我知道statsmodels.tools.tools.ECDF,但由于经验累积分布函数(ECDF)的计算非常直观,而且我希望在项目中尽量减少依赖关系,因此我想手动编写代码。
在给定的list() / np.array() Pandas.Series中,可以按照维基百科中所述计算每个元素的ECDF:
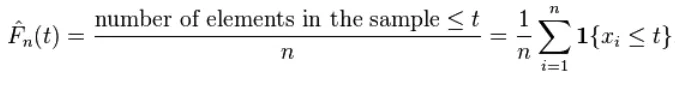
我有下面的Pandas DataFrame dfser,我想获得values列的ECDF。我的两个一行代码解决方案也已给出。
是否有更快的方法?在我的应用程序中速度很重要。
# Note that in my case indices are unique identifiers so I cannot reset them.
import numpy as np
import pandas as pd
# all indices are unique, but there may be duplicate measurement values (that belong to different indices).
dfser = pd.DataFrame({'group':['a','b','b','a','d','c','e','e','c','a','b','d','d','c','d','e','e','a'],
'values':[2.01899E-06, 1.12186E-07, 8.97467E-07, 2.91257E-06, 1.93733E-05,
0.00017889, 0.000120963, 4.27643E-07, 3.33614E-07, 2.08352E-12,
1.39478E-05, 4.28255E-08, 9.7619E-06, 8.51787E-09, 1.28344E-09,
3.5063E-05, 0.01732035,2.08352E-12]},
index = [123, 532, 235, 645, 747, 856, 345, 245, 845, 248, 901, 712, 162, 126,
198,748, 127,395] )
# My 1st Solution - list comprehension
dfser['ecdf']=[sum( dfser['values'] <= x)/float(dfser['values'].size) for x in dfser['values']]
# My 2nd Solution - ranking
dfser['rank'] = dfser['values'].rank(ascending = 0)
dfser['ecdf_r']=(len(dfser)-dfser['rank']+1)/len(dfser)
dfser
group values ecdf rank ecdf_r
123 a 2.018990e-06 0.555556 9.0 0.555556
532 b 1.121860e-07 0.333333 13.0 0.333333
235 b 8.974670e-07 0.500000 10.0 0.500000
645 a 2.912570e-06 0.611111 8.0 0.611111
747 d 1.937330e-05 0.777778 5.0 0.777778
856 c 1.788900e-04 0.944444 2.0 0.944444
345 e 1.209630e-04 0.888889 3.0 0.888889
245 e 4.276430e-07 0.444444 11.0 0.444444
845 c 3.336140e-07 0.388889 12.0 0.388889
248 a 2.083520e-12 0.111111 17.5 0.083333
901 b 1.394780e-05 0.722222 6.0 0.722222
712 d 4.282550e-08 0.277778 14.0 0.277778
162 d 9.761900e-06 0.666667 7.0 0.666667
126 c 8.517870e-09 0.222222 15.0 0.222222
198 d 1.283440e-09 0.166667 16.0 0.166667
748 e 3.506300e-05 0.833333 4.0 0.833333
127 e 1.732035e-02 1.000000 1.0 1.000000
395 a 2.083520e-12 0.111111 17.5 0.083333
np.arange(1, ser.size+1)/float(ser.size)这样的代码将会给出与你计算的相同累积分布函数。 - cc7768