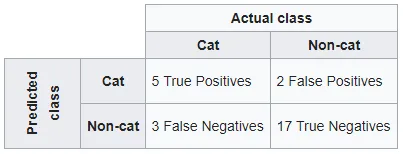
我无法确定是否正确设置了我的二元分类问题。我将正类标记为1,负类标记为0。然而,据我了解,默认情况下scikit-learn在混淆矩阵中使用类别0作为正类(与我的设置相反)。这让我感到困惑。在scikit-learn的默认设置中,顶行是正类还是负类呢?假设混淆矩阵输出如下:
confusion_matrix(y_test, preds)
[ [30 5]
[2 42] ]
在混淆矩阵中会是什么样子?在scikit-learn中,实际实例是行还是列?
prediction prediction
0 1 1 0
----- ----- ----- -----
0 | TN | FP (OR) 1 | TP | FP
actual ----- ----- actual ----- -----
1 | FN | TP 0 | FN | TN