如果我理解正确的话,您想要制作一个类似于这里所示
的混淆矩阵。然而,这需要一个可以相互比较的
truth和
prediction。假设您有一个将标题分类为
k组(即
truth)的黄金标准,您可以将其与KMeans聚类(即
prediction)进行比较。
唯一的问题是,KMeans聚类对您的
truth没有任何了解,这意味着它生成的聚类标签将无法与黄金标准组的标签匹配。不过,有一个解决方法,就是基于最佳可能匹配将
kmeans labels匹配到
truth labels上。
以下是这个过程的一个例子。
首先,让我们
生成一些示例数据——在这种情况下,每个样本有50个特征,样本共100个,从4个不同(且略有重叠)的正态分布中抽取。细节并不重要;所有这些都是为了模仿您可能正在使用的数据集类型。在这种情况下,
truth是样本生成自哪个正态分布的均值。
n_samples = 100
n_features = 50
truth = np.empty(n_samples)
data = np.empty((n_samples, n_features))
np.random.seed(42)
for i,mu in enumerate(np.random.choice([0,1,2,3], n_samples, replace=True)):
truth[i] = mu
data[i,:] = np.random.normal(loc=mu, scale=1.5, size=n_features)
plt.imshow(data, interpolation='none')
plt.show()
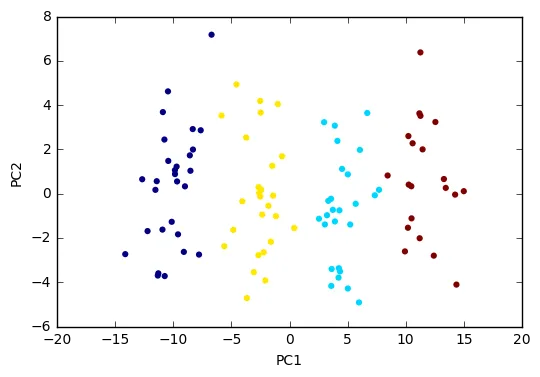
接下来,我们可以应用PCA和KMeans。
需要注意的是,我不确定在您的示例中PCA的确切作用是什么,因为您实际上没有将PC用于KMeans,而且不清楚转换的数据集to_headlines是什么。
在这里,我正在转换输入数据本身,然后使用PC进行KMeans聚类。我还使用输出来说明Saikat Kumar Dey在您的问题中建议的可视化方法:一个散点图,其中点按簇标签着色。
pca = PCA(n_components=2).fit(data)
data2D = pca.transform(data)
km = KMeans(n_clusters=4, init='k-means++', max_iter=300, n_init=3, random_state=0)
km.fit(data2D)
plt.scatter(data2D[:, 0], data2D[:, 1],
c=km.labels_, edgecolor='')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.show()
接下来,我们需要在最初生成的“真实标签”(即样本正态分布的mu值)和聚类生成的“kmeans标签”之间寻找最佳匹配对。
在这个例子中,我简单地使用了最大化真正预测数的匹配方法。 请注意,这是一种简单、快速且不太精确的解决方案!
如果你的预测总体上很好,并且你的数据集中每个组的样本数量相似,它可能会正常工作 - 否则,它可能会产生错误匹配/合并,从而过高地评估你的聚类质量。
欢迎提出更好的解决方案。
k_labels = km.labels_
k_labels_matched = np.empty_like(k_labels)
for k in np.unique(k_labels):
match_nums = [np.sum((k_labels==k)*(truth==t)) for t in np.unique(truth)]
k_labels_matched[k_labels==k] = np.unique(truth)[np.argmax(match_nums)]
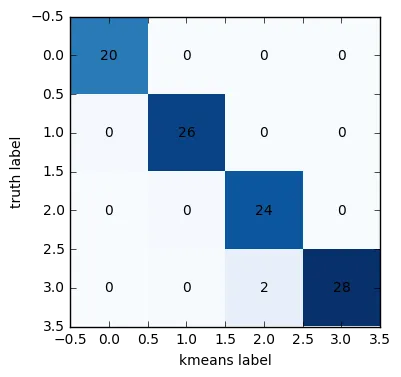
现在我们已经匹配了 真实值 和 预测结果,我们终于可以计算并绘制混淆矩阵了。
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(truth, k_labels_matched)
plt.imshow(cm,interpolation='none',cmap='Blues')
for (i, j), z in np.ndenumerate(cm):
plt.text(j, i, z, ha='center', va='center')
plt.xlabel("kmeans label")
plt.ylabel("truth label")
plt.show()
希望这个能帮到你!