我开始使用Python进行分析。我希望能够完成以下任务:
- 获取数据集的分布
- 获取分布中的峰值
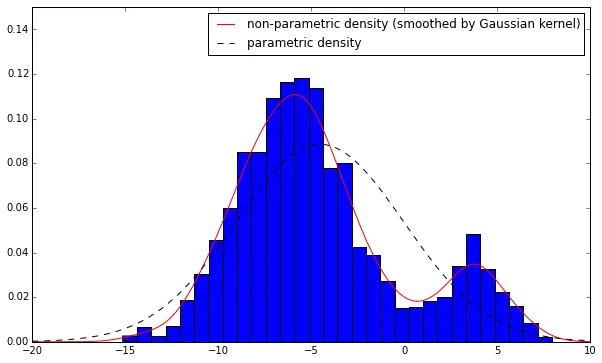
我使用scipy.stats中的gaussian_kde来估计核密度函数。gaussian_kde对数据做出了什么样的假设吗?我正在使用随时间改变的数据,因此如果数据有一个分布(例如高斯分布),它可能会在以后有另一个分布。在这种情况下,gaussian_kde有什么缺点吗?在此问题中建议尝试将数据拟合到每个分布中以获取数据分布。那么使用gaussian_kde和该问题中提供的答案有什么区别?我使用了下面的代码,我想知道如果数据会随时间变化,使用gaussian_kde估计pdf是否是一种好方法?我知道gaussian_kde的一个优势是可以根据经验法则自动计算带宽,如这里所述。另外,如何获取它的峰值?
import pandas as pd
import numpy as np
import pylab as pl
import scipy.stats
df = pd.read_csv('D:\dataset.csv')
pdf = scipy.stats.kde.gaussian_kde(df)
x = np.linspace((df.min()-1),(df.max()+1), len(df))
y = pdf(x)
pl.plot(x, y, color = 'r')
pl.hist(data_column, normed= True)
pl.show(block=True)