是否可能区分ECDF?以以下示例中获得的为例。
set.seed(1)
a <- sort(rnorm(100))
b <- ecdf(a)
plot(b)

我希望对b进行求导,以获得其概率密度函数(PDF)。
是否可能区分ECDF?以以下示例中获得的为例。
set.seed(1)
a <- sort(rnorm(100))
b <- ecdf(a)
plot(b)
我希望对b进行求导,以获得其概率密度函数(PDF)。
n <- length(a) ## `a` must be sorted in non-decreasing order already
plot(a, 1:n / n, type = "s") ## "staircase" plot; not "line" plot
但我正在寻找b的导数
在基于样本的统计学中,对于连续随机变量的估计密度并不是通过对ECDF进行微分得到的,因为样本大小是有限的而且ECDF不可微。相反,我们直接估计密度。我猜您真正需要的是plot(density(a))。
几天后..
我将其视为练习学习R软件包scam用于形状约束加性模型,这是Wood教授早期博士生Pya博士的子软件包。
逻辑如下:
scam::scam,对ECDF拟合单调递增的P样条(您必须指定想要的结节点数); [请注意,单调性不是唯一的理论限制。需要对平滑的ECDF进行"剪裁",即在两个边缘上剪裁:在0处的左边缘和在1处的右边缘。 我目前使用weights来施加这种约束,通过在两个边缘处给予非常大的权重]stats::splinefun,通过节点和结节点预测值拟合单调插值样条;为什么我希望这能够工作:
随着样本大小增长,
请小心使用:
函数参数:
x:样本向量;n.knots:结节点数量;n.cells:绘制导数函数时网格点的数量您需要从CRAN安装scam软件包。
library(scam)
test <- function (x, n.knots, n.cells) {
## get ECDF
n <- length(x)
x <- sort(x)
y <- 1:n / n
dat <- data.frame(x = x, y = y) ## make sure `scam` can find `x` and `y`
## fit a monotonically increasing P-spline for ECDF
fit <- scam::scam(y ~ s(x, bs = "mpi", k = n.knots), data = dat,
weights = c(n, rep(1, n - 2), 10 * n))
## interior knots
xk <- with(fit$smooth[[1]], knots[4:(length(knots) - 3)])
## spline values at interior knots
yk <- predict(fit, newdata = data.frame(x = xk))
## reparametrization into a monotone interpolation spline
f <- stats::splinefun(xk, yk, "hyman")
par(mfrow = c(1, 2))
plot(x, y, pch = 19, col = "gray") ## ECDF
lines(x, f(x), type = "l") ## smoothed ECDF
title(paste0("number of knots: ", n.knots,
"\neffective degree of freedom: ", round(sum(fit$edf), 2)),
cex.main = 0.8)
xg <- seq(min(x), max(x), length = n.cells)
plot(xg, f(xg, 1), type = "l") ## density estimated by scam
lines(stats::density(x), col = 2) ## a proper density estimate by density
## return smooth ECDF function
f
}
## try large sample size
set.seed(1)
x <- rnorm(1000)
f <- test(x, n.knots = 20, n.cells = 100)
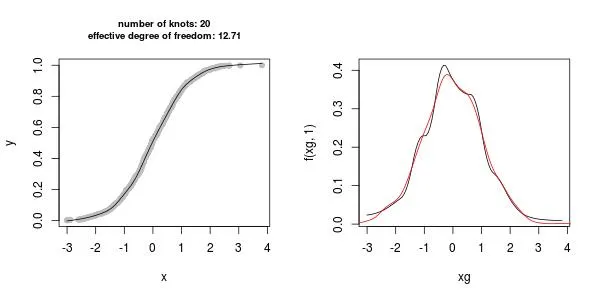
f 是由stats::splinefun返回的函数(请阅读 ?splinefun)。
一种简单的类似解决方案是在ECDF上进行插值样条,而不进行平滑处理。但这是一个非常糟糕的想法,因为我们没有一致性。
g <- splinefun(sort(x), 1:length(x) / length(x), method = "hyman")
curve(g(x, deriv = 1), from = -3, to = 3)
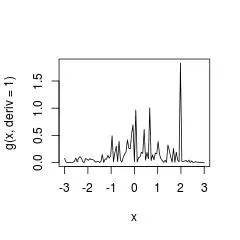
提醒:强烈建议使用stats::density进行直接密度估计。
stats::density会平滑这些结构,并且通常这个函数有很多内部设置,让我对所表示的内容感到不舒服。因此,你所说的“直接密度估计”是基本上得到你的分布的大致想法吗? - algae