我正在寻找能帮我绘制混淆矩阵的人。我需要这个东西写学术论文。但是我对编程几乎没有经验。
在图片中,你可以看到我的分类报告和我的y_test和X_test的结构,在我的情况下,它们是dtree_predictions。
如果有人能帮我就太好了,因为我已经尝试了很多方法,但是我只得到了错误信息。
X_train, X_test, y_train, y_test = train_test_split(X, Y_profile, test_size = 0.3, random_state = 30)
dtree_model = DecisionTreeClassifier().fit(X_train,y_train)
dtree_predictions = dtree_model.predict(X_test)
print(metrics.classification_report(dtree_predictions, y_test))
precision recall f1-score support
0 1.00 1.00 1.00 222
1 1.00 1.00 1.00 211
2 1.00 1.00 1.00 229
3 0.96 0.97 0.96 348
4 0.89 0.85 0.87 93
5 0.86 0.86 0.86 105
6 0.94 0.93 0.94 116
7 1.00 1.00 1.00 364
8 0.99 0.97 0.98 139
9 0.98 0.99 0.99 159
10 0.97 0.96 0.97 189
11 0.92 0.92 0.92 124
12 0.92 0.92 0.92 119
13 0.95 0.96 0.95 230
14 0.98 0.96 0.97 452
15 0.91 0.96 0.93 210
micro avg 0.96 0.96 0.96 3310
macro avg 0.95 0.95 0.95 3310
weighted avg 0.97 0.96 0.96 3310
samples avg 0.96 0.96 0.96 3310
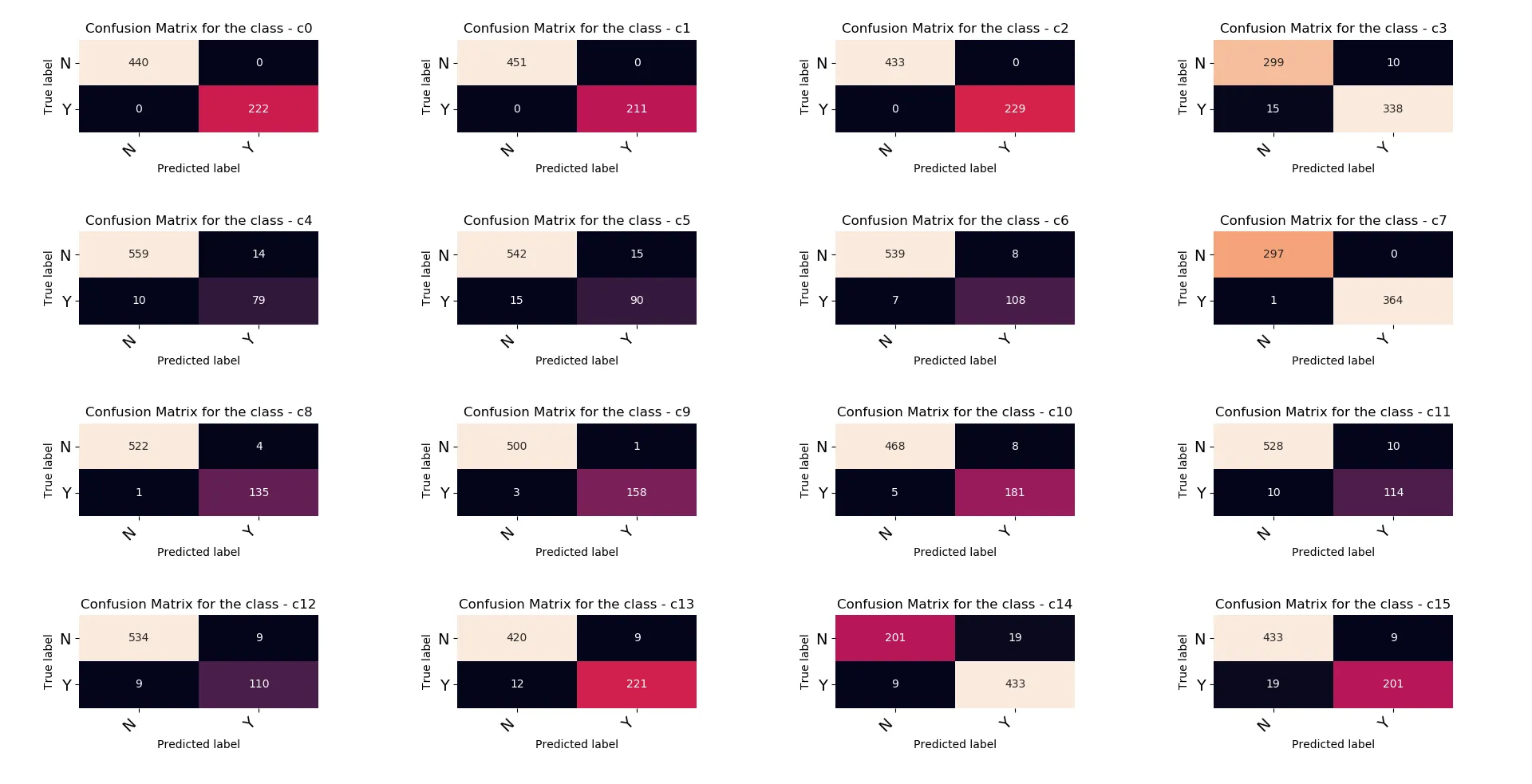
接下来我将打印多标签混淆矩阵的度量
from sklearn.metrics import multilabel_confusion_matrix
multilabel_confusion_matrix(y_test, dtree_predictions)
array([[[440, 0],
[ 0, 222]],
[[451, 0],
[ 0, 211]],
[[433, 0],
[ 0, 229]],
[[299, 10],
[ 15, 338]],
[[559, 14],
[ 10, 79]],
[[542, 15],
[ 15, 90]],
[[539, 8],
[ 7, 108]],
[[297, 0],
[ 1, 364]],
[[522, 4],
[ 1, 135]],
[[500, 1],
[ 3, 158]],
[[468, 8],
[ 5, 181]],
[[528, 10],
[ 10, 114]],
[[534, 9],
[ 9, 110]],
[[420, 9],
[ 12, 221]],
[[201, 19],
[ 9, 433]],
[[433, 9],
[ 19, 201]]])
关于y_test和dtree_predictons的结构。
print(dtree_predictions)
print(dtree_predictions.shape)
[[0. 0. 1. ... 0. 1. 0.]
[1. 0. 0. ... 0. 1. 0.]
[0. 0. 1. ... 0. 1. 0.]
...
[1. 0. 0. ... 0. 0. 1.]
[0. 1. 0. ... 1. 0. 1.]
[0. 1. 0. ... 1. 0. 1.]]
(662, 16)
print(y_test)
Cooler close to failure Cooler reduced effiency Cooler full effiency \
1985 0.0 0.0 1.0
322 1.0 0.0 0.0
2017 0.0 0.0 1.0
1759 0.0 0.0 1.0
1602 0.0 0.0 1.0
... ... ... ...
128 1.0 0.0 0.0
321 1.0 0.0 0.0
53 1.0 0.0 0.0
859 0.0 1.0 0.0
835 0.0 1.0 0.0
valve optimal valve small lag valve severe lag \
1985 0.0 0.0 0.0
322 0.0 1.0 0.0
2017 1.0 0.0 0.0
1759 0.0 0.0 0.0
1602 1.0 0.0 0.0
... ... ... ...
128 1.0 0.0 0.0
321 0.0 1.0 0.0
53 1.0 0.0 0.0
859 1.0 0.0 0.0
835 1.0 0.0 0.0
valve close to failure pump no leakage pump weak leakage \
1985 1.0 0.0 1.0
322 0.0 1.0 0.0
2017 0.0 0.0 1.0
1759 1.0 1.0 0.0
1602 0.0 1.0 0.0
... ... ... ...
128 0.0 1.0 0.0
321 0.0 1.0 0.0
53 0.0 1.0 0.0
859 0.0 1.0 0.0
835 0.0 1.0 0.0
pump severe leakage accu optimal pressure \
1985 0.0 0.0
322 0.0 1.0
2017 0.0 0.0
1759 0.0 1.0
1602 0.0 0.0
... ... ...
128 0.0 1.0
321 0.0 1.0
53 0.0 1.0
859 0.0 0.0
835 0.0 0.0
accu slightly reduced pressure accu severly reduced pressure \
1985 0.0 1.0
322 0.0 0.0
2017 0.0 1.0
1759 0.0 0.0
1602 0.0 0.0
... ... ...
128 0.0 0.0
321 0.0 0.0
53 0.0 0.0
859 0.0 0.0
835 0.0 0.0
accu close to failure stable flag stable stable flag not stable
1985 0.0 1.0 0.0
322 0.0 1.0 0.0
2017 0.0 1.0 0.0
1759 0.0 1.0 0.0
1602 1.0 0.0 1.0
... ... ... ...
128 0.0 0.0 1.0
321 0.0 1.0 0.0
53 0.0 0.0 1.0
859 1.0 0.0 1.0
835 1.0 0.0 1.0
[662 rows x 16 columns]