我想知道我的数据点分布情况,所以首先绘制了数据的直方图。我的直方图如下所示:
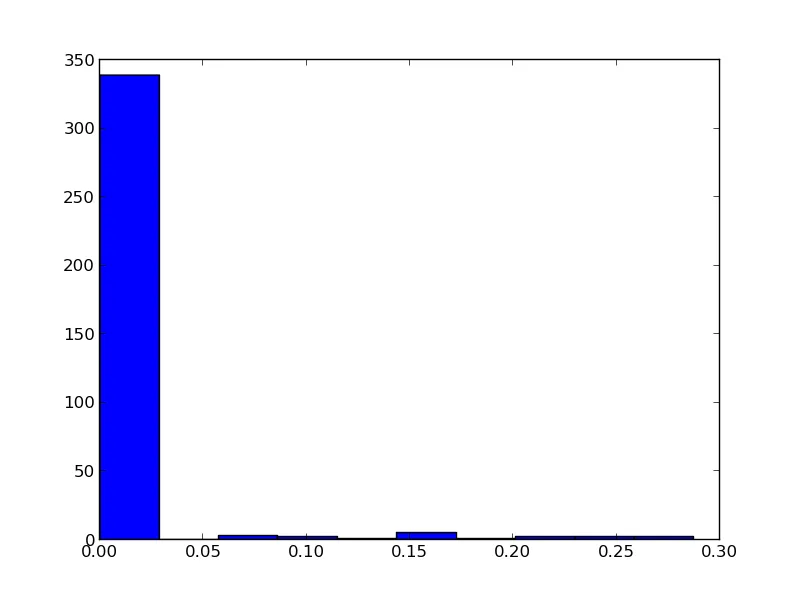 其次,为了将它们拟合到一个分布上,我编写了以下代码:
其次,为了将它们拟合到一个分布上,我编写了以下代码:
结果如下:
其次,为了将它们拟合到一个分布上,我编写了以下代码:size = 20000
x = scipy.arange(size)
# fit
param = scipy.stats.gamma.fit(y)
pdf_fitted = scipy.stats.gamma.pdf(x, *param[:-2], loc = param[-2], scale = param[-1]) * size
plt.plot(pdf_fitted, color = 'r')
# plot the histogram
plt.hist(y)
plt.xlim(0, 0.3)
plt.show()
结果如下:
结果为:
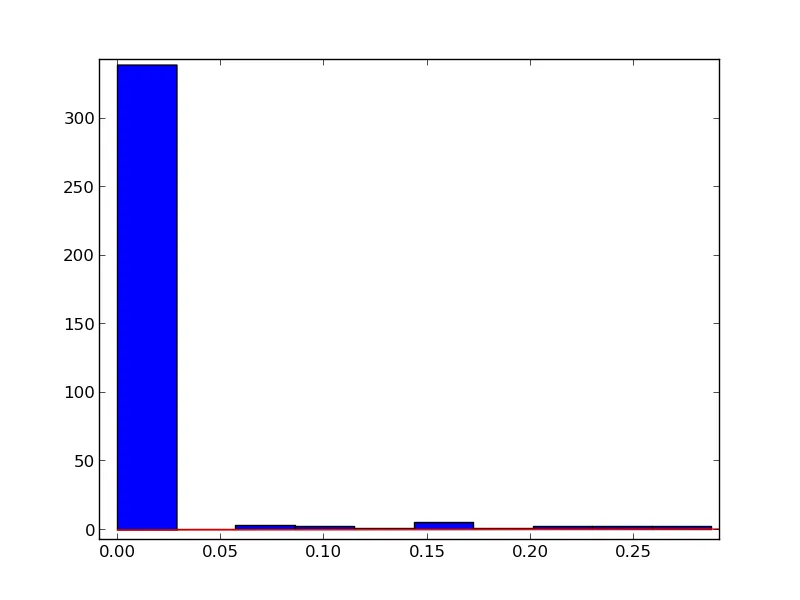
我做错了什么?
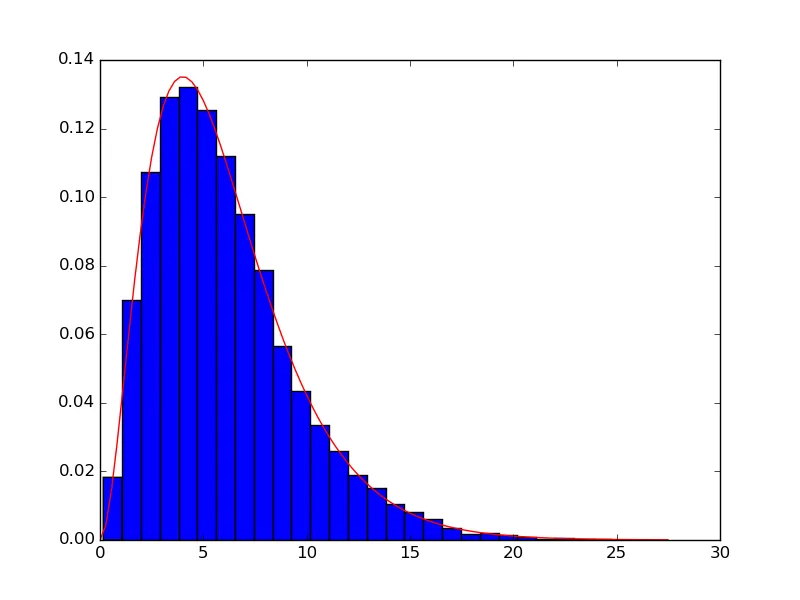
loc参数不会被使用(即 PDF 不应该被移动),并且该值被固定为 0。默认情况下,fit方法将loc视为拟合参数,因此您可能会得到一个小的非零偏移量--请检查fit返回的参数。您可以通过使用参数floc=0告诉fit不要将loc包括在拟合参数中。 - Warren Weckessera=param[0]是形状参数,而theta=param[2]是尺度参数,我们如何对它们进行重新归一化,使得得到的概率密度函数是标准化的呢?(我们是否可以在gamma.fit()中包含某些参数,以便得到的概率密度函数是标准化的?)(为了测试当前是否未标准化,sum(pdf_fitted)不等于1)我通过乘以np.diff(bins)[0]来修复它。 - user6039682f(x)=C*exp(a*x+b*x^2+c*x^4+d*x^8))来完成相同的拟合,而不是使用伽马分布? - CyberMathIdiot