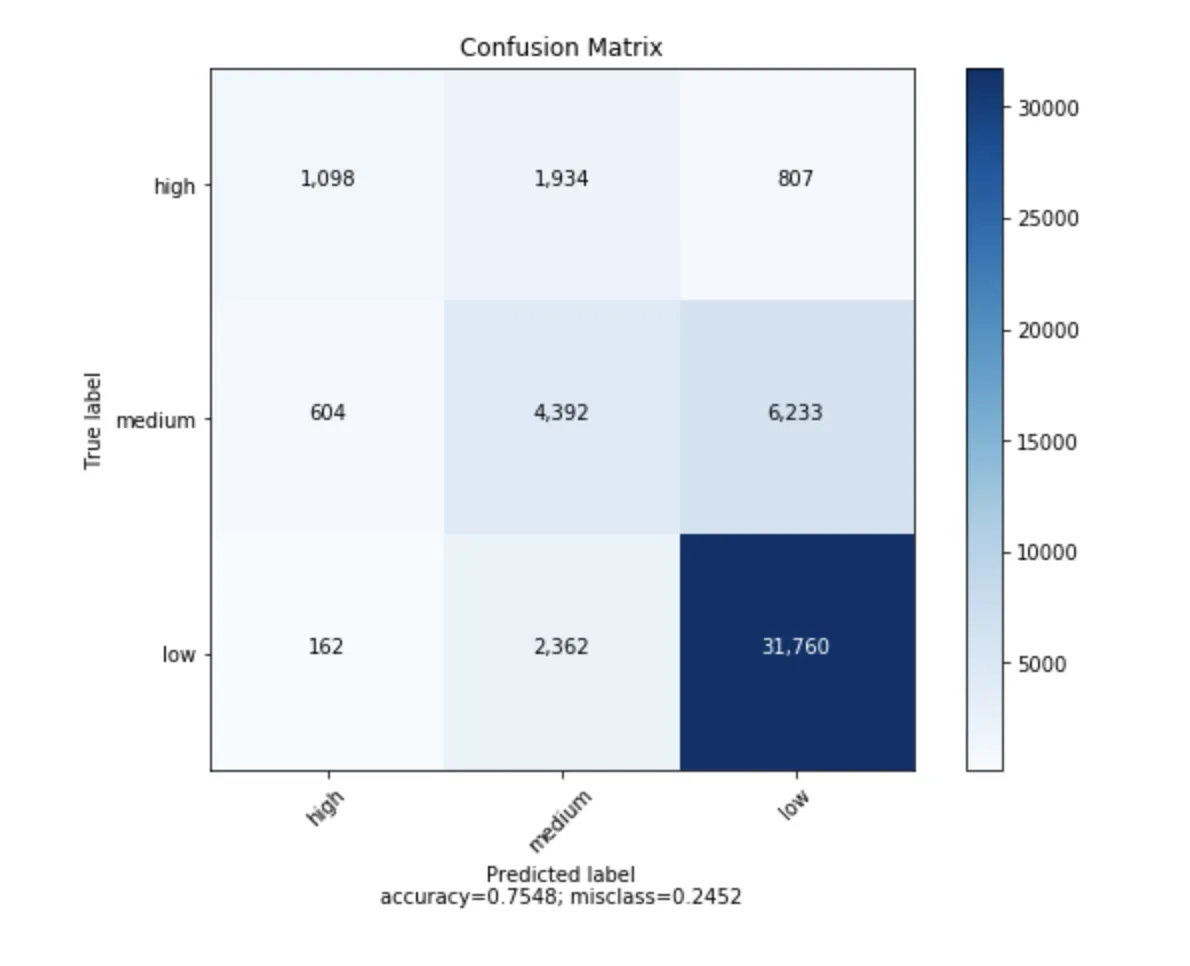
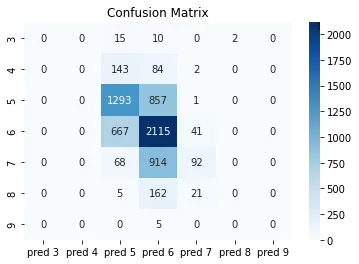
我找到了一个可以绘制使用
sklearn生成的混淆矩阵的函数。
import numpy as np
def plot_confusion_matrix(cm,
target_names,
title='Confusion matrix',
cmap=None,
normalize=True):
"""
given a sklearn confusion matrix (cm), make a nice plot
Arguments
---------
cm: confusion matrix from sklearn.metrics.confusion_matrix
target_names: given classification classes such as [0, 1, 2]
the class names, for example: ['high', 'medium', 'low']
title: the text to display at the top of the matrix
cmap: the gradient of the values displayed from matplotlib.pyplot.cm
see http://matplotlib.org/examples/color/colormaps_reference.html
plt.get_cmap('jet') or plt.cm.Blues
normalize: If False, plot the raw numbers
If True, plot the proportions
Usage
-----
plot_confusion_matrix(cm = cm, # confusion matrix created by
# sklearn.metrics.confusion_matrix
normalize = True, # show proportions
target_names = y_labels_vals, # list of names of the classes
title = best_estimator_name) # title of graph
Citiation
---------
http://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
"""
import matplotlib.pyplot as plt
import numpy as np
import itertools
accuracy = np.trace(cm) / float(np.sum(cm))
misclass = 1 - accuracy
if cmap is None:
cmap = plt.get_cmap('Blues')
plt.figure(figsize=(8, 6))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
if target_names is not None:
tick_marks = np.arange(len(target_names))
plt.xticks(tick_marks, target_names, rotation=45)
plt.yticks(tick_marks, target_names)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 1.5 if normalize else cm.max() / 2
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
if normalize:
plt.text(j, i, "{:0.4f}".format(cm[i, j]),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
else:
plt.text(j, i, "{:,}".format(cm[i, j]),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label\naccuracy={:0.4f}; misclass={:0.4f}'.format(accuracy, misclass))
plt.show()
它会看起来像这样