假设我有以下数据:
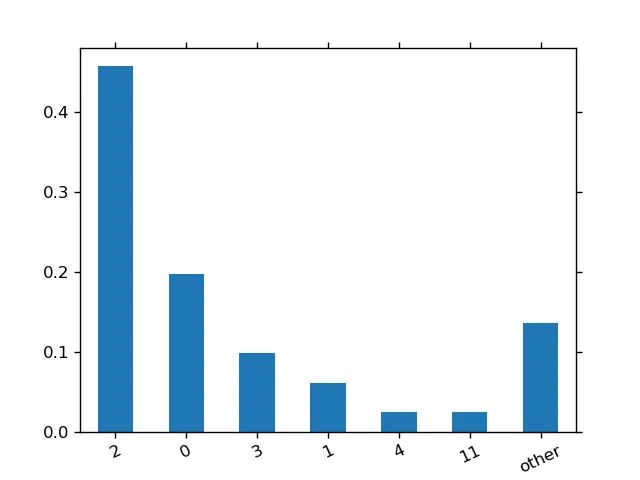
s2 = pd.Series([1,2,3,4,5,2,3,333,2,123,434,1,2,3,1,11,11,432,3,2,4,3,3,3,54,34,24,2,223,2535334,3,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,30000, 2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2])
s2.value_counts(normalize=True).plot()
我想展示出只有少数数字占据了大多数情况。问题是这些数字将会出现在图表的最左侧,而其他类别的柱状图则会很短。
在真实数据中,x轴将是大约18000种类别的分类变量,其中4%的计数约为10000,然后其余的计数将下降到约为50。
更新:请参见@unutbu的回答。
更新代码时,当尝试使用元组时,我遇到了关于qcut的错误。
TypeError: unsupported operand type(s) for -: 'tuple' and 'tuple'
df = pd.DataFrame({'s1':[1,0,1,0], 's2':[1,0,1,1], 's3':[1,0,1,1], 's4':[0,0,0,1]})
perms = df.apply(tuple, axis=1)
prob = perms.value_counts(normalize=True).reset_index(drop='True')
category_classes = pd.qcut(prob, q=[0, .25, 0.95, 1.],
labels=['bottom 25%', 'mid 70%', 'top 5%'])
prob_groups = prob.groupby(category_classes).sum()
prob_groups.plot(kind='bar')
plt.xticks(rotation=0)
plt.show()
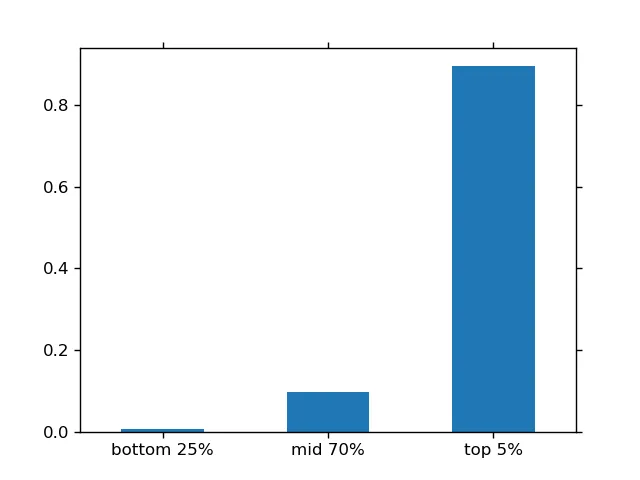
prob的定义中,将.reset_index()更改为.reset_index(drop=True)。这将删除索引,使得prob仍然是一个 Series 而不是转换成 DataFrame。然后,pd.qcut将仅应用于概率,而不是也应用于元组。 - unutbu