我使用Keras构建了一种图像分类CNN。尽管模型本身工作正常(它在新数据上的预测正确),但我在绘制混淆矩阵和模型分类报告方面遇到了问题。
我使用ImageDataGenerator对模型进行了训练。
train_path = '../DATASET/TRAIN'
test_path = '../DATASET/TEST'
IMG_BREDTH = 30
IMG_HEIGHT = 60
num_classes = 2
train_batch = ImageDataGenerator(featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=45,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
vertical_flip=False).flow_from_directory(train_path,
target_size=(IMG_HEIGHT, IMG_BREDTH),
classes=['O', 'R'],
batch_size=100)
test_batch = ImageDataGenerator().flow_from_directory(test_path,
target_size=(IMG_HEIGHT, IMG_BREDTH),
classes=['O', 'R'],
batch_size=100)
这是混淆矩阵和分类报告的代码。
batch_size = 100
target_names = ['O', 'R']
Y_pred = model.predict_generator(test_batch, 2513 // batch_size+1)
y_pred = np.argmax(Y_pred, axis=1)
print('Confusion Matrix')
cm = metrics.confusion_matrix(test_batch.classes, y_pred)
print(cm)
print('Classification Report')
print(metrics.classification_report(test_batch.classes, y_pred))
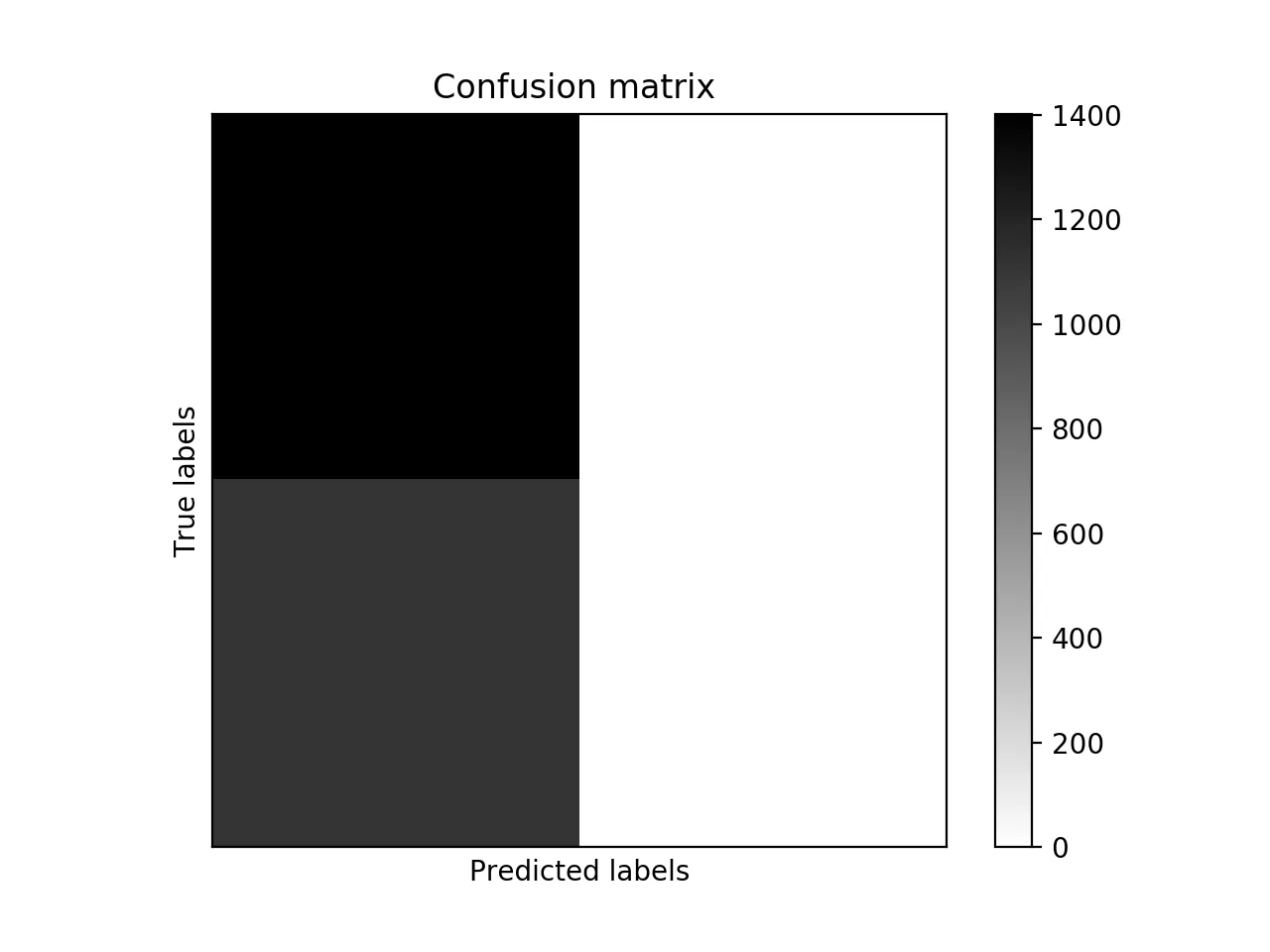
对于混淆矩阵,我得到了滚动结果(似乎是错误的)。
Confusion Matrix
[[1401 0]
[1112 0]]
假阳性和真阳性的数量都是0。分类报告输出以下内容和警告信息。
Classification Report
precision recall f1-score support
0 0.56 1.00 0.72 1401
1 0.00 0.00 0.00 1112
avg / total 0.31 0.56 0.40 2513
/Users/sashaanksekar/anaconda3/lib/python3.6/site-packages/sklearn/metrics/classification.py:1135: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples.
'precision', 'predicted', average, warn_for)
我正在尝试预测一个物体是有机的还是可回收的。我有大约22000张训练图像和2513张测试图像。
我对机器学习还不熟悉。我做错了什么吗?
提前感谢。
metrics.confusion_matrix()函数中正确插入y_pred和y_true。此外,导致表现欠佳可能的原因是过度拟合或糟糕的模型。你是否使用交叉验证? - seralouk