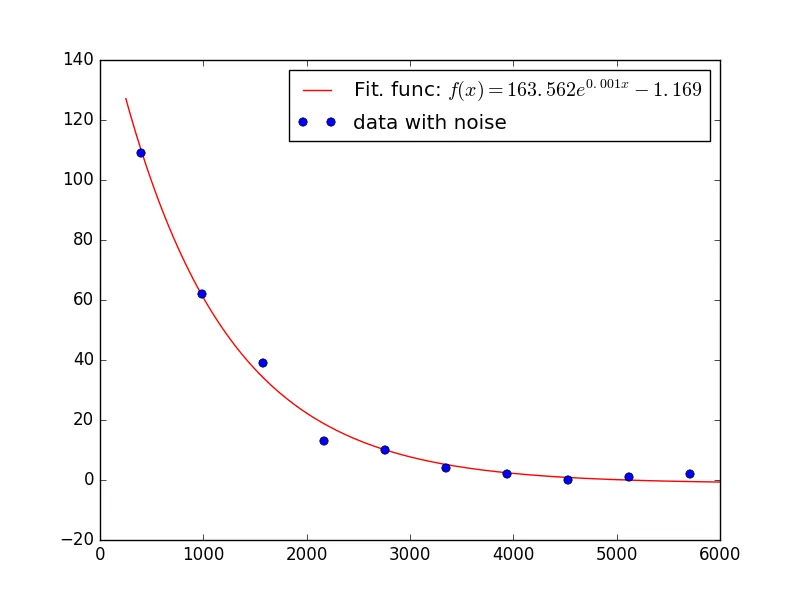
我知道这方面有相关的讨论帖子,但是我不确定我应该将我的数据拟合到哪里。我的数据被导入并绘制如下。
如果可能的话,我还希望将拟合的衰减方程式与图形一起显示。但是,如果能够产生合适的拟合,则可以轻松应用此功能。
编辑-------------------------------------------------------------
因此,在使用Stanely R提到的拟合函数时
import matplotlib.pyplot as plt
%matplotlib inline
import pylab as plb
import numpy as np
import scipy as sp
import csv
FreqTime1 = []
DecayCount1 = []
with open('Half_Life.csv', 'r') as f:
reader = csv.reader(f, delimiter=',')
for row in reader:
FreqTime1.append(row[0])
DecayCount1.append(row[3])
FreqTime1 = np.array(FreqTime1)
DecayCount1 = np.array(DecayCount1)
fig1 = plt.figure(figsize=(15,6))
ax1 = fig1.add_subplot(111)
ax1.plot(FreqTime1,DecayCount1, ".", label = 'Run 1')
ax1.set_xlabel('Time (sec)')
ax1.set_ylabel('Count')
plt.legend()
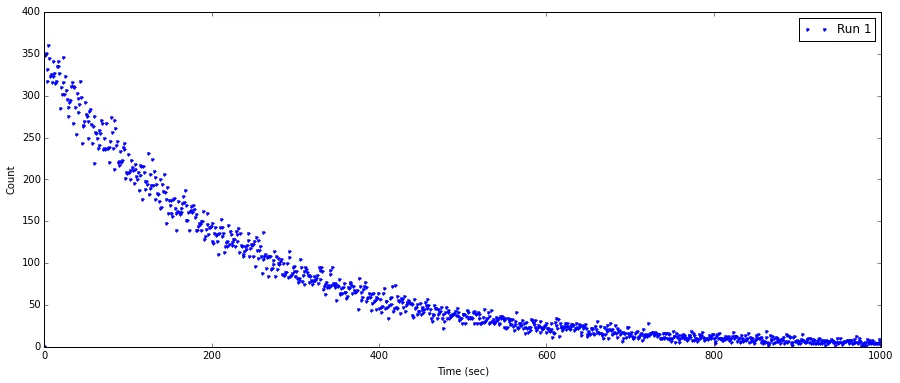
如果可能的话,我还希望将拟合的衰减方程式与图形一起显示。但是,如果能够产生合适的拟合,则可以轻松应用此功能。
编辑-------------------------------------------------------------
因此,在使用Stanely R提到的拟合函数时
def model_func(x, a, k, b):
return a * np.exp(-k*x) + b
x = FreqTime1
y = DecayCount1
p0 = (1.,1.e-5,1.)
opt, pcov = curve_fit(model_func, x, y, p0)
a, k, b = opt
我遇到了这个错误信息:
TypeError: 函数 'multiply' 没有匹配类型为 dtype('S32') dtype('S32') dtype('S32') 的循环
你有什么解决办法吗?