您已经拥有对数正态分布的众数和标准差。要使用scipy的lognorm的rvs()方法,您需要以形状参数s为代价来参数化分布,该参数是底层正态分布的标准差sigma,并且scale是exp(mu),其中mu是底层分布的平均值。
您指出进行这种重新参数化需要解决一个四次多项式方程。为此,我们可以使用numpy.poly1d类。该类的实例具有根属性。
一些代数运算表明,exp(sigma**2)是该多项式的唯一正实根。
x**4 - x**3 - (stddev/mode)**2 = 0
其中stddev和mode是对数正态分布的给定标准差和众数,对于此解决方案,scale(即exp(mu))为
scale = mode*x
以下是一个将模式和标准差转换为形状和尺度的函数:
def lognorm_params(mode, stddev):
"""
Given the mode and std. dev. of the log-normal distribution, this function
returns the shape and scale parameters for scipy's parameterization of the
distribution.
"""
p = np.poly1d([1, -1, 0, 0, -(stddev/mode)**2])
r = p.roots
sol = r[(r.imag == 0) & (r.real > 0)].real
shape = np.sqrt(np.log(sol))
scale = mode * sol
return shape, scale
例如,
In [155]: mode = 123
In [156]: stddev = 99
In [157]: sigma, scale = lognorm_params(mode, stddev)
使用计算出的参数生成一个样本:
In [158]: from scipy.stats import lognorm
In [159]: sample = lognorm.rvs(sigma, 0, scale, size=1000000)
这是样本的标准差:
In [160]: np.std(sample)
Out[160]: 99.12048952171304
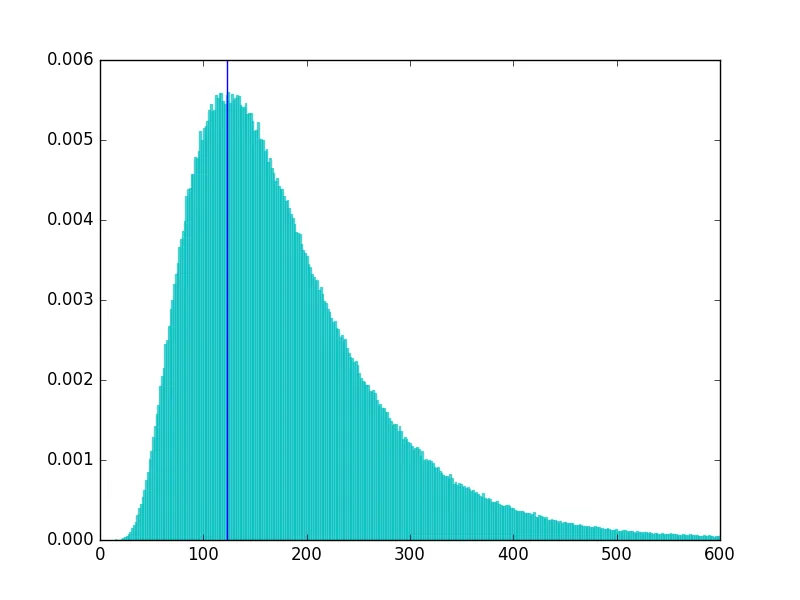
这里是一些 Matplotlib 代码,用于绘制样本的直方图,并在分布的众数处绘制一条竖直线:
In [176]: tmp = plt.hist(sample, normed=True, bins=1000, alpha=0.6, color='c', ec='c')
In [177]: plt.xlim(0, 600)
Out[177]: (0, 600)
In [178]: plt.axvline(mode)
Out[178]: <matplotlib.lines.Line2D at 0x12c5a12e8>
直方图:
如果你想使用 numpy.random.lognormal() 生成样本,而不是使用 scipy.stats.lognorm.rvs(),你可以这样做:
In [200]: sigma, scale = lognorm_params(mode, stddev)
In [201]: mu = np.log(scale)
In [202]: sample = np.random.lognormal(mu, sigma, size=1000000)
In [203]: np.std(sample)
Out[203]: 99.078297384090902
我还没有研究过 poly1d 的 roots 算法的稳健性,因此请务必测试各种可能的输入值。或者,您可以使用 scipy 中的求解器来解决上述多项式中的 x。您可以使用以下方法限制解的范围:
max(sqrt(stddev/mode), 1) <= x <= sqrt(stddev/mode) + 1
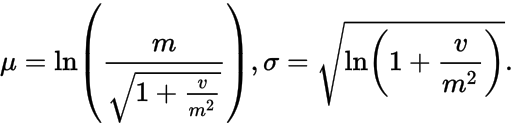
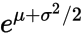 ,那么众数就是
,那么众数就是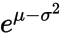 。通过这个以及上面的内容,我们可以推断出:
。通过这个以及上面的内容,我们可以推断出: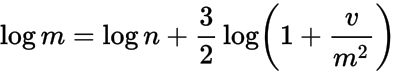
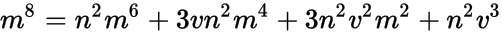
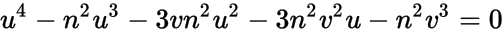
r = lognorm.rvs(s, size=1000),其中s是分布的形状参数。 - Pankaj Daga