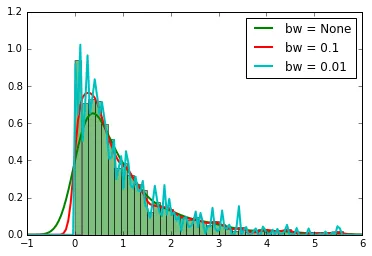
我有一个数据值的数组,如下:
0.000000000000000000e+00
3.617000000000000171e+01
1.426779999999999973e+02
2.526699999999999946e+01
4.483190000000000168e+02
7.413999999999999702e+00
1.132390000000000043e+02
8.797000000000000597e+00
1.362599999999999945e+01
2.080880900000000111e+04
5.580000000000000071e+00
3.947999999999999954e+00
2.615000000000000213e+00
2.458000000000000185e+00
8.204600000000000648e+01
1.641999999999999904e+00
5.108999999999999986e+00
2.388999999999999790e+00
2.105999999999999872e+00
5.783000000000000362e+00
4.309999999999999609e+00
3.685999999999999943e+00
6.339999999999999858e+00
2.198999999999999844e+00
3.568999999999999950e+00
2.883999999999999897e+00
7.307999999999999829e+00
2.515000000000000124e+00
3.810000000000000053e+00
2.829000000000000181e+00
2.593999999999999861e+00
3.963999999999999968e+00
7.258000000000000007e+00
3.543000000000000149e+00
2.874000000000000110e+00
................... and so on.
我希望绘制数据值的概率密度函数。我参考了(维基百科)和scipy.stats.gaussian_kde,但我不确定是否正确。我正在使用Python。简单的数据绘图代码如下:
from matplotlib import pyplot as plt
plt.plot(Data)
但是现在我想绘制概率密度函数(PDF)。但是我在Python中找不到任何库来实现这一点。