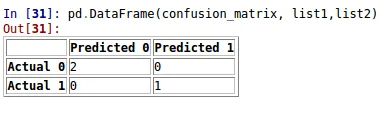
当我打印出scikit-learn的混淆矩阵时,我会收到一个非常巨大的矩阵。我想分析哪些是真正的阳性、真正的阴性等等。我该怎么做呢?这是我的混淆矩阵的样子。我希望更好地理解它。
[[4015 336 0 ..., 0 0 2]
[ 228 2704 0 ..., 0 0 0]
[ 4 7 19 ..., 0 0 0]
...,
[ 3 2 0 ..., 5 0 0]
[ 1 1 0 ..., 0 0 0]
[ 13 1 0 ..., 0 0 11]]