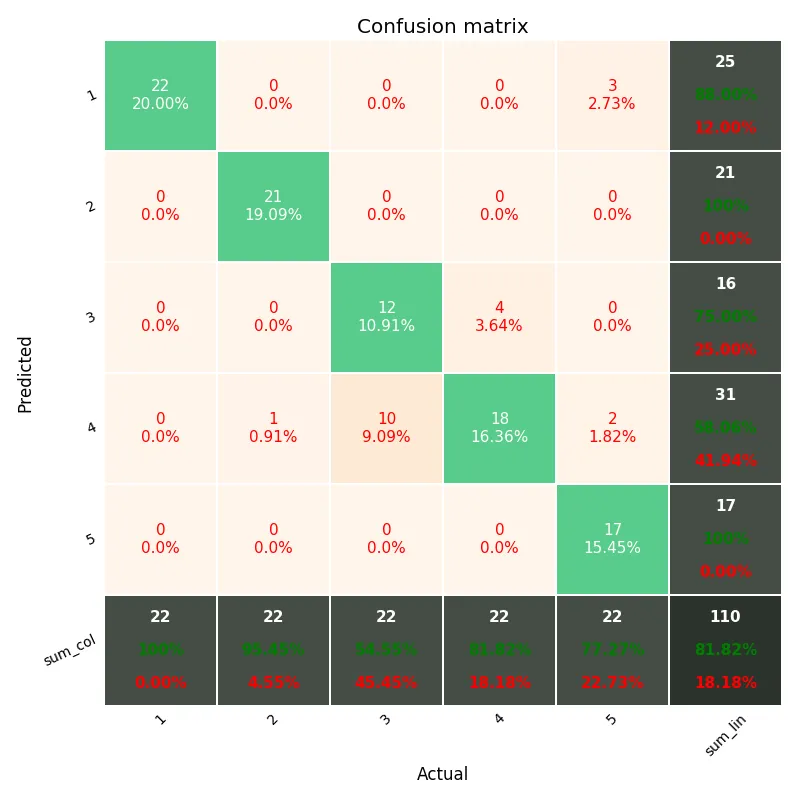
我正在使用scikit-learn对22000个文本文档进行100类别的分类。我使用了scikit-learn的混淆矩阵方法来计算混淆矩阵。
model1 = LogisticRegression()
model1 = model1.fit(matrix, labels)
pred = model1.predict(test_matrix)
cm=metrics.confusion_matrix(test_labels,pred)
print(cm)
plt.imshow(cm, cmap='binary')
这是我的混淆矩阵:
[[3962 325 0 ..., 0 0 0]
[ 250 2765 0 ..., 0 0 0]
[ 2 8 17 ..., 0 0 0]
...,
[ 1 6 0 ..., 5 0 0]
[ 1 1 0 ..., 0 0 0]
[ 9 0 0 ..., 0 0 9]]
然而,我没有得到一个清晰或易读的情节。有没有更好的方法来做到这一点?