我正在使用 sklearn.metrics 中的 plot_confusion_matrix。我想把这些混淆矩阵像子图一样并排显示,应该怎么做?
使用plot_confusion_matrix绘制多个混淆矩阵。
7
- Suzy
2个回答
26
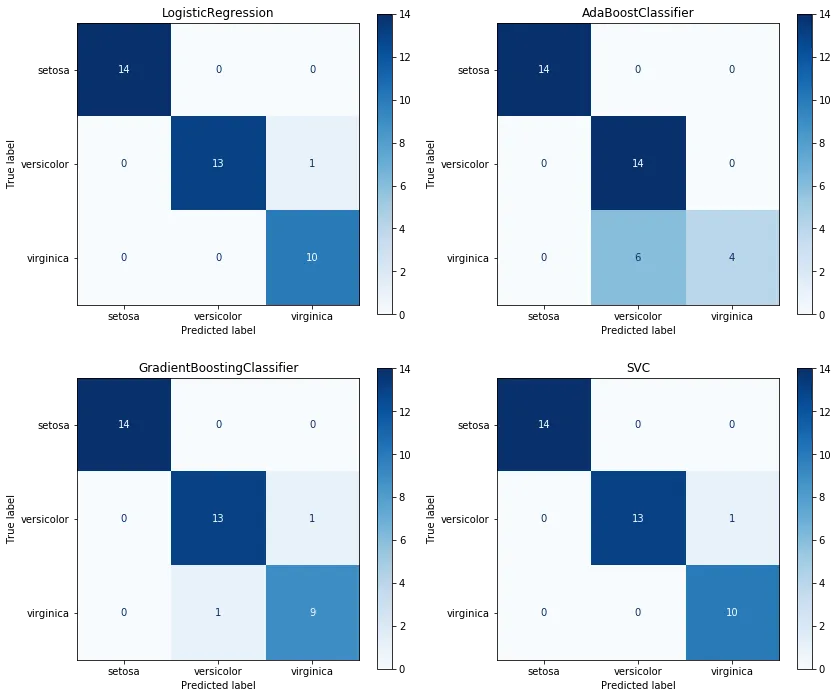
我们可以使用经典的鸢尾花数据集来重现这个过程,并拟合多个分类器以绘制它们各自的混淆矩阵,使用plot_confusion_matrix函数:
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from matplotlib import pyplot as plt
from sklearn.datasets import load_iris
from sklearn.metrics import plot_confusion_matrix
data = load_iris()
X = data.data
y = data.target
设置 -
X_train, X_test, y_train, y_test = train_test_split(X, y)
classifiers = [LogisticRegression(solver='lbfgs'),
AdaBoostClassifier(),
GradientBoostingClassifier(),
SVC()]
for cls in classifiers:
cls.fit(X_train, y_train)
因此,您可以通过使用plt.subplots创建一组子图,在视觉上比较所有矩阵。然后迭代轴对象和训练过的分类器(plot_confusion_matrix期望它们作为输入),并绘制各个混淆矩阵:
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(15,10))
for cls, ax in zip(classifiers, axes.flatten()):
plot_confusion_matrix(cls,
X_test,
y_test,
ax=ax,
cmap='Blues',
display_labels=data.target_names)
ax.title.set_text(type(cls).__name__)
plt.tight_layout()
plt.show()
- yatu
1
1
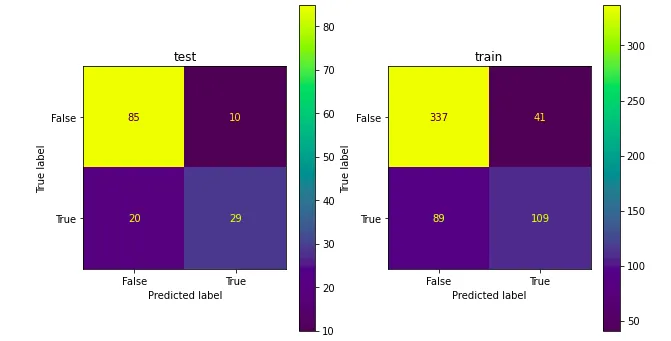
如果您想要的输出是这样的,这是我看到多个混淆矩阵(confusion_matrix)并排显示的方法,使用ConfusionMatrixDisplay。
{kind=link}
注意:在metrics.confusion_matrix()函数中粘贴您自己的测试和训练数据名称。
fig, ax = plt.subplots(1, 2)
ax[0].set_title("test")
ax[1].set_title("train")
metrics.ConfusionMatrixDisplay(
confusion_matrix=metrics.confusion_matrix(y_test, y_pred),
display_labels=[False, True]).plot(ax=ax[0])
metrics.ConfusionMatrixDisplay(
confusion_matrix=metrics.confusion_matrix(y_train, y_train_pred),
display_labels=[False, True]).plot(ax=ax[1])
- Harun Yüksel
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
plot_confusion_matrix在版本 1.0 中已经弃用,并将在版本 1.2 中被移除。请使用以下类方法之一:ConfusionMatrixDisplay.from_predictions或ConfusionMatrixDisplay.from_estimator。 - Tonechas