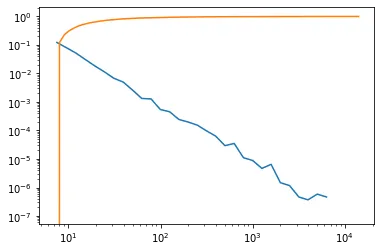
我正在考虑《白鲸记》小说中独特单词出现次数,并使用
我不确定为什么我无法复制Clauset等人之前的工作结果,因为p值和KS得分都很“差”。
这个想法是将独特单词的频率拟合成幂律分布。然而,由
我有以下函数将数据拟合到幂律分布上:
结果:
当我比较期望结果并在相同的Moby Dick数据集上遵循这个 R教程时,我得到了一个不错的p值和KS检验值:
powerlaw Python包将单词频率拟合到幂律分布上。我不确定为什么我无法复制Clauset等人之前的工作结果,因为p值和KS得分都很“差”。
这个想法是将独特单词的频率拟合成幂律分布。然而,由
scipy.stats.kstest计算的Kolmogorov-Smirnov拟合优度检验看起来很糟糕。我有以下函数将数据拟合到幂律分布上:
import numpy as np
import powerlaw
import scipy
from scipy import stats
def fit_x(x):
fit = powerlaw.Fit(x, discrete=True)
alpha = fit.power_law.alpha
xmin = fit.power_law.xmin
print('powerlaw', scipy.stats.kstest(x, "powerlaw", args=(alpha, xmin), N=len(x)))
print('lognorm', scipy.stats.kstest(x, "lognorm", args=(np.mean(x), np.std(x)), N=len(x)))
下载赫尔曼·梅尔维尔(Herman Melville)小说《白鲸》中独特单词的频率(根据Aaron Clauset等人的说法,应该遵循幂律分布):
wget http://tuvalu.santafe.edu/~aaronc/powerlaws/data/words.txt
Python脚本:
x = np.loadtxt('./words.txt')
fit_x(x)
结果:
结果:
('powerlaw', KstestResult(statistic=0.862264651286131, pvalue=0.0))
('log norm', KstestResult(statistic=0.9910368602492707, pvalue=0.0))
当我比较期望结果并在相同的Moby Dick数据集上遵循这个 R教程时,我得到了一个不错的p值和KS检验值:
library("poweRlaw")
data("moby", package="poweRlaw")
m_pl = displ$new(moby)
est = estimate_xmin(m_pl)
m_pl$setXmin(est)
bs_p = bootstrap_p(m_pl)
bs_p$p
## [1] 0.6738
当计算KS检验值并通过powerlaw Python库进行后处理时,我可能会错过什么?PDF和CDF看起来没问题,但KS检验结果似乎有误。