问:如何加快这个过程?
以下是我实现的Matlab的im2col'滑动'函数,并增加了每n个列返回的功能。该函数接受一个图像(或任何二维数组),从左到右、从上到下地滑动,获取给定大小的每个重叠子图像,并返回其列数组。
import numpy as np
def im2col_sliding(image, block_size, skip=1):
rows, cols = image.shape
horz_blocks = cols - block_size[1] + 1
vert_blocks = rows - block_size[0] + 1
output_vectors = np.zeros((block_size[0] * block_size[1], horz_blocks * vert_blocks))
itr = 0
for v_b in xrange(vert_blocks):
for h_b in xrange(horz_blocks):
output_vectors[:, itr] = image[v_b: v_b + block_size[0], h_b: h_b + block_size[1]].ravel()
itr += 1
return output_vectors[:, ::skip]
例子:
a = np.arange(16).reshape(4, 4)
print a
print im2col_sliding(a, (2, 2)) # return every overlapping 2x2 patch
print im2col_sliding(a, (2, 2), 4) # return every 4th vector
返回:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
[[ 0. 1. 2. 4. 5. 6. 8. 9. 10.]
[ 1. 2. 3. 5. 6. 7. 9. 10. 11.]
[ 4. 5. 6. 8. 9. 10. 12. 13. 14.]
[ 5. 6. 7. 9. 10. 11. 13. 14. 15.]]
[[ 0. 5. 10.]
[ 1. 6. 11.]
[ 4. 9. 14.]
[ 5. 10. 15.]]
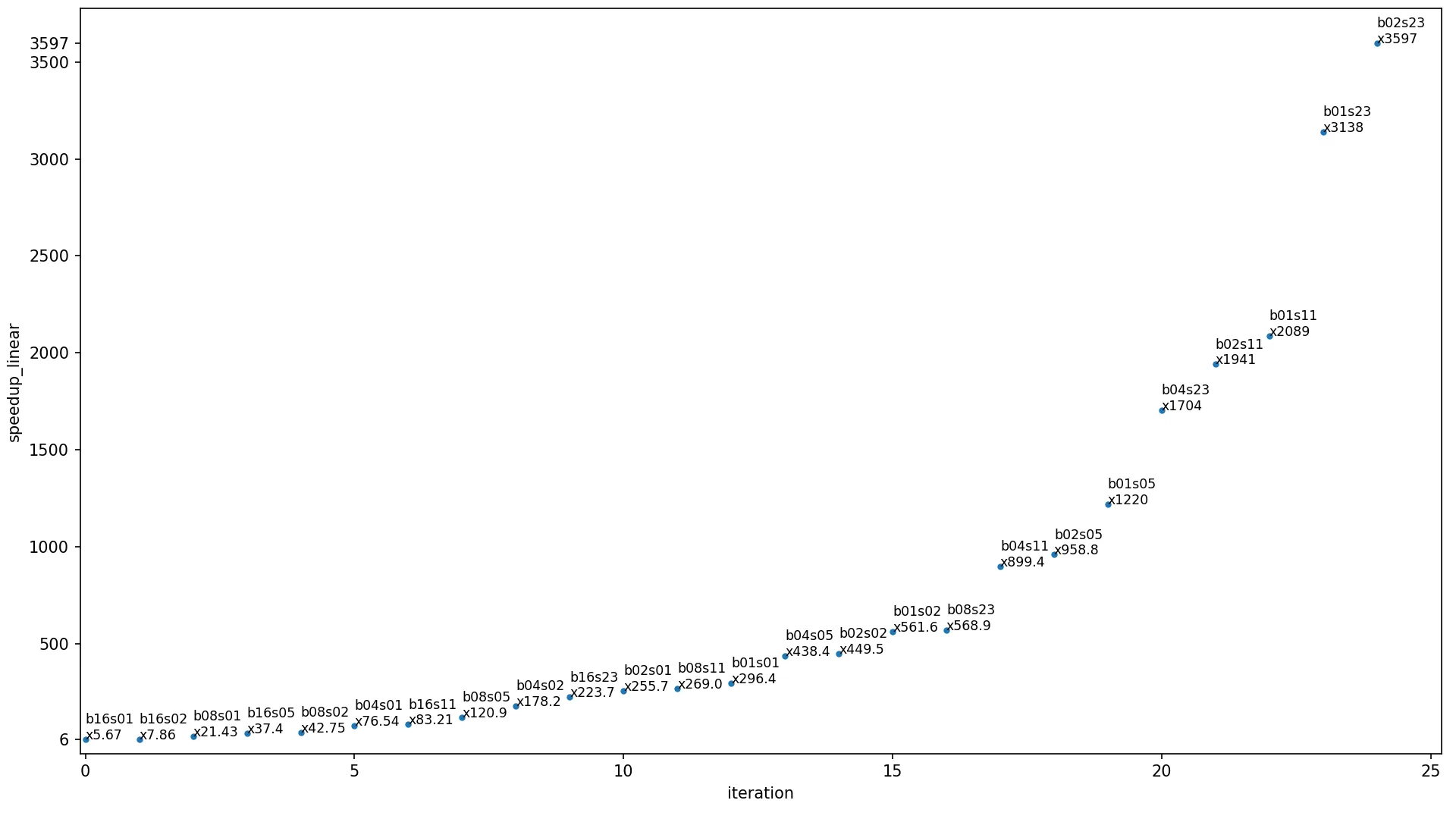
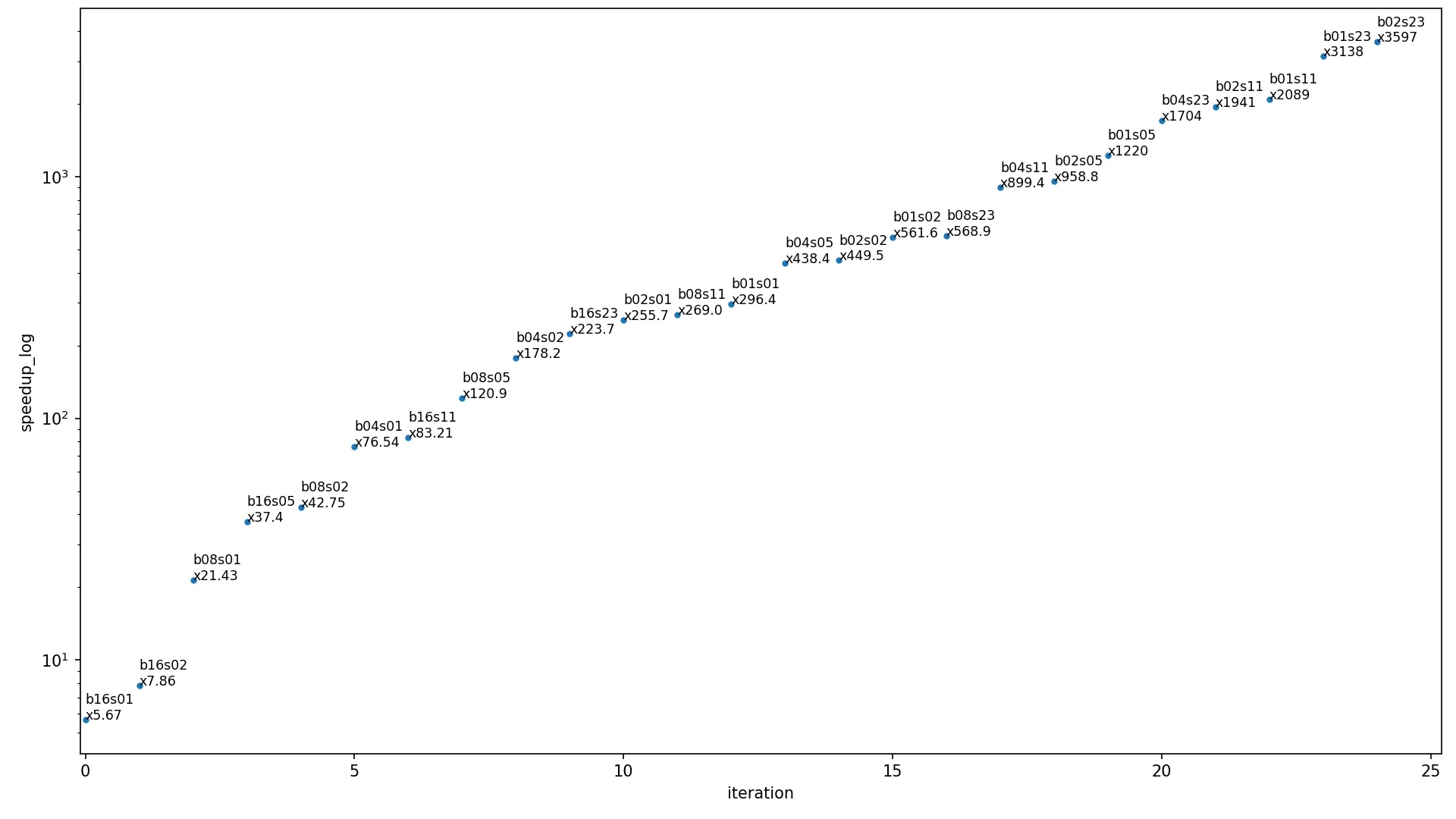
这个性能并不出色,特别是当我调用 im2col_sliding(big_matrix, (8, 8))(62001列)或者 im2col_sliding(big_matrix, (8, 8), 10)(6201列;只保留每10个向量),它们需要相同的时间 [其中big_matrix的大小为256 x 256]。
我正在寻找任何可以加速这个过程的想法。