我有一些放射性衰变数据,包括x和y两个方向的误差。图形本身已经准备好使用,但我需要绘制指数衰变曲线并从适配结果中返回报告,以找到半衰期和减少的卡方值。
图形的代码如下:
fig, ax = plt.subplots(figsize=(14, 8))
ax.errorbar(ts, amps, xerr=2, yerr=sqrt(amps), fmt="ko-", capsize = 5, capthick= 2, elinewidth=3, markersize=5)
plt.xlabel('Time /s', fontsize=14)
plt.ylabel('Counts Recorded in the Previous 15 seconds', fontsize=16)
plt.title("Decay curve of P-31 by $β^+$ emission", fontsize=16)
我使用的模型(诚然,在编程方面我不是很自信)是:
def expdecay(x, t, A):
return A*exp(-x/t)
decayresult = emodel.fit(amps, x=ts, t=150, A=140)
ax.plot(ts, decayresult.best_fit, 'r-', label='best fit')
print(decayresult.fit_report())
但我认为这并没有考虑到不确定性,只是将其绘制在图表上。我希望它能拟合指数衰减曲线,考虑到不确定性,并返回半衰期(在本例中为t)以及它们各自的不确定性和降低的卡方。
类似下面图片的目标,但考虑到拟合中的不确定性:
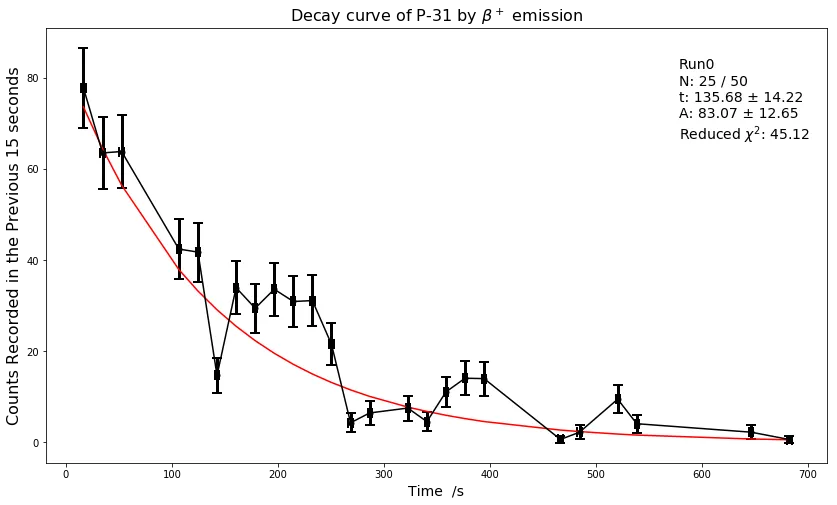
使用weight=1/sqrt(amps)建议和完整数据集,得到:
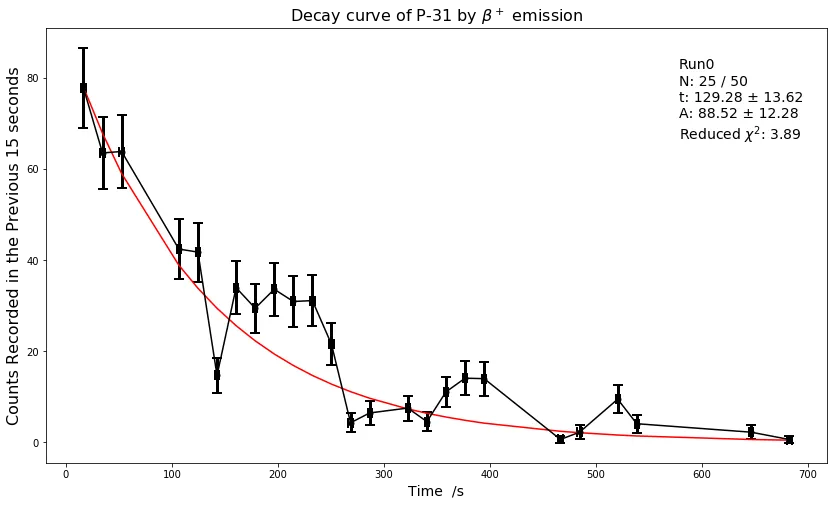
我想,这可能是从这些数据中得到的最佳拟合(降低的卡方值为3.89)。我希望它能给我t = 150s,但这取决于实验。感谢大家的帮助。
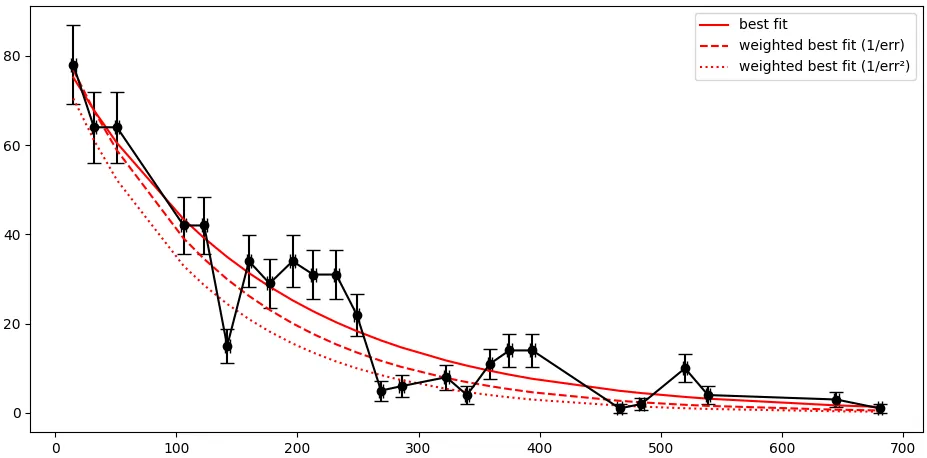
weights = 1/yerr,其中yerr是一个带有不确定性的 numpy 数组,但如果像你的示例一样使用yerr = sqrt(amps),我猜你不会得到太大的改进。 - Steflmfit并不是很直观。我对这个库不是很熟悉,但也许@m-newville可以帮助你。然而,正如Stef所说,从你发布的图像来看,你不能期望从加权拟合中得到太多。原始数据非常嘈杂,拟合看起来还算不错。 - Mr. Tweights=1.0/yerr是完全正确的。而且,是的,这意味着给予具有非常低不确定性的数据点更重要的重视,而对具有高不确定性的数据点给予较少的重视。这正是您想要的 - 您对具有低不确定性的值更加确定。 - M Newville