我有一个包含12个类别的多标签分类问题。我使用Tensorflow的slim来训练模型,使用在ImageNet上预训练的模型。以下是每个类别在训练和验证中的出现百分比。
问题在于模型没有收敛,在验证集上的 ROC 曲线下面积(Az)很差,类似于:
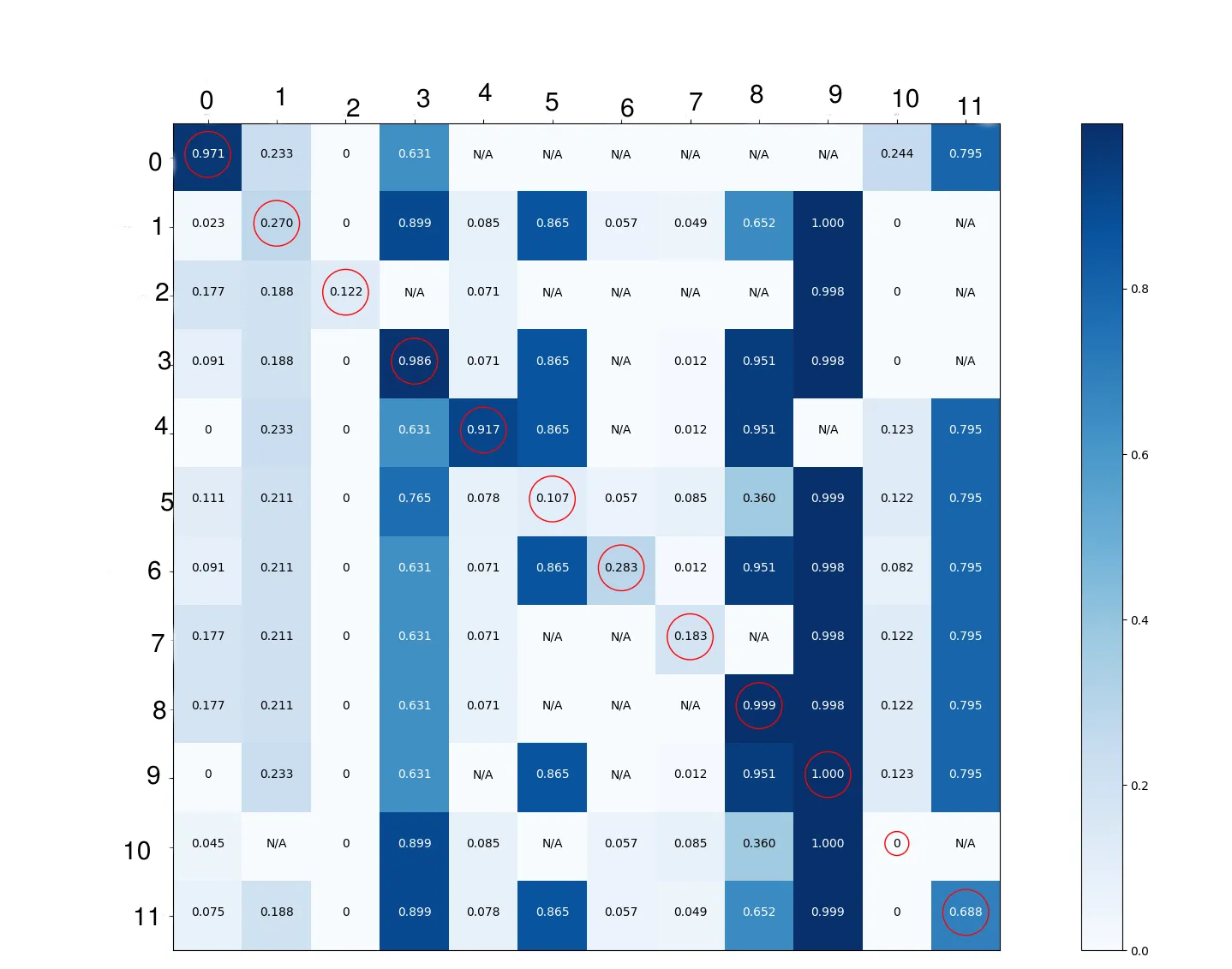
我不知道为什么有些类表现良好,而其他类则不行。我决定深入了解神经网络学习的细节。我知道混淆矩阵仅适用于二元或多类分类。因此,为了能够绘制它,我必须将问题转换为一系列多类分类。尽管该模型使用sigmoid对每个类提供预测,但在下面的混淆矩阵中的每个单元格中,我显示了存在行中的类且列中不存在的图像的概率平均值(通过应用tensorflow预测的sigmoid函数获得)。这是在验证集图像上应用的。我认为这样可以更详细地了解模型正在学习什么。我只是为了展示目的而圈出了对角线元素。
以下是2个子集的图像数量: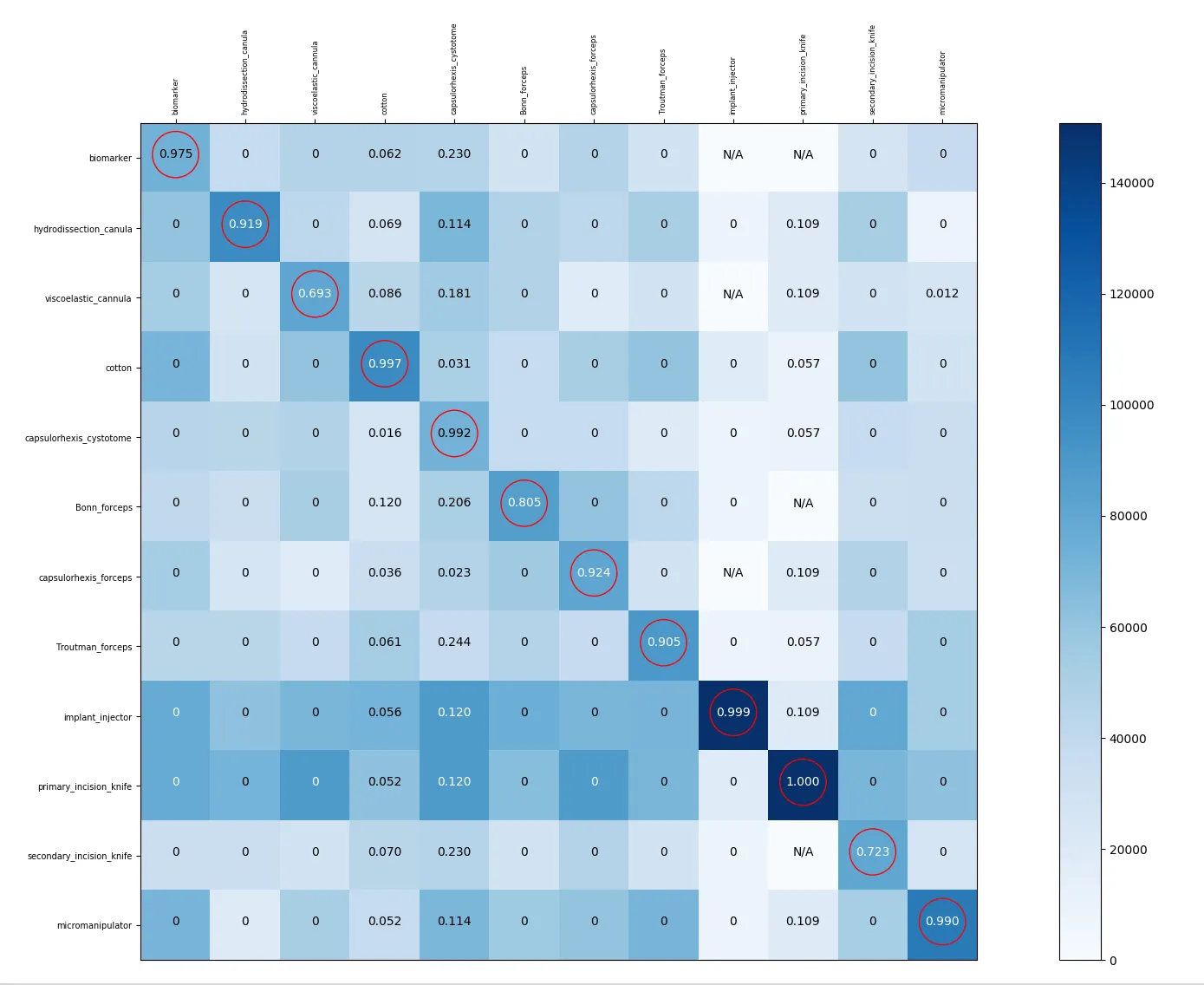 编辑:
为了进行数据增强,我对每个输入图像进行随机平移、旋转和缩放。此外,以下是一些关于工具的信息:
编辑:
为了进行数据增强,我对每个输入图像进行随机平移、旋转和缩放。此外,以下是一些关于工具的信息:
Training Validation
class0 44.4 25
class1 55.6 50
class2 50 25
class3 55.6 50
class4 44.4 50
class5 50 75
class6 50 75
class7 55.6 50
class8 88.9 50
class9 88.9 50
class10 50 25
class11 72.2 25
问题在于模型没有收敛,在验证集上的 ROC 曲线下面积(Az)很差,类似于:
Az
class0 0.99
class1 0.44
class2 0.96
class3 0.9
class4 0.99
class5 0.01
class6 0.52
class7 0.65
class8 0.97
class9 0.82
class10 0.09
class11 0.5
Average 0.65
我不知道为什么有些类表现良好,而其他类则不行。我决定深入了解神经网络学习的细节。我知道混淆矩阵仅适用于二元或多类分类。因此,为了能够绘制它,我必须将问题转换为一系列多类分类。尽管该模型使用sigmoid对每个类提供预测,但在下面的混淆矩阵中的每个单元格中,我显示了存在行中的类且列中不存在的图像的概率平均值(通过应用tensorflow预测的sigmoid函数获得)。这是在验证集图像上应用的。我认为这样可以更详细地了解模型正在学习什么。我只是为了展示目的而圈出了对角线元素。
- 当类别0和4存在时,它们就会被检测到,并且在不存在时不会被检测到。这意味着这些类别被很好地检测到。
- 类别2、6和7总是被检测为不存在。这不是我要找的。
- 类别3、8和9总是被检测为存在。这不是我要找的。此规则也适用于类别11。
- 当类别5不存在时,则被检测为存在,当其存在时,则被检测为不存在。这是一种相反的检测结果。
- 类别3和10:我认为我们不能从这两个类别中提取太多信息。
我的问题是解释...我不确定问题出在哪里,也不确定数据集是否存在偏差导致出现这种结果。我还想知道是否有一些指标可以帮助解决多标签分类问题?您能否与我分享对这样的混淆矩阵的解释?以及接下来要看什么/在哪里寻找?对其他指标的建议也将非常有帮助。
谢谢。
编辑:
我将问题转化为多类分类,对于每一对类别(例如0,1),计算概率(类别0,类别1),表示为p(0,1):
我使用工具1的预测结果来处理存在工具0但不存在工具1的图像,并通过应用sigmoid函数将其转换为概率,然后展示这些概率的平均值。对于p(1,0),我做同样的处理,但现在是针对工具0,使用存在工具1但不存在工具0的图像。对于p(0,0),我使用所有存在工具0的图像。考虑上面图像中的p(0,4),N/A表示不存在工具0存在但不存在工具4存在的图像。以下是2个子集的图像数量:
- 169320张训练图像
- 37440张验证图像
编辑:
为了进行数据增强,我对每个输入图像进行随机平移、旋转和缩放。此外,以下是一些关于工具的信息:class 0 shape is completely different than the other objects.
class 1 resembles strongly to class 4.
class 2 shape resembles to class 1 & 4 but it's always accompanied by an object different than the others objects in the scene. As a whole, it is different than the other objects.
class 3 shape is completely different than the other objects.
class 4 resembles strongly to class 1
class 5 have common shape with classes 6 & 7 (we can say that they are all from the same category of objects)
class 6 resembles strongly to class 7
class 7 resembles strongly to class 6
class 8 shape is completely different than the other objects.
class 9 resembles strongly to class 10
class 10 resembles strongly to class 9
class 11 shape is completely different than the other objects.
编辑后: 以下是下面提出的代码在训练集上的输出:
Avg. num labels per image = 6.892700212615167
On average, images with label 0 also have 6.365296803652968 other labels.
On average, images with label 1 also have 6.601033718926901 other labels.
On average, images with label 2 also have 6.758548914659531 other labels.
On average, images with label 3 also have 6.131520940484937 other labels.
On average, images with label 4 also have 6.219187208527648 other labels.
On average, images with label 5 also have 6.536933407946279 other labels.
On average, images with label 6 also have 6.533908387864367 other labels.
On average, images with label 7 also have 6.485973817793214 other labels.
On average, images with label 8 also have 6.1241642788920725 other labels.
On average, images with label 9 also have 5.94092288040875 other labels.
On average, images with label 10 also have 6.983303518187239 other labels.
On average, images with label 11 also have 6.1974066621953945 other labels.
对于验证集:
Avg. num labels per image = 6.001282051282051
On average, images with label 0 also have 6.0 other labels.
On average, images with label 1 also have 3.987080103359173 other labels.
On average, images with label 2 also have 6.0 other labels.
On average, images with label 3 also have 5.507731958762887 other labels.
On average, images with label 4 also have 5.506459948320414 other labels.
On average, images with label 5 also have 5.00169779286927 other labels.
On average, images with label 6 also have 5.6729452054794525 other labels.
On average, images with label 7 also have 6.0 other labels.
On average, images with label 8 also have 6.0 other labels.
On average, images with label 9 also have 5.506459948320414 other labels.
On average, images with label 10 also have 3.0 other labels.
On average, images with label 11 also have 4.666095890410959 other labels.