我已经实现了多种非常快速的解决方案。根据输入大小,这些解决方案与规范简单卷积实现相比,可以提供高达2650x倍的加速!
注意:不必阅读整篇文章,只需直接滚动到下面的代码并复制第一个conv2d_fast(...)函数的代码,在您的代码中使用它,它包含了所有需要的内容。此外,为了简洁起见,我只复制了两个最佳实现的代码放在此代码粘贴处。
我在某些输入下实现的最大加速度提升:1)conv2d_fast - 755x 2)conv2d_medium - 1830x 3)conv2d_fast_numba - 2650x。
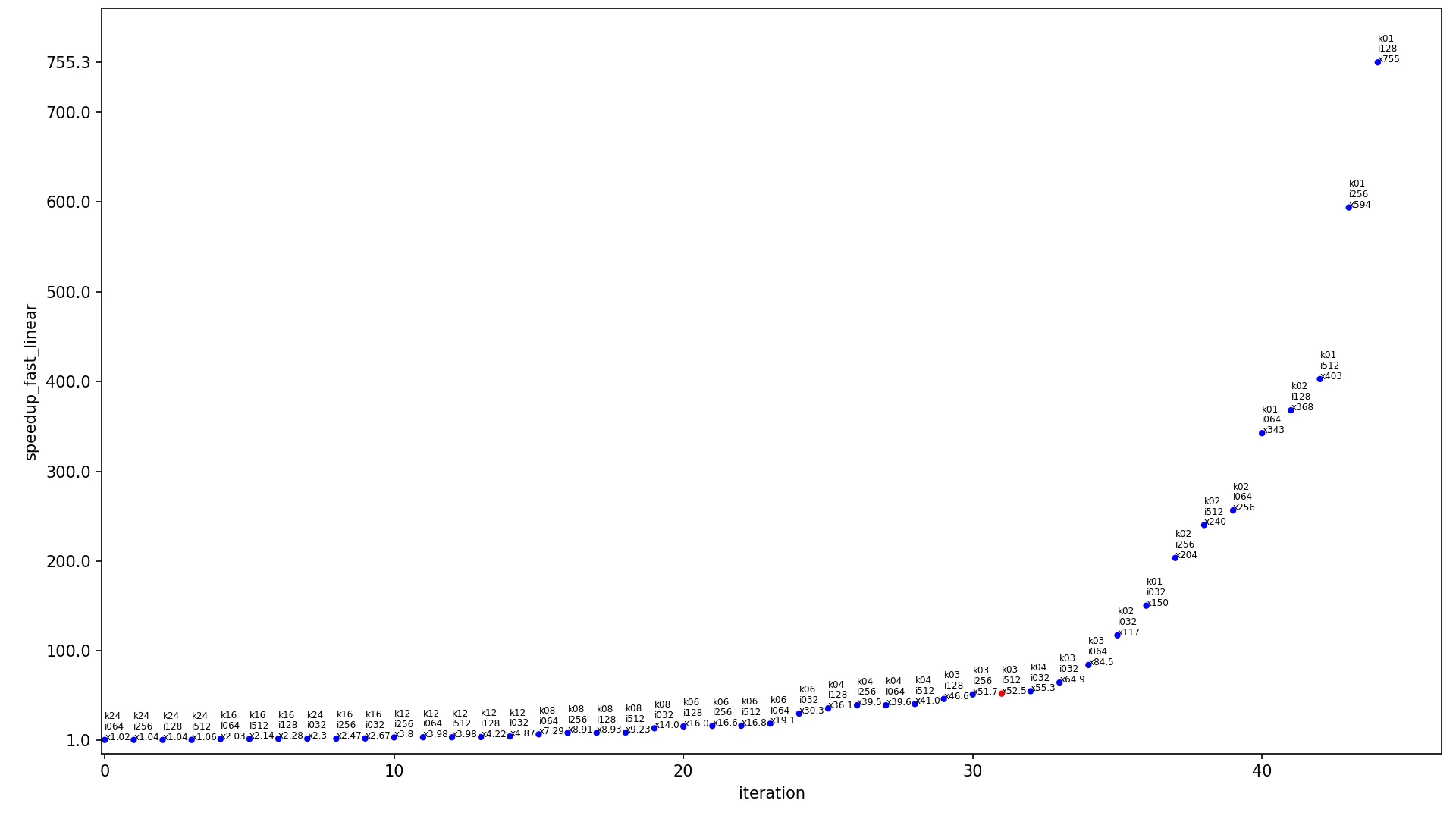
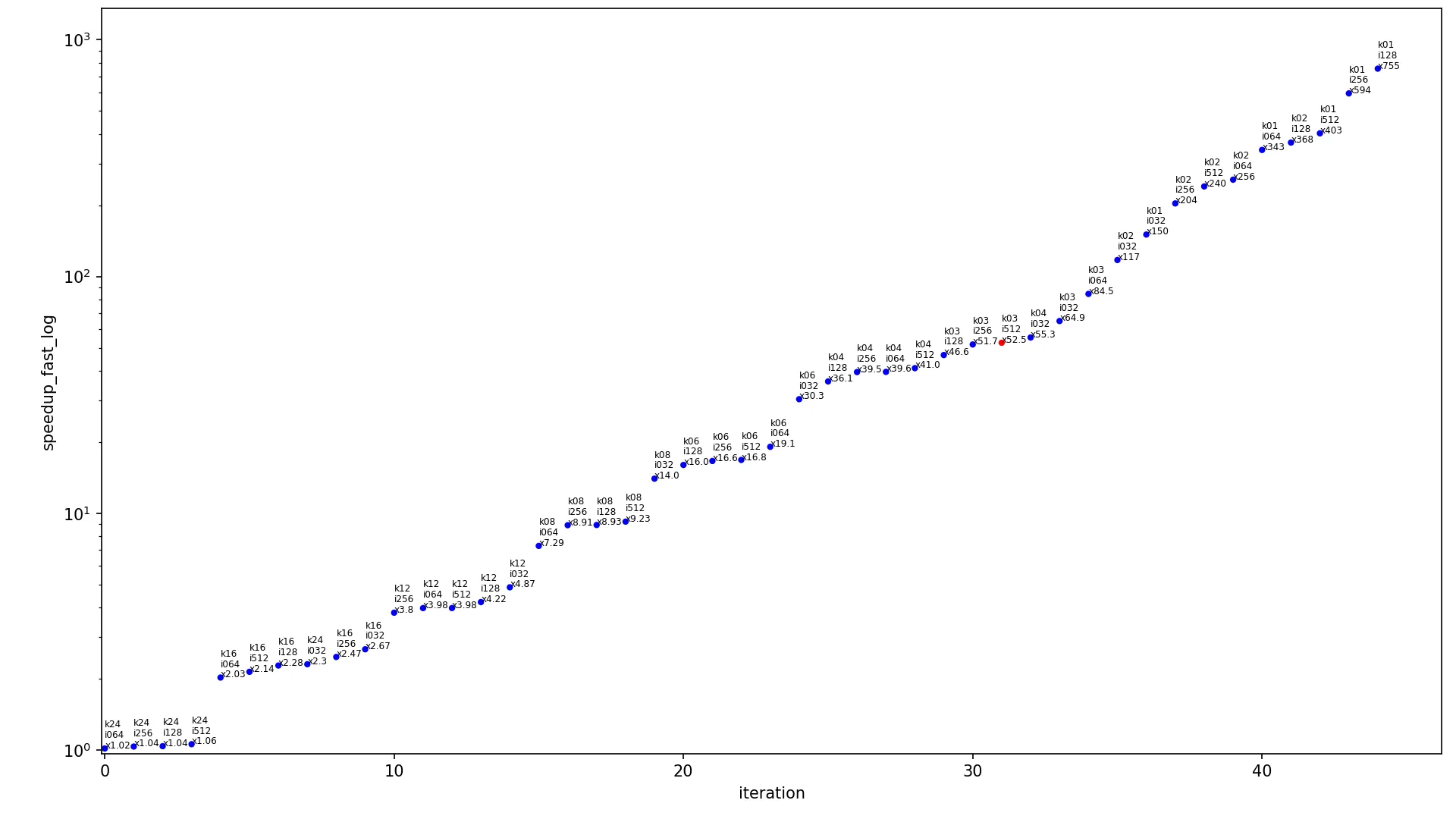
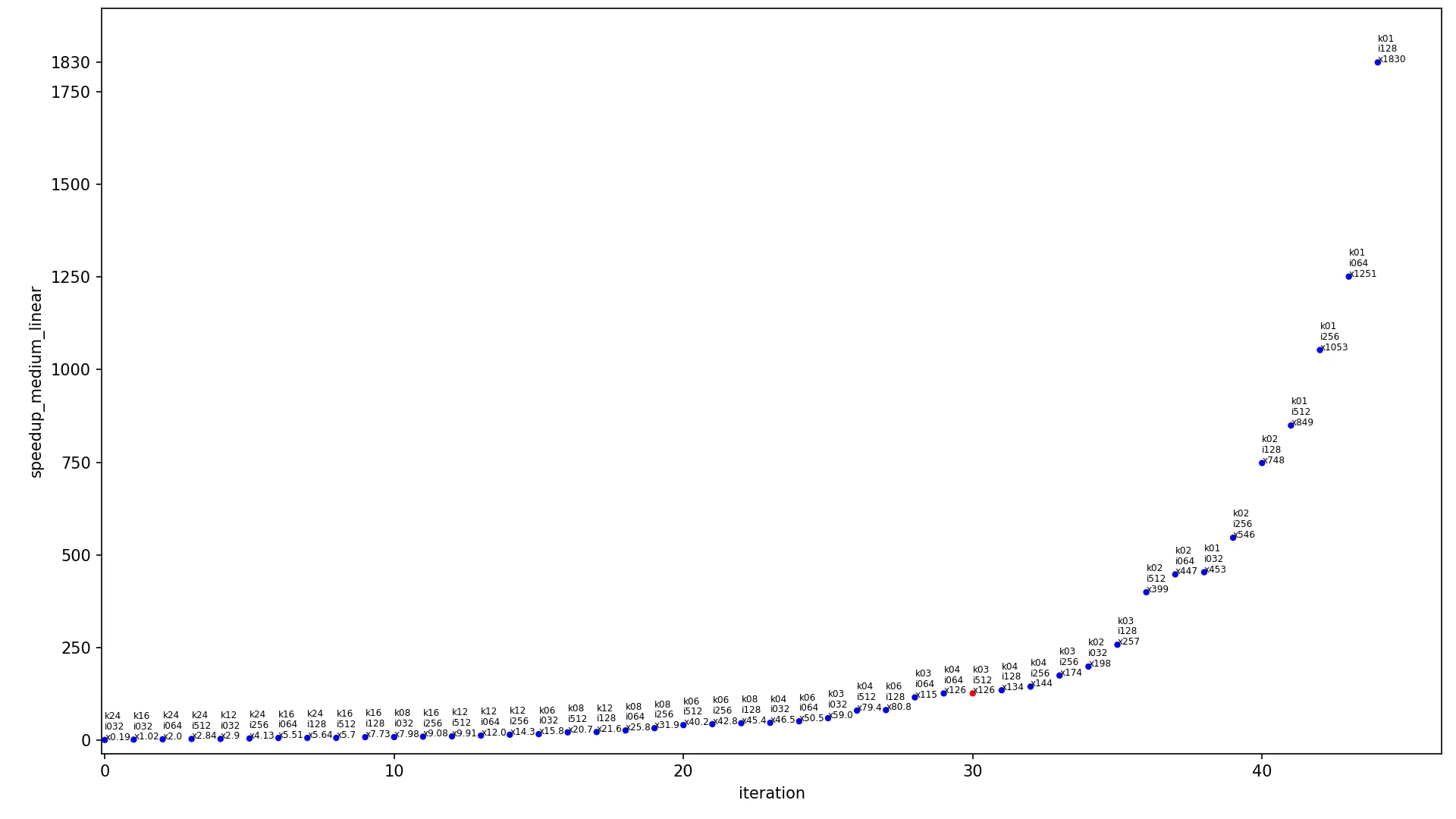
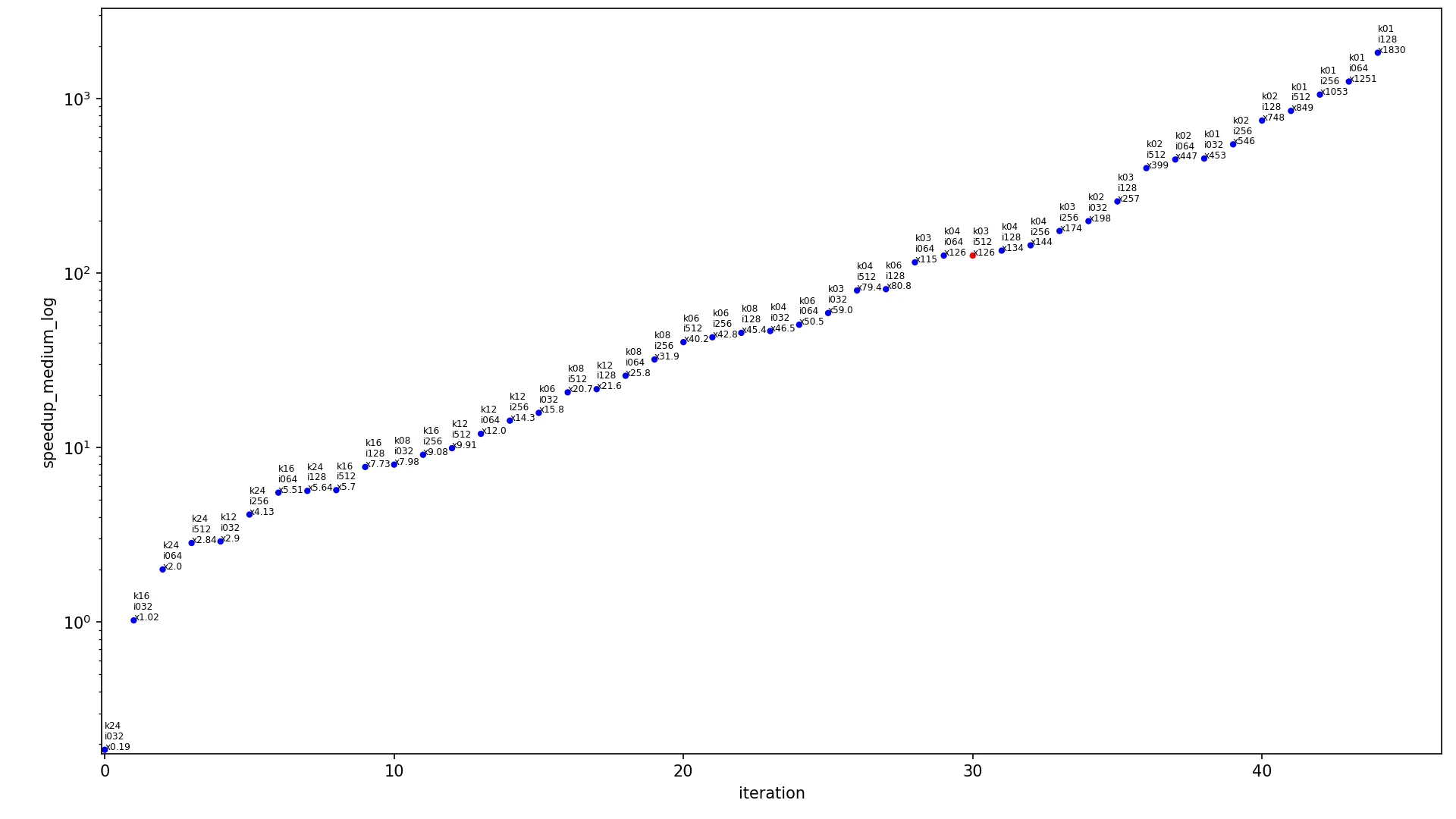
对于图像大小为460x512和核大小为3x3(这个核大小是计算机视觉和神经网络常用的卷积核尺寸),解决方案的加速率如下:1)conv2d_fast - 52.5x 2)conv2d_medium - 126x 3)conv2d_fast_numba - 319x。在下面显示的图形中,此参考图像大小和核大小用红点表示,其他点为蓝色。
加速(Speedup)是指快速解决方案与基本缓慢解决方案(规范的最简卷积实现)相比快多少。例如,20x的加速意味着如果基础缓慢解决方案在函数内花费了200毫秒,则快速解决方案在该函数内花费了10毫秒。
我的代码中将缓慢的基准参考函数称为`conv2d_slow(...)`。所有计时/加速和结果正确性都是针对这个函数进行测量的。它实现了计算卷积的规范最简算法,如下公式/图片所示,摘自OpenCV filter2D(...) doc:
Algorithm `conv2d_fast`是纯NumPy版本,没有Python循环,它是最快的NumPy版本之一。
`conv2d_medium`包含Python循环,但也非常快,对于某些输入它比上一个算法慢(当内核大小大且接近图像大小时),但对于其他输入它更快,对于常见内核大小,它比`conv2d_fast`平均快2倍。不选择此解决方案的唯一原因是因为它不是纯NumPy,因为它包含Python循环,而且对于大型内核它会比`conv2d_fast`明显慢。
`conv2d_fast_numba`是基于Numba的,Numba是JIT编译器,将Python代码转换为纯C++代码并将其编译为机器代码。虽然没有要求实现非NumPy解决方案,但我还是这样做了,因为Numba专门为改进基于NumPy的代码而创建,因此它与NumPy密切相关。Numba解决方案是最快的,平均比前一个最快的`conv2d_medium`快3-8倍。
上述所有函数都不需要额外的准备工作(例如导入某些模块),只需复制粘贴单个选择的函数代码并在代码中使用即可。
我的代码需要通过运行以下命令安装下一个pip模块才能使用:`python -m pip install numpy numba matplotlib timerit`。但是卷积的主要实现`conv2d_fast`/ `conv2d_slow` / `conv2d_medium`只需要`numpy`模块安装即可。
在线尝试此代码!
def conv2d_fast(img, krn):
import numpy as np
is0, is1, ks0, ks1 = *img.shape, *krn.shape
rs0, rs1 = is0 - ks0 + 1, is1 - ks1 + 1
ix0 = np.arange(ks0)[:, None] + np.arange(rs0)[None, :]
ix1 = np.arange(ks1)[:, None] + np.arange(rs1)[None, :]
res = krn[:, None, :, None] * img[(ix0.ravel()[:, None], ix1.ravel()[None, :])].reshape(ks0, rs0, ks1, rs1)
res = res.transpose(1, 3, 0, 2).reshape(rs0, rs1, -1).sum(axis = -1)
return res
def conv2d_slow(img, krn):
import numpy as np
is0, is1, ks0, ks1 = *img.shape, *krn.shape
rs0, rs1 = is0 - ks0 + 1, is1 - ks1 + 1
res = np.zeros((rs0, rs1), dtype = krn.dtype)
for i in range(rs0):
for j in range(rs1):
res[i, j] = (krn * img[i : i + ks0, j : j + ks1]).sum()
return res
def conv2d_medium(img, krn):
import numpy as np
is0, is1, ks0, ks1 = *img.shape, *krn.shape
rs0, rs1 = is0 - ks0 + 1, is1 - ks1 + 1
res = np.zeros((rs0, rs1), dtype = krn.dtype)
for k in range(ks0):
for l in range(ks1):
res[...] += krn[k, l] * img[k : k + rs0, l : l + rs1]
return res
def conv2d_fast_numba(img, krn, *, state = {}):
if 'f' not in state:
import numpy as np
def conv2d_fast_nm(img, krn):
is0, is1, ks0, ks1 = *img.shape, *krn.shape
rs0, rs1 = is0 - ks0 + 1, is1 - ks1 + 1
res = np.zeros((rs0, rs1), dtype = krn.dtype)
for k in range(ks0):
for l in range(ks1):
for i in range(rs0):
for j in range(rs1):
res[i, j] += krn[k, l] * img[i + k, j + l]
return res
import numba
state['f'] = numba.njit(cache = True, parallel = True, fastmath = True)(conv2d_fast_nm)
return state['f'](img, krn)
def test():
import math, matplotlib, matplotlib.pyplot as plt, numpy as np
from timerit import Timerit
Timerit._default_asciimode = True
np.random.seed(0)
for ifuncs, (fname, funcs) in enumerate([
('fast', (conv2d_slow, conv2d_fast)),
('medium', (conv2d_slow, conv2d_medium)),
('numba', (conv2d_slow, conv2d_fast_numba)),
('fast_bmed', (conv2d_medium, conv2d_fast)),
('numba_bmed', (conv2d_medium, conv2d_fast_numba)),
]):
stats = []
for krn_size in [1, 2, 3, 4, 6, 8, 12, 16, 24]:
for img_size in [32, 64, 128, 256, 512]:
ih, iw = max(1, math.floor(img_size * 0.9)), img_size
kh, kw = max(1, math.floor(krn_size * 0.9)), krn_size
if krn_size == 3:
kh = 3
print(f'krn_size ({kh}, {kw}) img_size ({ih}, {iw})', flush = True)
krn = np.random.uniform(-1., 1., (kh, kw))
img = np.random.uniform(0., 255., (ih, iw))
for ifn, f in enumerate(funcs):
print(f'{f.__name__}: ', end = '', flush = True)
work = ih * iw * kh * kw
tim = Timerit(num = min(20, math.ceil(2 ** 15 / work)) * 3, verbose = 1)
for i, t in enumerate(tim):
r = f(img, krn)
rt = tim.mean()
if ifn == 0:
bt, ba = rt, r
else:
assert np.allclose(ba, r)
print(f'speedup {round(bt / rt, 2)}x')
stats.append({
'img_size': img_size,
'krn_size': krn_size,
'speedup': bt / rt,
})
stats = sorted(stats, key = lambda e: e['speedup'])
x = np.arange(len(stats))
y = np.array([e['speedup'] for e in stats])
plt.rcParams['figure.figsize'] = (12.8, 7.2)
for scale in ['linear', 'log']:
plt.clf()
plt.xlabel('iteration')
plt.ylabel(f'speedup_{fname}_{scale}')
plt.yscale(scale)
plt.scatter(x, y, marker = '.', color = [('blue', 'red')[stats[ii]['krn_size'] == 3 and stats[ii]['img_size'] == 512] for ii in range(x.size)])
for i in range(x.size):
plt.annotate(
(f"k{str(stats[i]['krn_size']).zfill(2)}\ni{str(stats[i]['img_size']).zfill(3)}\n" +
f"x{round(stats[i]['speedup'], 2 if stats[i]['speedup'] < 10 else 1 if stats[i]['speedup'] < 100 else None)}"),
(x[i], y[i]), fontsize = 'xx-small',
)
plt.subplots_adjust(left = 0.07, right = 0.99, bottom = 0.08, top = 0.99)
plt.xlim(left = -0.1)
ymin, ymax = np.amin(y), np.amax(y)
if scale == 'log':
plt.ylim((ymin / 1.05, ymax * 1.8))
elif scale == 'linear':
plt.ylim((ymin - (ymax - ymin) * 0.02, ymax + (ymax - ymin) * 0.08))
plt.yticks([ymin] + [e for e in plt.yticks()[0] if ymin + 10 ** -6 < e < ymax - 10 ** -6] + [ymax])
plt.savefig(f'conv2d_numpy_{fname}_{scale}.png', dpi = 150)
plt.show()
if __name__ == '__main__':
test()
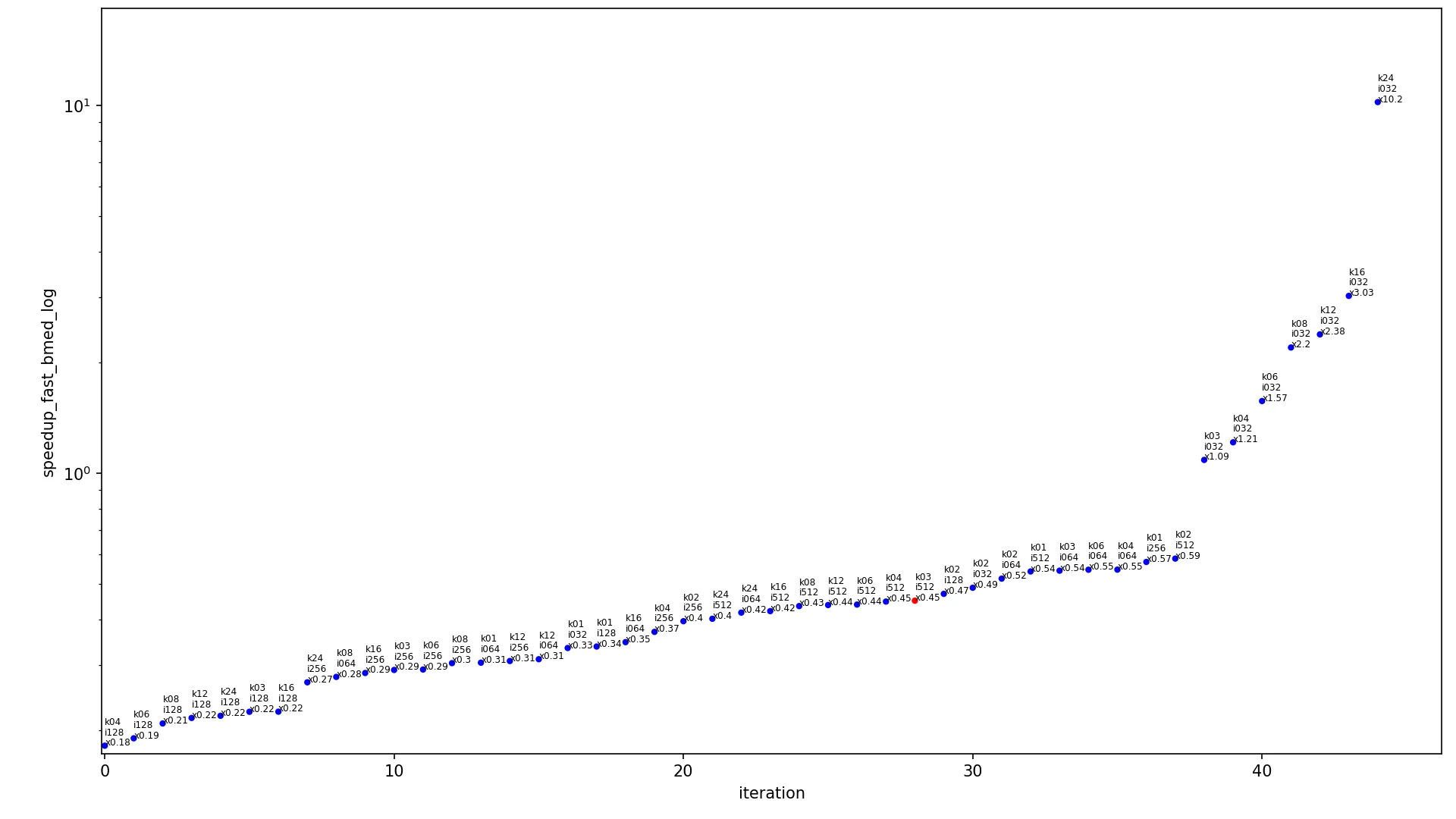
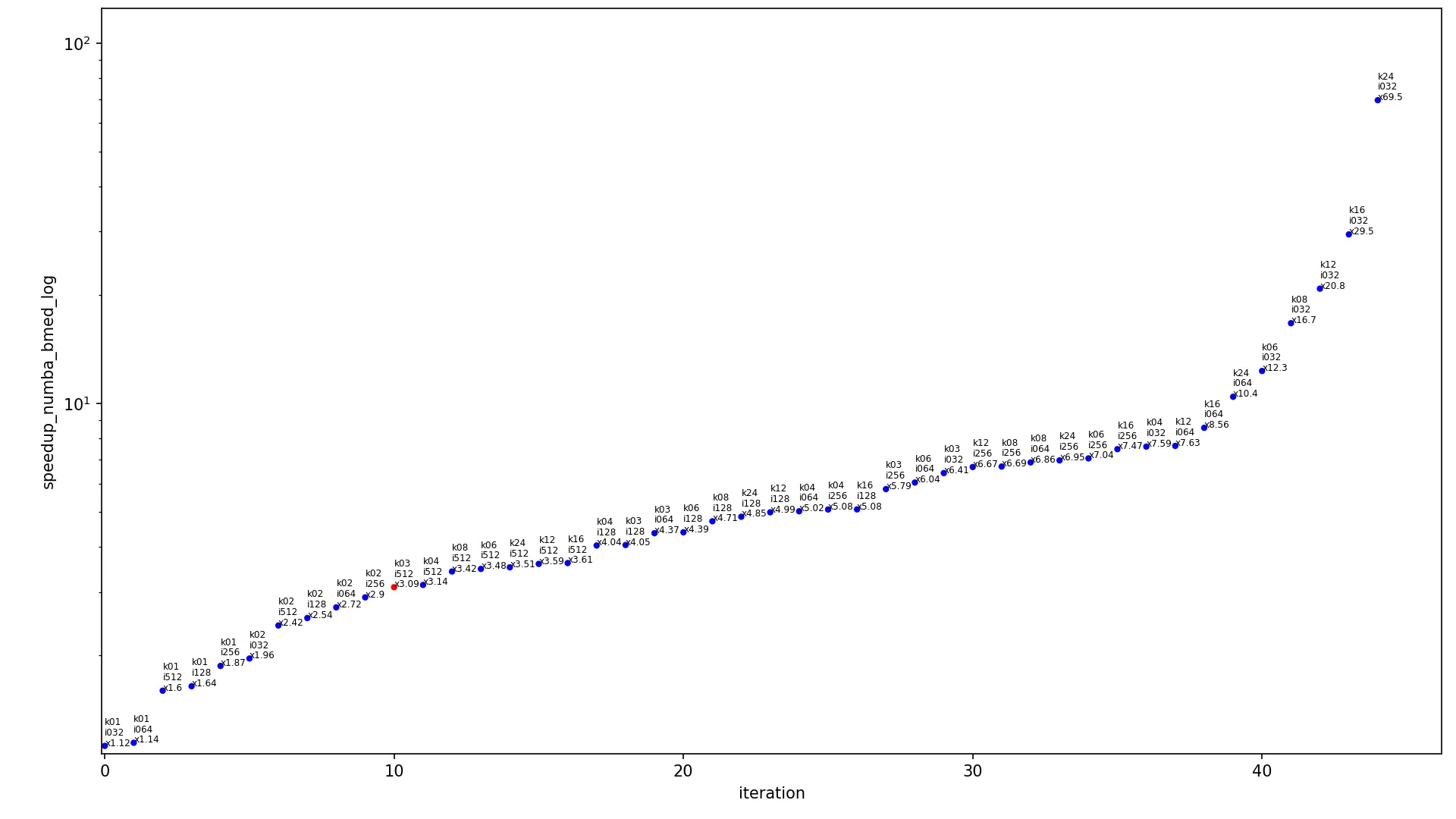
下一个图表包含不同输入大小算法的加速比。
x 轴显示迭代的索引,
y 轴显示加速比,点按升序排列。每个点都标记为
kXX iYYY xZZZ,其中
XX 是内核宽度,
YYY 是图像宽度,
ZZZ 是当前算法在这些内核和图像大小下的加速比。每个图表有两个版本,使用线性尺度(常规线性
y 轴)和对数尺度(
y 轴以对数形式缩放)。每个图表只包含一个红点(其余为蓝色),该红点显示最常用的情况,内核为
3x3 且图像为
460x512,此点应被视为当前图表中最具代表性的点。
点旁边的标签可能看起来太小,因为 StackOverflow 以降低的分辨率显示图表,请在新的浏览器选项卡中打开图像并进行缩放以查看完整的
1920x1080 分辨率。
1.
conv2d_fast linear:
2.
conv2d_fast log:
3.
conv2d_medium linear:
4.
conv2d_medium log:
5.
conv2d_fast_numba linear:
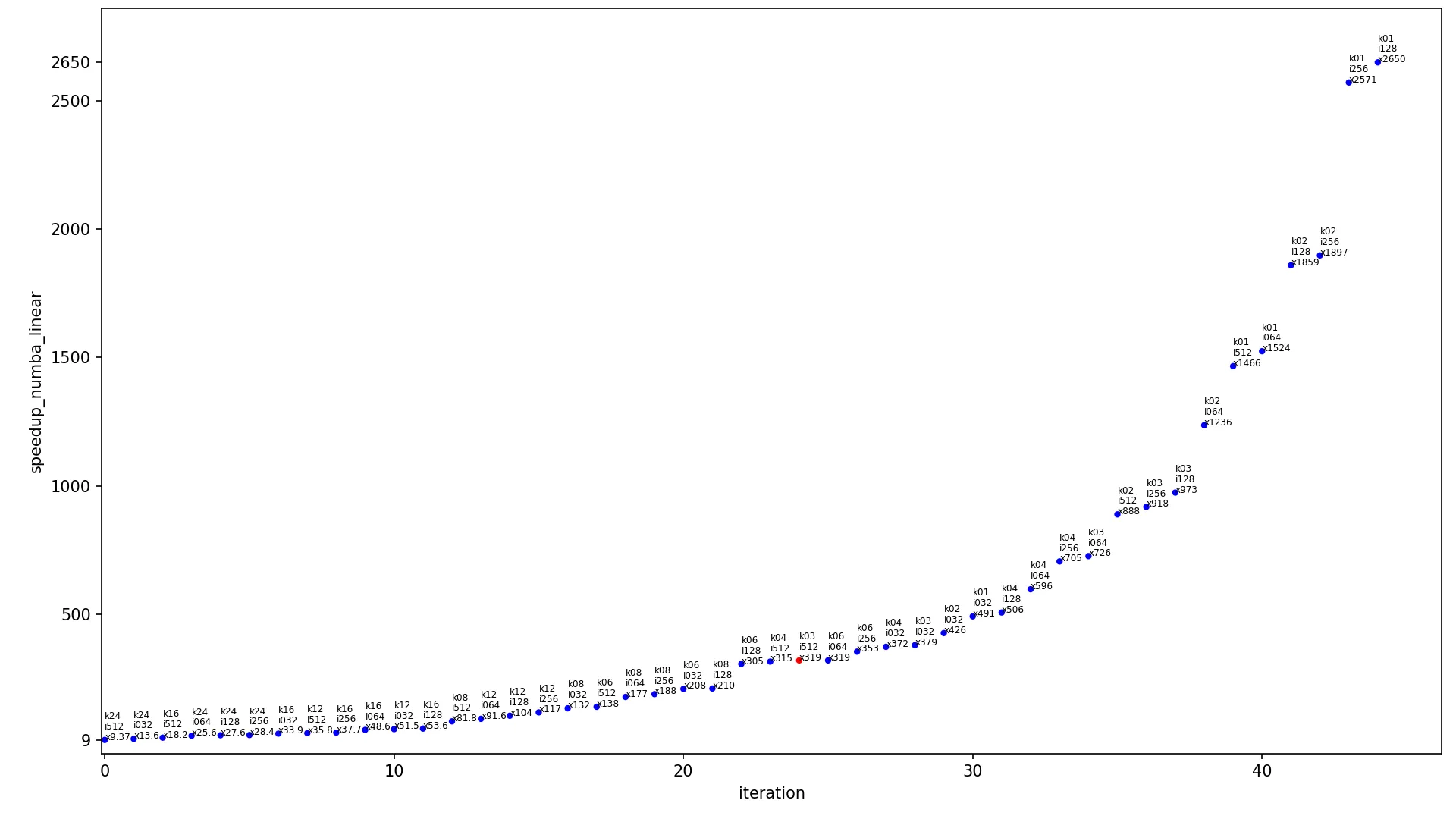
6.
conv2d_fast_numba log:
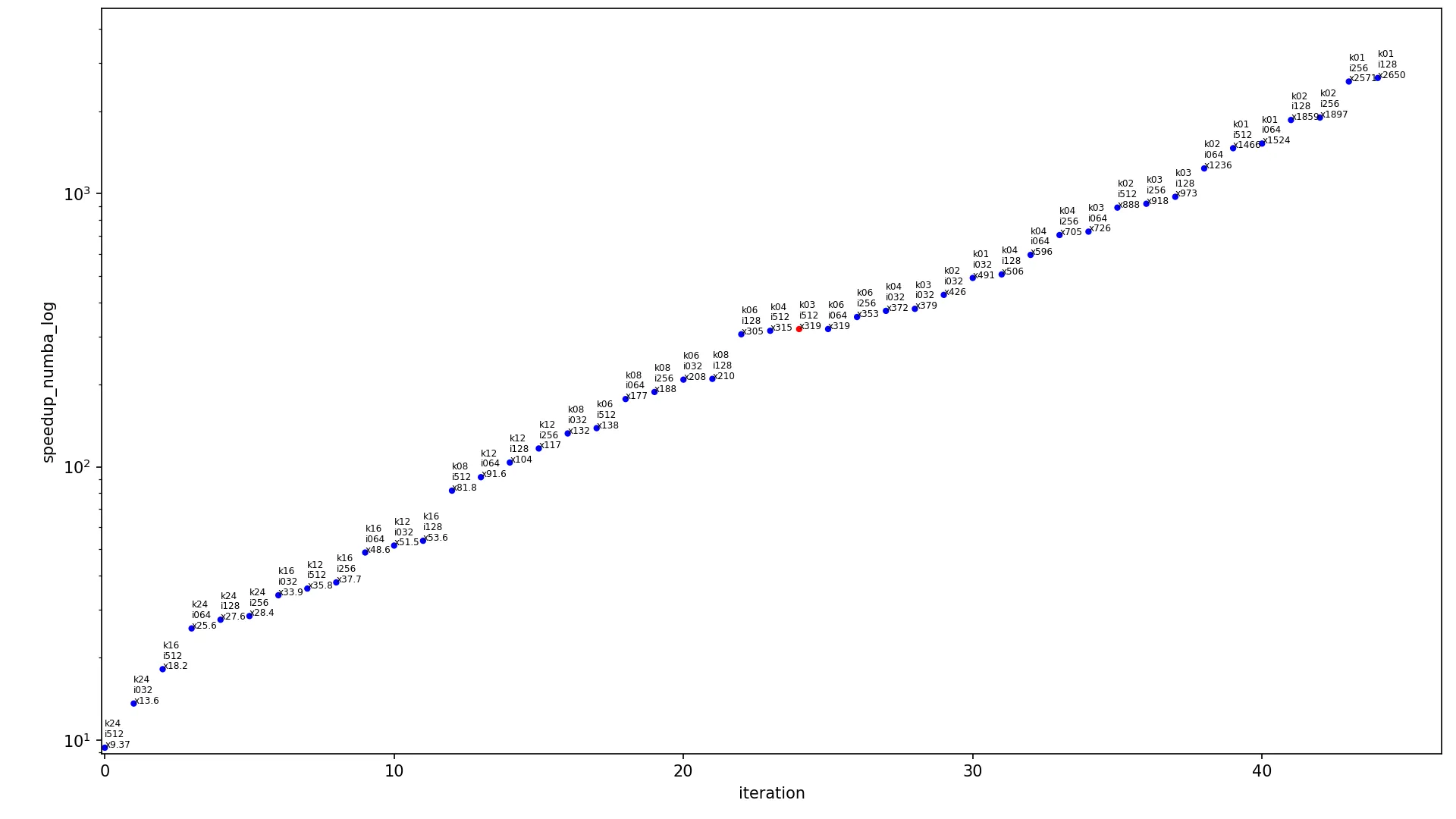
7.
conv2d_fast 与
conv2d_medium 比较,
linear:
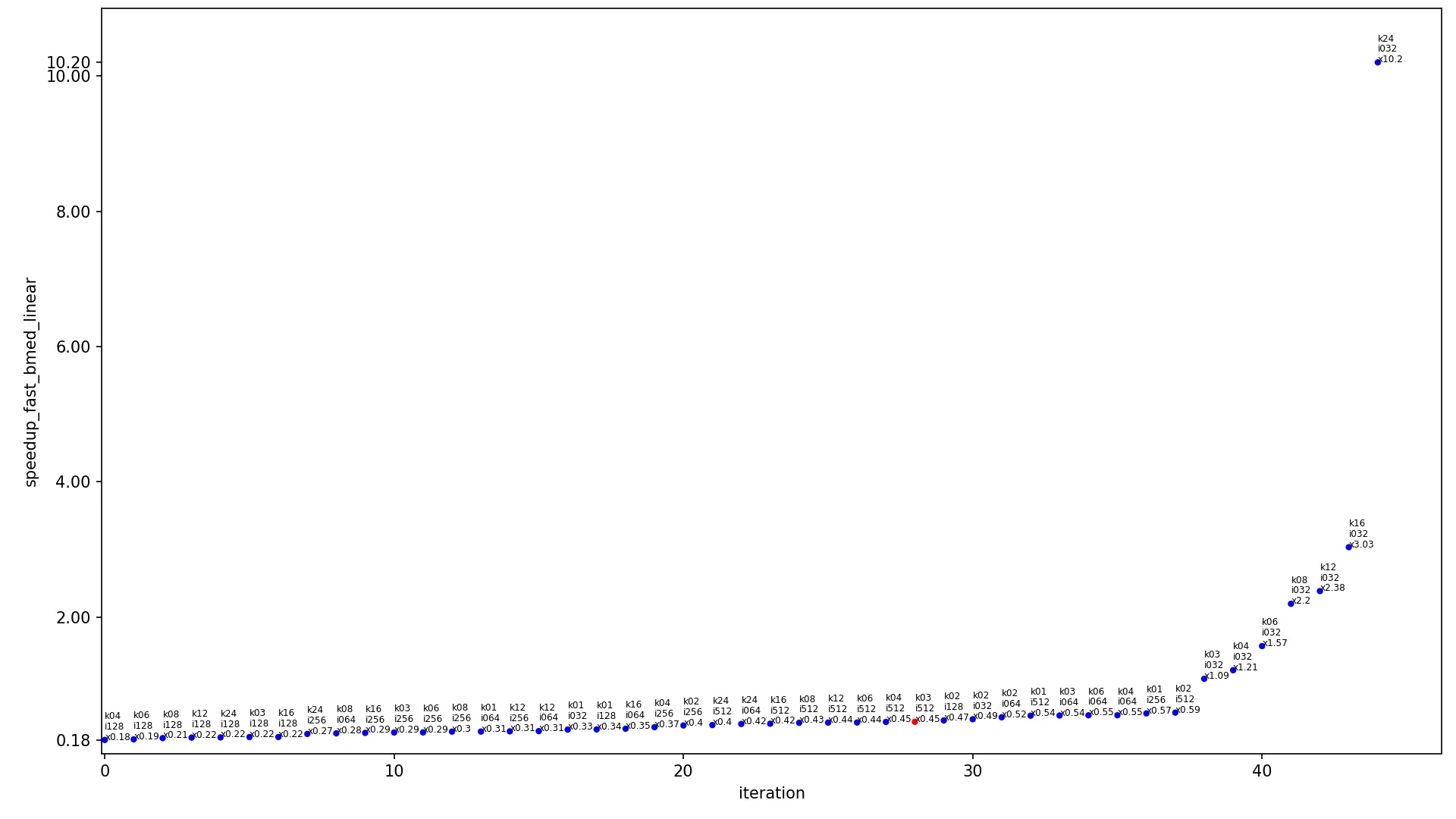
conv2d_fast相对于conv2d_medium和log的比较:
conv2d_fast_numba相对于conv2d_medium和linear的比较:
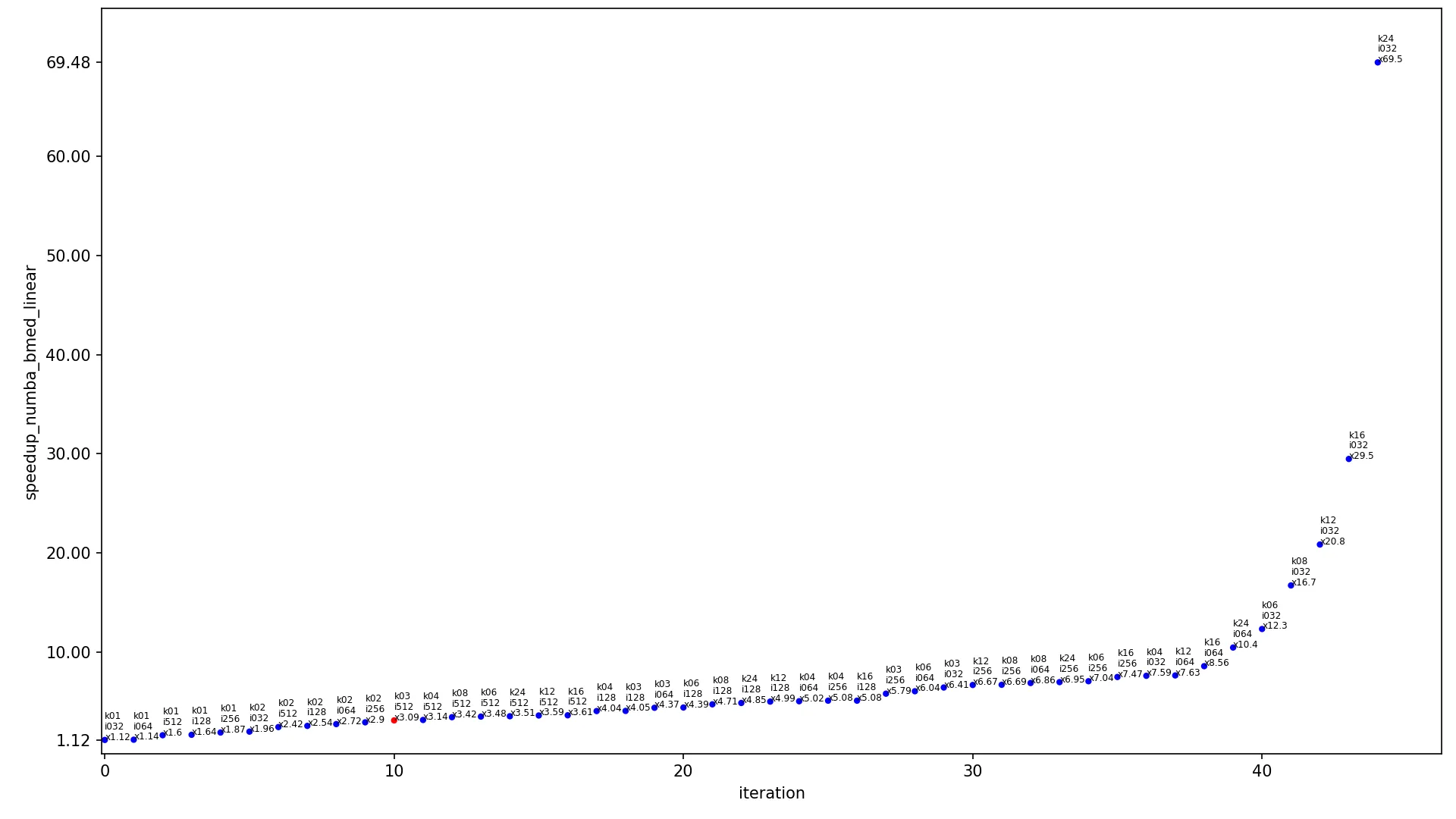
conv2d_fast_numba相对于conv2d_medium和log的比较:
上述代码的控制台输出:
krn_size (1, 1) img_size (28, 32)
conv2d_slow: Timed best=15.037 ms, mean=15.409 +- 0.2 ms
conv2d_fast: Timed best=100.701 us, mean=102.412 +- 1.4 us
speedup 150.46x
krn_size (1, 1) img_size (57, 64)
conv2d_slow: Timed best=61.679 ms, mean=65.878 +- 6.0 ms
conv2d_fast: Timed best=151.541 us, mean=192.332 +- 28.5 us
speedup 342.52x
krn_size (1, 1) img_size (115, 128)
conv2d_slow: Timed best=249.408 ms, mean=252.172 +- 2.4 ms
conv2d_fast: Timed best=328.012 us, mean=333.878 +- 6.6 us
speedup 755.28x
krn_size (1, 1) img_size (230, 256)
conv2d_slow: Timed best=1.013 s, mean=1.013 +- 0.0 s
conv2d_fast: Timed best=1.706 ms, mean=1.706 +- 0.0 ms
speedup 593.72x
krn_size (1, 1) img_size (460, 512)
conv2d_slow: Timed best=4.101 s, mean=4.101 +- 0.0 s
conv2d_fast: Timed best=10.182 ms, mean=10.182 +- 0.0 ms
speedup 402.72x
krn_size (1, 2) img_size (28, 32)
conv2d_slow: Timed best=14.418 ms, mean=15.877 +- 1.8 ms
conv2d_fast: Timed best=132.476 us, mean=135.178 +- 2.1 us
speedup 117.45x
krn_size (1, 2) img_size (57, 64)
conv2d_slow: Timed best=60.057 ms, mean=61.136 +- 1.3 ms
conv2d_fast: Timed best=231.222 us, mean=238.359 +- 11.6 us
speedup 256.49x
krn_size (1, 2) img_size (115, 128)
conv2d_slow: Timed best=264.794 ms, mean=268.452 +- 3.7 ms
conv2d_fast: Timed best=674.112 us, mean=729.595 +- 55.5 us
speedup 367.95x
krn_size (1, 2) img_size (230, 256)
conv2d_slow: Timed best=999.722 ms, mean=999.722 +- 0.0 ms
conv2d_fast: Timed best=4.910 ms, mean=4.910 +- 0.0 ms
speedup 203.61x
krn_size (1, 2) img_size (460, 512)
conv2d_slow: Timed best=4.360 s, mean=4.360 +- 0.0 s
conv2d_fast: Timed best=18.148 ms, mean=18.148 +- 0.0 ms
speedup 240.24x
krn_size (3, 3) img_size (28, 32)
conv2d_slow: Timed best=16.771 ms, mean=17.395 +- 0.7 ms
conv2d_fast: Timed best=256.153 us, mean=268.080 +- 13.5 us
speedup 64.89x
krn_size (3, 3) img_size (57, 64)
conv2d_slow: Timed best=72.964 ms, mean=72.964 +- 0.0 ms
conv2d_fast: Timed best=863.783 us, mean=863.783 +- 0.0 us
speedup 84.47x
krn_size (3, 3) img_size (115, 128)
conv2d_slow: Timed best=302.496 ms, mean=302.496 +- 0.0 ms
conv2d_fast: Timed best=6.490 ms, mean=6.490 +- 0.0 ms
speedup 46.61x
krn_size (3, 3) img_size (230, 256)
conv2d_slow: Timed best=1.281 s, mean=1.281 +- 0.0 s
conv2d_fast: Timed best=24.801 ms, mean=24.801 +- 0.0 ms
speedup 51.66x
krn_size (3, 3) img_size (460, 512)
conv2d_slow: Timed best=5.134 s, mean=5.134 +- 0.0 s
conv2d_fast: Timed best=97.726 ms, mean=97.726 +- 0.0 ms
speedup 52.53x
krn_size (3, 4) img_size (28, 32)
conv2d_slow: Timed best=16.275 ms, mean=16.351 +- 0.1 ms
conv2d_fast: Timed best=286.950 us, mean=295.749 +- 11.9 us
speedup 55.29x
krn_size (3, 4) img_size (57, 64)
conv2d_slow: Timed best=72.170 ms, mean=72.170 +- 0.0 ms
conv2d_fast: Timed best=1.824 ms, mean=1.824 +- 0.0 ms
speedup 39.57x
krn_size (3, 4) img_size (115, 128)
conv2d_slow: Timed best=305.169 ms, mean=305.169 +- 0.0 ms
conv2d_fast: Timed best=8.462 ms, mean=8.462 +- 0.0 ms
speedup 36.06x
krn_size (3, 4) img_size (230, 256)
conv2d_slow: Timed best=1.245 s, mean=1.245 +- 0.0 s
conv2d_fast: Timed best=31.527 ms, mean=31.527 +- 0.0 ms
speedup 39.5x
krn_size (3, 4) img_size (460, 512)
conv2d_slow: Timed best=5.262 s, mean=5.262 +- 0.0 s
conv2d_fast: Timed best=128.232 ms, mean=128.232 +- 0.0 ms
speedup 41.03x
krn_size (5, 6) img_size (28, 32)
conv2d_slow: Timed best=14.060 ms, mean=14.507 +- 0.4 ms
conv2d_fast: Timed best=469.288 us, mean=478.087 +- 8.8 us
speedup 30.34x
krn_size (5, 6) img_size (57, 64)
conv2d_slow: Timed best=67.638 ms, mean=67.638 +- 0.0 ms
conv2d_fast: Timed best=3.542 ms, mean=3.542 +- 0.0 ms
speedup 19.1x
krn_size (5, 6) img_size (115, 128)
conv2d_slow: Timed best=299.806 ms, mean=299.806 +- 0.0 ms
conv2d_fast: Timed best=18.730 ms, mean=18.730 +- 0.0 ms
speedup 16.01x
krn_size (5, 6) img_size (230, 256)
conv2d_slow: Timed best=1.294 s, mean=1.294 +- 0.0 s
conv2d_fast: Timed best=77.809 ms, mean=77.809 +- 0.0 ms
speedup 16.64x
krn_size (5, 6) img_size (460, 512)
conv2d_slow: Timed best=5.336 s, mean=5.336 +- 0.0 s
conv2d_fast: Timed best=317.518 ms, mean=317.518 +- 0.0 ms
speedup 16.81x
krn_size (7, 8) img_size (28, 32)
conv2d_slow: Timed best=12.076 ms, mean=12.076 +- 0.0 ms
conv2d_fast: Timed best=861.827 us, mean=861.827 +- 0.0 us
speedup 14.01x
krn_size (7, 8) img_size (57, 64)
conv2d_slow: Timed best=64.761 ms, mean=64.761 +- 0.0 ms
conv2d_fast: Timed best=8.889 ms, mean=8.889 +- 0.0 ms
speedup 7.29x
krn_size (7, 8) img_size (115, 128)
conv2d_slow: Timed best=293.768 ms, mean=293.768 +- 0.0 ms
conv2d_fast: Timed best=32.908 ms, mean=32.908 +- 0.0 ms
speedup 8.93x
krn_size (7, 8) img_size (230, 256)
conv2d_slow: Timed best=1.245 s, mean=1.245 +- 0.0 s
conv2d_fast: Timed best=139.752 ms, mean=139.752 +- 0.0 ms
speedup 8.91x
krn_size (7, 8) img_size (460, 512)
conv2d_slow: Timed best=5.535 s, mean=5.535 +- 0.0 s
conv2d_fast: Timed best=599.906 ms, mean=599.906 +- 0.0 ms
speedup 9.23x
krn_size (10, 12) img_size (28, 32)
conv2d_slow: Timed best=8.776 ms, mean=8.776 +- 0.0 ms
conv2d_fast: Timed best=1.801 ms, mean=1.801 +- 0.0 ms
speedup 4.87x
krn_size (10, 12) img_size (57, 64)
conv2d_slow: Timed best=55.155 ms, mean=55.155 +- 0.0 ms
conv2d_fast: Timed best=13.861 ms, mean=13.861 +- 0.0 ms
speedup 3.98x
krn_size (10, 12) img_size (115, 128)
conv2d_slow: Timed best=275.688 ms, mean=275.688 +- 0.0 ms
conv2d_fast: Timed best=65.345 ms, mean=65.345 +- 0.0 ms
speedup 4.22x
krn_size (10, 12) img_size (230, 256)
conv2d_slow: Timed best=1.215 s, mean=1.215 +- 0.0 s
conv2d_fast: Timed best=319.263 ms, mean=319.263 +- 0.0 ms
speedup 3.8x
krn_size (10, 12) img_size (460, 512)
conv2d_slow: Timed best=5.413 s, mean=5.413 +- 0.0 s
conv2d_fast: Timed best=1.360 s, mean=1.360 +- 0.0 s
speedup 3.98x
krn_size (14, 16) img_size (28, 32)
conv2d_slow: Timed best=6.660 ms, mean=6.660 +- 0.0 ms
conv2d_fast: Timed best=2.498 ms, mean=2.498 +- 0.0 ms
speedup 2.67x
krn_size (14, 16) img_size (57, 64)
conv2d_slow: Timed best=49.958 ms, mean=49.958 +- 0.0 ms
conv2d_fast: Timed best=24.663 ms, mean=24.663 +- 0.0 ms
speedup 2.03x
krn_size (14, 16) img_size (115, 128)
conv2d_slow: Timed best=273.521 ms, mean=273.521 +- 0.0 ms
conv2d_fast: Timed best=120.138 ms, mean=120.138 +- 0.0 ms
speedup 2.28x
krn_size (14, 16) img_size (230, 256)
conv2d_slow: Timed best=1.329 s, mean=1.329 +- 0.0 s
conv2d_fast: Timed best=537.025 ms, mean=537.025 +- 0.0 ms
speedup 2.47x
krn_size (14, 16) img_size (460, 512)
conv2d_slow: Timed best=5.615 s, mean=5.615 +- 0.0 s
conv2d_fast: Timed best=2.623 s, mean=2.623 +- 0.0 s
speedup 2.14x
krn_size (21, 24) img_size (28, 32)
conv2d_slow: Timed best=2.203 ms, mean=2.203 +- 0.0 ms
conv2d_fast: Timed best=955.684 us, mean=955.684 +- 0.0 us
speedup 2.3x
krn_size (21, 24) img_size (57, 64)
conv2d_slow: Timed best=41.180 ms, mean=41.180 +- 0.0 ms
conv2d_fast: Timed best=40.526 ms, mean=40.526 +- 0.0 ms
speedup 1.02x
krn_size (21, 24) img_size (115, 128)
conv2d_slow: Timed best=288.575 ms, mean=288.575 +- 0.0 ms
conv2d_fast: Timed best=277.724 ms, mean=277.724 +- 0.0 ms
speedup 1.04x
krn_size (21, 24) img_size (230, 256)
conv2d_slow: Timed best=1.334 s, mean=1.334 +- 0.0 s
conv2d_fast: Timed best=1.288 s, mean=1.288 +- 0.0 s
speedup 1.04x
krn_size (21, 24) img_size (460, 512)
conv2d_slow: Timed best=6.351 s, mean=6.351 +- 0.0 s
conv2d_fast: Timed best=5.996 s, mean=5.996 +- 0.0 s
speedup 1.06x
krn_size (1, 1) img_size (28, 32)
conv2d_slow: Timed best=15.644 ms, mean=16.388 +- 0.9 ms
conv2d_medium: Timed best=34.708 us, mean=36.174 +- 1.8 us
speedup 453.03x
krn_size (1, 1) img_size (57, 64)
conv2d_slow: Timed best=62.969 ms, mean=77.952 +- 15.0 ms
conv2d_medium: Timed best=54.261 us, mean=62.300 +- 4.8 us
speedup 1251.24x
krn_size (1, 1) img_size (115, 128)
conv2d_slow: Timed best=285.944 ms, mean=487.718 +- 148.2 ms
conv2d_medium: Timed best=246.865 us, mean=266.581 +- 14.8 us
speedup 1829.53x
krn_size (1, 1) img_size (230, 256)
conv2d_slow: Timed best=1.474 s, mean=1.474 +- 0.0 s
conv2d_medium: Timed best=1.400 ms, mean=1.400 +- 0.0 ms
speedup 1052.98x
krn_size (1, 1) img_size (460, 512)
conv2d_slow: Timed best=4.434 s, mean=4.434 +- 0.0 s
conv2d_medium: Timed best=5.222 ms, mean=5.222 +- 0.0 ms
speedup 849.22x
krn_size (1, 2) img_size (28, 32)
conv2d_slow: Timed best=14.759 ms, mean=15.430 +- 1.2 ms
conv2d_medium: Timed best=69.904 us, mean=77.803 +- 6.8 us
speedup 198.33x
krn_size (1, 2) img_size (57, 64)
conv2d_slow: Timed best=60.825 ms, mean=62.482 +- 1.8 ms
conv2d_medium: Timed best=138.342 us, mean=139.711 +- 1.3 us
speedup 447.22x
krn_size (1, 2) img_size (115, 128)
conv2d_slow: Timed best=261.207 ms, mean=263.777 +- 2.6 ms
conv2d_medium: Timed best=343.167 us, mean=352.699 +- 9.5 us
speedup 747.88x
krn_size (1, 2) img_size (230, 256)
conv2d_slow: Timed best=1.031 s, mean=1.031 +- 0.0 s
conv2d_medium: Timed best=1.887 ms, mean=1.887 +- 0.0 ms
speedup 546.21x
krn_size (1, 2) img_size (460, 512)
conv2d_slow: Timed best=4.126 s, mean=4.126 +- 0.0 s
conv2d_medium: Timed best=10.341 ms, mean=10.341 +- 0.0 ms
speedup 398.96x
krn_size (3, 3) img_size (28, 32)
conv2d_slow: Timed best=16.776 ms, mean=16.975 +- 0.2 ms
conv2d_medium: Timed best=283.528 us, mean=287.829 +- 6.3 us
speedup 58.98x
krn_size (3, 3) img_size (57, 64)
conv2d_slow: Timed best=73.292 ms, mean=73.292 +- 0.0 ms
conv2d_medium: Timed best=636.472 us, mean=636.472 +- 0.0 us
speedup 115.15x
krn_size (3, 3) img_size (115, 128)
conv2d_slow: Timed best=308.051 ms, mean=308.051 +- 0.0 ms
conv2d_medium: Timed best=1.198 ms, mean=1.198 +- 0.0 ms
speedup 257.21x
krn_size (3, 3) img_size (230, 256)
conv2d_slow: Timed best=1.277 s, mean=1.277 +- 0.0 s
conv2d_medium: Timed best=7.335 ms, mean=7.335 +- 0.0 ms
speedup 174.1x
krn_size (3, 3) img_size (460, 512)
conv2d_slow: Timed best=5.306 s, mean=5.306 +- 0.0 s
conv2d_medium: Timed best=42.131 ms, mean=42.131 +- 0.0 ms
speedup 125.94x
krn_size (3, 4) img_size (28, 32)
conv2d_slow: Timed best=16.628 ms, mean=18.073 +- 2.1 ms
conv2d_medium: Timed best=378.363 us, mean=388.629 +- 9.5 us
speedup 46.51x
krn_size (3, 4) img_size (57, 64)
conv2d_slow: Timed best=71.848 ms, mean=71.848 +- 0.0 ms
conv2d_medium: Timed best=570.966 us, mean=570.966 +- 0.0 us
speedup 125.84x
krn_size (3, 4) img_size (115, 128)
conv2d_slow: Timed best=307.969 ms, mean=307.969 +- 0.0 ms
conv2d_medium: Timed best=2.292 ms, mean=2.292 +- 0.0 ms
speedup 134.36x
krn_size (3, 4) img_size (230, 256)
conv2d_slow: Timed best=1.419 s, mean=1.419 +- 0.0 s
conv2d_medium: Timed best=9.847 ms, mean=9.847 +- 0.0 ms
speedup 144.14x
krn_size (3, 4) img_size (460, 512)
conv2d_slow: Timed best=5.808 s, mean=5.808 +- 0.0 s
conv2d_medium: Timed best=73.120 ms, mean=73.120 +- 0.0 ms
speedup 79.44x
krn_size (5, 6) img_size (28, 32)
conv2d_slow: Timed best=14.524 ms, mean=14.705 +- 0.2 ms
conv2d_medium: Timed best=918.044 us, mean=930.998 +- 13.0 us
speedup 15.79x
krn_size (5, 6) img_size (57, 64)
conv2d_slow: Timed best=71.519 ms, mean=71.519 +- 0.0 ms
conv2d_medium: Timed best=1.415 ms, mean=1.415 +- 0.0 ms
speedup 50.54x
krn_size (5, 6) img_size (115, 128)
conv2d_slow: Timed best=299.480 ms, mean=299.480 +- 0.0 ms
conv2d_medium: Timed best=3.706 ms, mean=3.706 +- 0.0 ms
speedup 80.8x
krn_size (5, 6) img_size (230, 256)
conv2d_slow: Timed best=1.647 s, mean=1.647 +- 0.0 s
conv2d_medium: Timed best=38.446 ms, mean=38.446 +- 0.0 ms
speedup 42.83x
krn_size (5, 6) img_size (460, 512)
conv2d_slow: Timed best=5.496 s, mean=5.496 +- 0.0 s
conv2d_medium: Timed best=136.823 ms, mean=136.823 +- 0.0 ms
speedup 40.17x
krn_size (7, 8) img_size (28, 32)
conv2d_slow: Timed best=16.223 ms, mean=16.223 +- 0.0 ms
conv2d_medium: Timed best=2.033 ms, mean=2.033 +- 0.0 ms
speedup 7.98x
krn_size (7, 8) img_size (57, 64)
conv2d_slow: Timed best=82.617 ms, mean=82.617 +- 0.0 ms
conv2d_medium: Timed best=3.206 ms, mean=3.206 +- 0.0 ms
speedup 25.77x
krn_size (7, 8) img_size (115, 128)
conv2d_slow: Timed best=304.944 ms, mean=304.944 +- 0.0 ms
conv2d_medium: Timed best=6.716 ms, mean=6.716 +- 0.0 ms
speedup 45.4x
krn_size (7, 8) img_size (230, 256)
conv2d_slow: Timed best=1.295 s, mean=1.295 +- 0.0 s
conv2d_medium: Timed best=40.545 ms, mean=40.545 +- 0.0 ms
speedup 31.94x
krn_size (7, 8) img_size (460, 512)
conv2d_slow: Timed best=5.400 s, mean=5.400 +- 0.0 s
conv2d_medium: Timed best=260.807 ms, mean=260.807 +- 0.0 ms
speedup 20.71x
krn_size (10, 12) img_size (28, 32)
conv2d_slow: Timed best=9.135 ms, mean=9.135 +- 0.0 ms
conv2d_medium: Timed best=3.154 ms, mean=3.154 +- 0.0 ms
speedup 2.9x
krn_size (10, 12) img_size (57, 64)
conv2d_slow: Timed best=57.130 ms, mean=57.130 +- 0.0 ms
conv2d_medium: Timed best=4.768 ms, mean=4.768 +- 0.0 ms
speedup 11.98x
krn_size (10, 12) img_size (115, 128)
conv2d_slow: Timed best=277.271 ms, mean=277.271 +- 0.0 ms
conv2d_medium: Timed best=12.841 ms, mean=12.841 +- 0.0 ms
speedup 21.59x
krn_size (10, 12) img_size (230, 256)
conv2d_slow: Timed best=1.221 s, mean=1.221 +- 0.0 s
conv2d_medium: Timed best=85.651 ms, mean=85.651 +- 0.0 ms
speedup 14.25x
krn_size (10, 12) img_size (460, 512)
conv2d_slow: Timed best=5.475 s, mean=5.475 +- 0.0 s
conv2d_medium: Timed best=552.321 ms, mean=552.321 +- 0.0 ms
speedup 9.91x
krn_size (14, 16) img_size (28, 32)
conv2d_slow: Timed best=7.463 ms, mean=7.463 +- 0.0 ms
conv2d_medium: Timed best=7.304 ms, mean=7.304 +- 0.0 ms
speedup 1.02x
krn_size (14, 16) img_size (57, 64)
conv2d_slow: Timed best=63.592 ms, mean=63.592 +- 0.0 ms
conv2d_medium: Timed best=11.538 ms, mean=11.538 +- 0.0 ms
speedup 5.51x
krn_size (14, 16) img_size (115, 128)
conv2d_slow: Timed best=268.824 ms, mean=268.824 +- 0.0 ms
conv2d_medium: Timed best=34.761 ms, mean=34.761 +- 0.0 ms
speedup 7.73x
krn_size (14, 16) img_size (230, 256)
conv2d_slow: Timed best=1.398 s, mean=1.398 +- 0.0 s
conv2d_medium: Timed best=153.959 ms, mean=153.959 +- 0.0 ms
speedup 9.08x
krn_size (14, 16) img_size (460, 512)
conv2d_slow: Timed best=6.059 s, mean=6.059 +- 0.0 s
conv2d_medium: Timed best=1.063 s, mean=1.063 +- 0.0 s
speedup 5.7x
krn_size (21, 24) img_size (28, 32)
conv2d_slow: Timed best=1.928 ms, mean=1.928 +- 0.0 ms
conv2d_medium: Timed best=10.410 ms, mean=10.410 +- 0.0 ms
speedup 0.19x
krn_size (21, 24) img_size (57, 64)
conv2d_slow: Timed best=43.078 ms, mean=43.078 +- 0.0 ms
conv2d_medium: Timed best=21.525 ms, mean=21.525 +- 0.0 ms
speedup 2.0x
krn_size (21, 24) img_size (115, 128)
conv2d_slow: Timed best=265.293 ms, mean=265.293 +- 0.0 ms
conv2d_medium: Timed best=47.004 ms, mean=47.004 +- 0.0 ms
speedup 5.64x
krn_size (21, 24) img_size (230, 256)
conv2d_slow: Timed best=1.384 s, mean=1.384 +- 0.0 s
conv2d_medium: Timed best=335.177 ms, mean=335.177 +- 0.0 ms
speedup 4.13x
krn_size (21, 24) img_size (460, 512)
conv2d_slow: Timed best=6.308 s, mean=6.308 +- 0.0 s
conv2d_medium: Timed best=2.224 s, mean=2.224 +- 0.0 s
speedup 2.84x
krn_size (1, 1) img_size (28, 32)
conv2d_slow: Timed best=16.040 ms, mean=16.287 +- 0.3 ms
conv2d_fast_numba: Timed best=31.285 us, mean=33.168 +- 1.6 us
speedup 491.05x
krn_size (1, 1) img_size (57, 64)
conv2d_slow: Timed best=63.740 ms, mean=65.235 +- 1.0 ms
conv2d_fast_numba: Timed best=41.062 us, mean=42.801 +- 4.1 us
speedup 1524.16x
krn_size (1, 1) img_size (115, 128)
conv2d_slow: Timed best=259.237 ms, mean=261.639 +- 2.9 ms
conv2d_fast_numba: Timed best=88.969 us, mean=98.746 +- 12.5 us
speedup 2649.63x
krn_size (1, 1) img_size (230, 256)
conv2d_slow: Timed best=1.046 s, mean=1.046 +- 0.0 s
conv2d_fast_numba: Timed best=406.715 us, mean=406.715 +- 0.0 us
speedup 2571.19x
krn_size (1, 1) img_size (460, 512)
conv2d_slow: Timed best=4.335 s, mean=4.335 +- 0.0 s
conv2d_fast_numba: Timed best=2.957 ms, mean=2.957 +- 0.0 ms
speedup 1465.91x
krn_size (1, 2) img_size (28, 32)
conv2d_slow: Timed best=14.989 ms, mean=15.260 +- 0.2 ms
conv2d_fast_numba: Timed best=34.707 us, mean=35.840 +- 0.8 us
speedup 425.79x
krn_size (1, 2) img_size (57, 64)
conv2d_slow: Timed best=60.887 ms, mean=61.745 +- 0.7 ms
conv2d_fast_numba: Timed best=46.440 us, mean=49.959 +- 5.4 us
speedup 1235.9x
krn_size (1, 2) img_size (115, 128)
conv2d_slow: Timed best=258.905 ms, mean=259.000 +- 0.1 ms
conv2d_fast_numba: Timed best=123.188 us, mean=139.320 +- 16.1 us
speedup 1859.04x
krn_size (1, 2) img_size (230, 256)
conv2d_slow: Timed best=1.040 s, mean=1.040 +- 0.0 s
conv2d_fast_numba: Timed best=547.991 us, mean=547.991 +- 0.0 us
speedup 1897.39x
krn_size (1, 2) img_size (460, 512)
conv2d_slow: Timed best=4.180 s, mean=4.180 +- 0.0 s
conv2d_fast_numba: Timed best=4.705 ms, mean=4.705 +- 0.0 ms
speedup 888.42x
krn_size (3, 3) img_size (28, 32)
conv2d_slow: Timed best=17.002 ms, mean=17.359 +- 0.3 ms
conv2d_fast_numba: Timed best=44.973 us, mean=45.853 +- 1.3 us
speedup 378.58x
krn_size (3, 3) img_size (57, 64)
conv2d_slow: Timed best=73.428 ms, mean=73.428 +- 0.0 ms
conv2d_fast_numba: Timed best=101.190 us, mean=101.190 +- 0.0 us
speedup 725.65x
krn_size (3, 3) img_size (115, 128)
conv2d_slow: Timed best=317.337 ms, mean=317.337 +- 0.0 ms
conv2d_fast_numba: Timed best=326.058 us, mean=326.058 +- 0.0 us
speedup 973.25x
krn_size (3, 3) img_size (230, 256)
conv2d_slow: Timed best=1.311 s, mean=1.311 +- 0.0 s
conv2d_fast_numba: Timed best=1.428 ms, mean=1.428 +- 0.0 ms
speedup 917.72x
krn_size (3, 3) img_size (460, 512)
conv2d_slow: Timed best=5.461 s, mean=5.461 +- 0.0 s
conv2d_fast_numba: Timed best=17.109 ms, mean=17.109 +- 0.0 ms
speedup 319.22x
......................
{kind=link}