我有一组带已知标签的数据。我想尝试聚类并查看是否可以得到与已知标签相同的聚类。为了衡量准确性,我需要获得类似混淆矩阵的东西。
我知道可以很容易地针对分类问题的测试集获取混淆矩阵。我已经尝试过像这样的方法 this。
然而,它不能用于聚类,因为它期望列和行都具有相同的标签集,这对于分类问题是有意义的。但对于聚类问题,我期望的是像这样的东西。
行-实际标签 列-新的聚类名称(即cluster-1、cluster-2等)
有没有办法做到这一点?
编辑:这里有更多细节。
在sklearn.metrics.confusion_matrix中,它期望
因此,如果我调用
这是一个实际问题。对于分类问题来说,这是有意义的。但对于聚类问题,这个限制不应该存在,因为真实标签名和新聚类名不需要相同。
通过这个,我理解我正在尝试使用一个本应用于分类问题的工具来解决聚类问题。那么,我的问题是,是否有一种方法可以为我的聚类数据获取这样的矩阵。
希望问题现在更清晰了。如果还不清楚,请告诉我。
我知道可以很容易地针对分类问题的测试集获取混淆矩阵。我已经尝试过像这样的方法 this。
然而,它不能用于聚类,因为它期望列和行都具有相同的标签集,这对于分类问题是有意义的。但对于聚类问题,我期望的是像这样的东西。
行-实际标签 列-新的聚类名称(即cluster-1、cluster-2等)
有没有办法做到这一点?
编辑:这里有更多细节。
在sklearn.metrics.confusion_matrix中,它期望
y_test和y_pred具有相同的值,并且labels是这些值的标签。因此,它会给出一个矩阵,其行和列都具有相同的标签,如下所示。
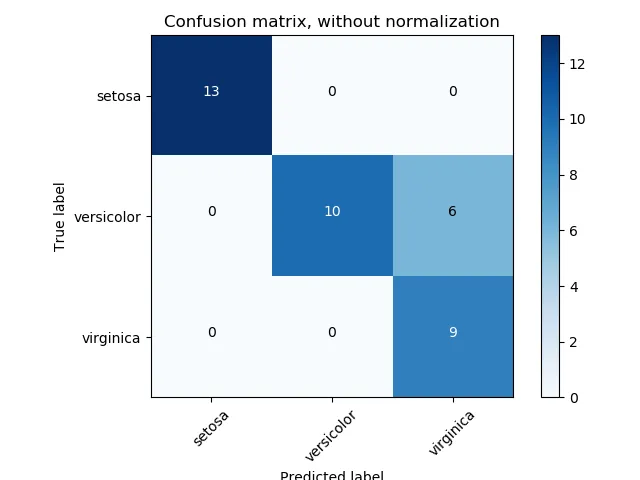
因此,如果我调用
confusion_matrix(y_true, y_pred)会出现以下错误。ValueError: Mix of label input types (string and number)
这是一个实际问题。对于分类问题来说,这是有意义的。但对于聚类问题,这个限制不应该存在,因为真实标签名和新聚类名不需要相同。
通过这个,我理解我正在尝试使用一个本应用于分类问题的工具来解决聚类问题。那么,我的问题是,是否有一种方法可以为我的聚类数据获取这样的矩阵。
希望问题现在更清晰了。如果还不清楚,请告诉我。