我有一张处理过的验证码图片(放大后)如下:
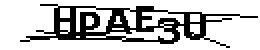 如您所见,“TEXT”字体大小比嘈杂线的宽度稍大。
如您所见,“TEXT”字体大小比嘈杂线的宽度稍大。
因此,我需要一个算法或代码来从这个图片中去除噪音线。
使用Python PIL库和下面提到的切割算法,我没有得到能够轻松被OCR读取的输出图像。
这是我尝试的Python代码:
如您所见,“TEXT”字体大小比嘈杂线的宽度稍大。因此,我需要一个算法或代码来从这个图片中去除噪音线。
使用Python PIL库和下面提到的切割算法,我没有得到能够轻松被OCR读取的输出图像。
这是我尝试的Python代码:
import PIL.Image
import sys
# python chop.py [chop-factor] [in-file] [out-file]
chop = int(sys.argv[1])
image = PIL.Image.open(sys.argv[2]).convert('1')
width, height = image.size
data = image.load()
# Iterate through the rows.
for y in range(height):
for x in range(width):
# Make sure we're on a dark pixel.
if data[x, y] > 128:
continue
# Keep a total of non-white contiguous pixels.
total = 0
# Check a sequence ranging from x to image.width.
for c in range(x, width):
# If the pixel is dark, add it to the total.
if data[c, y] < 128:
total += 1
# If the pixel is light, stop the sequence.
else:
break
# If the total is less than the chop, replace everything with white.
if total <= chop:
for c in range(total):
data[x + c, y] = 255
# Skip this sequence we just altered.
x += total
# Iterate through the columns.
for x in range(width):
for y in range(height):
# Make sure we're on a dark pixel.
if data[x, y] > 128:
continue
# Keep a total of non-white contiguous pixels.
total = 0
# Check a sequence ranging from y to image.height.
for c in range(y, height):
# If the pixel is dark, add it to the total.
if data[x, c] < 128:
total += 1
# If the pixel is light, stop the sequence.
else:
break
# If the total is less than the chop, replace everything with white.
if total <= chop:
for c in range(total):
data[x, y + c] = 255
# Skip this sequence we just altered.
y += total
image.save(sys.argv[3])
基本上,我想知道一个更好的算法/代码来消除噪声,以使图像可被OCR(Tesseract或pytesser)识别。