使用matplotlib,我可以在一个图上绘制两个数据集的直方图(一个紧挨着另一个,而不是重叠)。
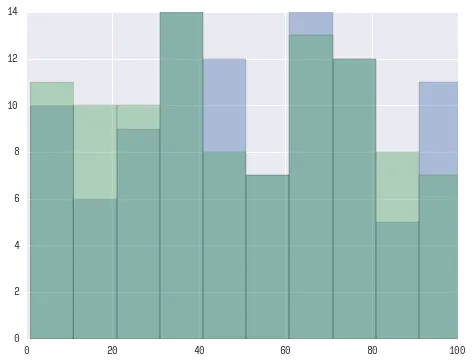
这产生了以下的图表。
我遇到了以下错误:
所以我尝试添加一些颜色数值:
我遇到了同样的错误。我看到了关于如何叠加图形的这篇帖子,但我想要这些直方图并排显示,而不是叠加在一起。
同时,根据文档,它没有明确说明如何将一个列表的列表作为第一个参数'a'进行包含。
我该如何使用seaborn实现这种直方图的样式呢?
import matplotlib.pyplot as plt
import random
x = [random.randrange(100) for i in range(100)]
y = [random.randrange(100) for i in range(100)]
plt.hist([x, y])
plt.show()
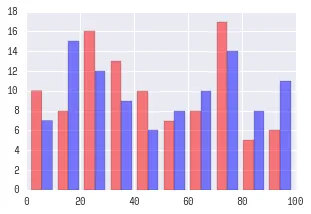
这产生了以下的图表。

import seaborn as sns
sns.distplot([x, y])
我遇到了以下错误:
ValueError: color kwarg must have one color per dataset
所以我尝试添加一些颜色数值:
sns.distplot([x, y], color=['r', 'b'])
我遇到了同样的错误。我看到了关于如何叠加图形的这篇帖子,但我想要这些直方图并排显示,而不是叠加在一起。
同时,根据文档,它没有明确说明如何将一个列表的列表作为第一个参数'a'进行包含。
我该如何使用seaborn实现这种直方图的样式呢?
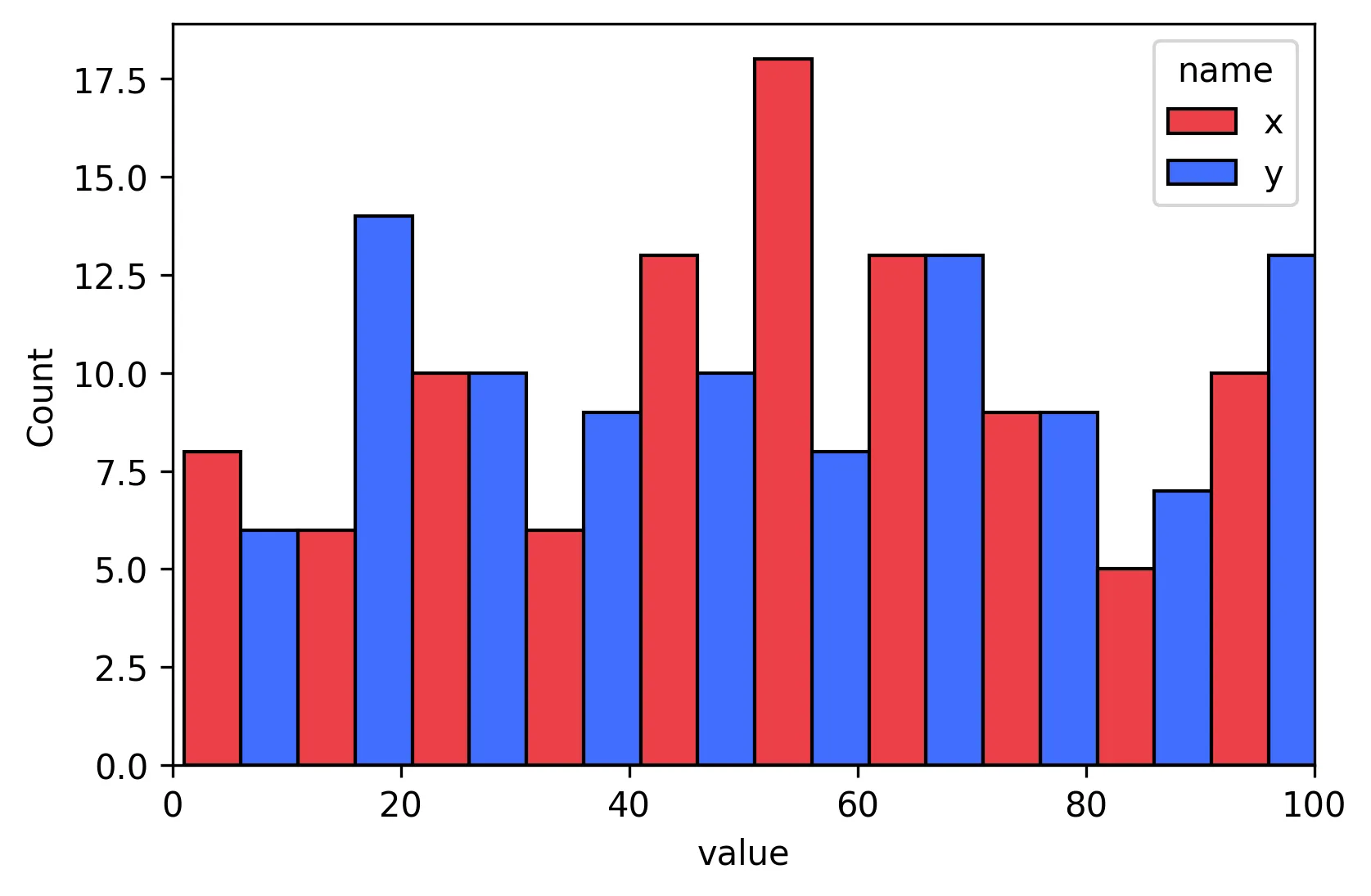
plt.hist()之前导入seaborn包是否有特别的原因? - jgladseaborn的原因是为了获得 "seaborn look"(在导入时,它会将自己的样式应用于matplotlib样式表)。还要注意最近版本的seaborn(需要额外的命令)。我已经更新了答案以反映这一点。 - Primer