我想基于我拥有的样本绘制概率密度函数的近似值,使曲线模仿直方图的行为。我可以有任意多的样本。
使用Matplotlib根据样本绘制概率密度函数
30
- Cupitor
7
1我不明白为什么有人会对这个问题投反对票?!我的意思是基于什么??? - Cupitor
2通常在[SO]上,人们会点赞那些问题立即清晰明了,并且提问者尝试回答自己问题的问题。 "你尝试过什么?" 通常情况下,踩的同时也会附带评论,所以我不确定为什么这种情况没有发生。 - askewchan
我明白了,谢谢你的解释。有时候这些事情让我觉得民主制度很糟糕! - Cupitor
嘿,是的。[FAQ]对于概述人们对问题的期望(以及不期望)非常有用。除了“声誉”之外,更多的赞同将使您的问题获得更多的可见性和关注。 - askewchan
解决了我的问题。 - Toma
显示剩余2条评论
2个回答
43
如果您想绘制一个已知的分布,将其定义为函数,然后按如下方式绘制: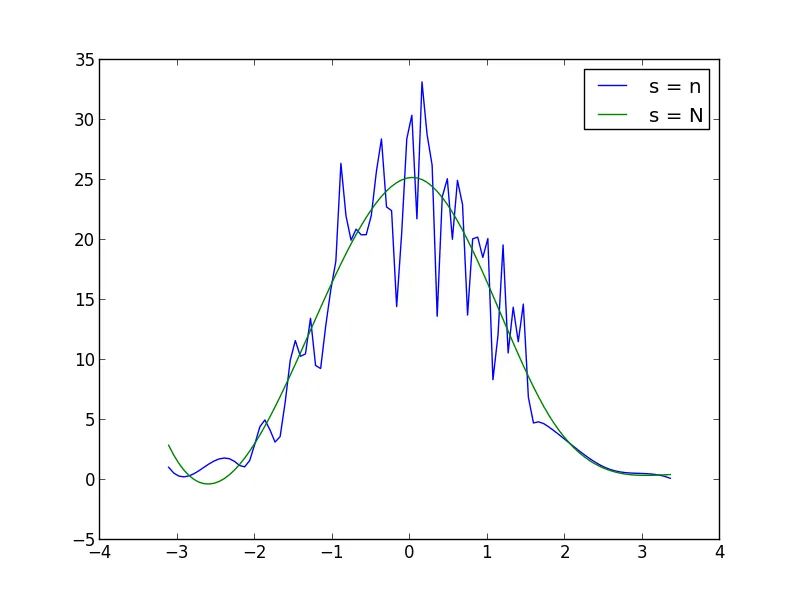
import numpy as np
from matplotlib import pyplot as plt
def my_dist(x):
return np.exp(-x ** 2)
x = np.arange(-100, 100)
p = my_dist(x)
plt.plot(x, p)
plt.show()
如果你没有精确分布的解析函数,也许可以生成大样本,绘制直方图并对数据进行某种平滑处理:
import numpy as np
from scipy.interpolate import UnivariateSpline
from matplotlib import pyplot as plt
N = 1000
n = N//10
s = np.random.normal(size=N) # generate your data sample with N elements
p, x = np.histogram(s, bins=n) # bin it into n = N//10 bins
x = x[:-1] + (x[1] - x[0])/2 # convert bin edges to centers
f = UnivariateSpline(x, p, s=n)
plt.plot(x, f(x))
plt.show()
UnivariateSpline函数调用中增加或减少s(平滑因子)来增加或减少平滑度。例如,使用下面这两个:
- askewchan
9
这对我的情况没有帮助。我已经编写了我的采样函数,但对于样本大小为1的情况并不准确! - Cupitor
1@Naji 抱歉,现在应该可以工作了,并提供一个正态分布的工作示例。 - askewchan
我仍然收到以下错误:
f = UnivariateSpline(x, 0.5, s=200)
File "/Library/Python/2.7/site-packages/scipy/interpolate/fitpack2.py", line 143,在__init__中
xb=bbox[0],xe=bbox[1],s=s)
dfitpack.error: 在将dfitpack.fpcurf0的第二个参数“y”转换为C / Fortran数组时失败 - Cupitor
1你应该使用 n = int(N/10) 来避免浮点类型的错误。 - Ajay Ohri
1不错的点子 @Ajay,我应该更新一下!五年前我写这篇文章时,
n 是一个 int,因为我在使用 Python 2,而且大多数读者可能也是如此。 - askewchan显示剩余4条评论
29
你需要做的是使用scipy.stats.kde包中的gaussian_kde函数。
根据你的数据,你可以像这样操作:
from scipy.stats.kde import gaussian_kde
from numpy import linspace
# create fake data
data = randn(1000)
# this create the kernel, given an array it will estimate the probability over that values
kde = gaussian_kde( data )
# these are the values over wich your kernel will be evaluated
dist_space = linspace( min(data), max(data), 100 )
# plot the results
plt.plot( dist_space, kde(dist_space) )
核密度可以随意配置,能够轻松处理N维数据,同时避免了由askewchan给出的图中看到的样条畸变。
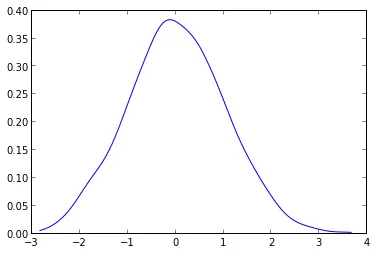
- EnricoGiampieri
2
我正在寻找类似的解决方案。我已经有了一个数据集,但是我不知道它具有什么分布,因此我正在尝试使用Python绘制概率分布函数,但我不知道如何绘制。如果有任何帮助,将不胜感激。 - Sitz Blogz
2@SitzBlogz 假设你的数据集叫做
data,那么只需删除 @EnricoGiampieri 的答案中的一行 data = randn(1000),你就完成了! - Alessandro Jacopson网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接