我有以下数据点需要进行曲线拟合:
import matplotlib.pyplot as plt
import numpy as np
from scipy.optimize import curve_fit
t = np.array([15474.6, 15475.6, 15476.6, 15477.6, 15478.6, 15479.6, 15480.6,
15481.6, 15482.6, 15483.6, 15484.6, 15485.6, 15486.6, 15487.6,
15488.6, 15489.6, 15490.6, 15491.6, 15492.6, 15493.6, 15494.6,
15495.6, 15496.6, 15497.6, 15498.6, 15499.6, 15500.6, 15501.6,
15502.6, 15503.6, 15504.6, 15505.6, 15506.6, 15507.6, 15508.6,
15509.6, 15510.6, 15511.6, 15512.6, 15513.6])
v = np.array([4.082, 4.133, 4.136, 4.138, 4.139, 4.14, 4.141, 4.142, 4.143,
4.144, 4.144, 4.145, 4.145, 4.147, 4.146, 4.147, 4.148, 4.148,
4.149, 4.149, 4.149, 4.15, 4.15, 4.15, 4.151, 4.151, 4.152,
4.152, 4.152, 4.153, 4.153, 4.153, 4.153, 4.154, 4.154, 4.154,
4.154, 4.154, 4.155, 4.155])
我想要拟合到数据的指数函数是:
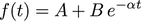
def func(t, a, b, alpha):
return a - b * np.exp(-alpha * t)
# scale vector to start at zero otherwise exponent is too large
t_scale = t - t[0]
# initial guess for curve fit coefficients
a0 = v[-1]
b0 = v[0]
alpha0 = 1/t_scale[-1]
# coefficients and curve fit for curve
popt4, pcov4 = curve_fit(func, t_scale, v, p0=(a0, b0, alpha0))
a, b, alpha = popt4
v_fit = func(t_scale, a, b, alpha)
ss_res = np.sum((v - v_fit) ** 2) # residual sum of squares
ss_tot = np.sum((v - np.mean(v)) ** 2) # total sum of squares
r2 = 1 - (ss_res / ss_tot) # R squared fit, R^2
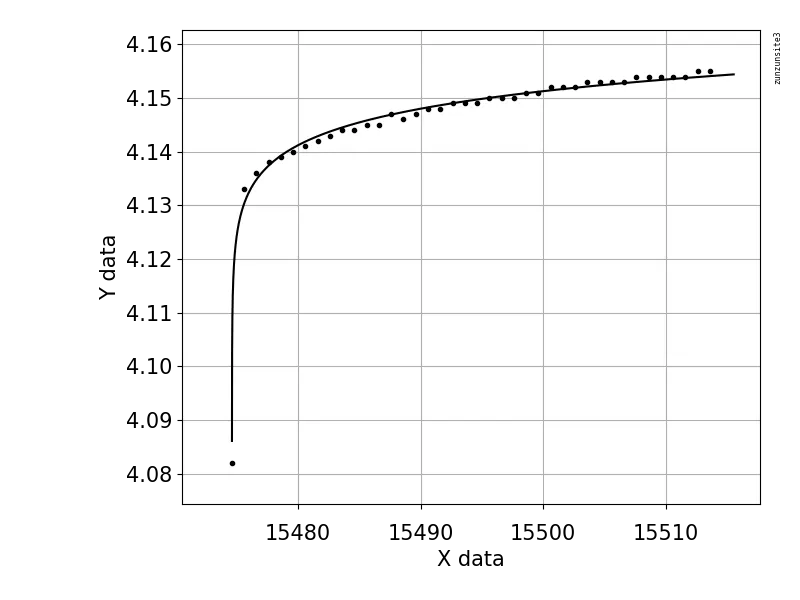
以下是与曲线拟合相比的数据绘图。还提供了参数和R平方值。
a0 = 4.1550 b0 = 4.0820 alpha0 = 0.0256
a = 4.1490 b = 0.0645 alpha = 0.9246
R² = 0.8473
使用上述方法能否更好地拟合数据,还是需要使用不同形式的指数方程?
我也不确定初始值(a0、b0、alpha0)应该使用什么。在示例中,我选择了数据点,但这可能不是最佳方法。有没有关于曲线拟合系数的初始猜测的建议?
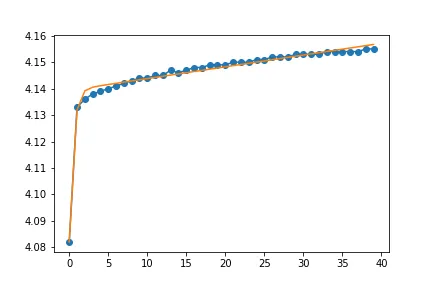
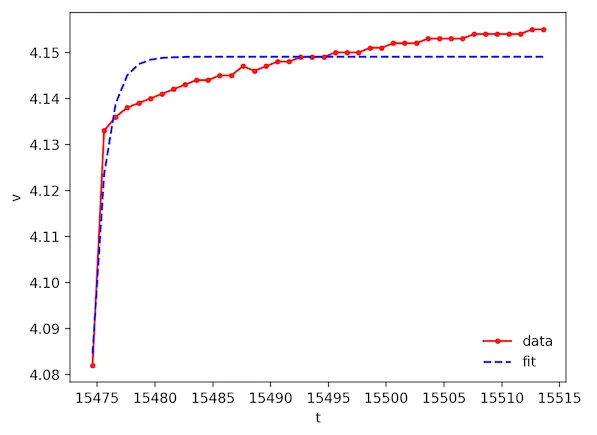
curve_fit的sigma参数来实现。 - dan_gsigma这个关键字。我该如何在我的例子中应用它?另外,从峰值开始曲线拟合(t[1:]和v[1:])效果很好,但这会对popt值产生多大影响呢? - wigging