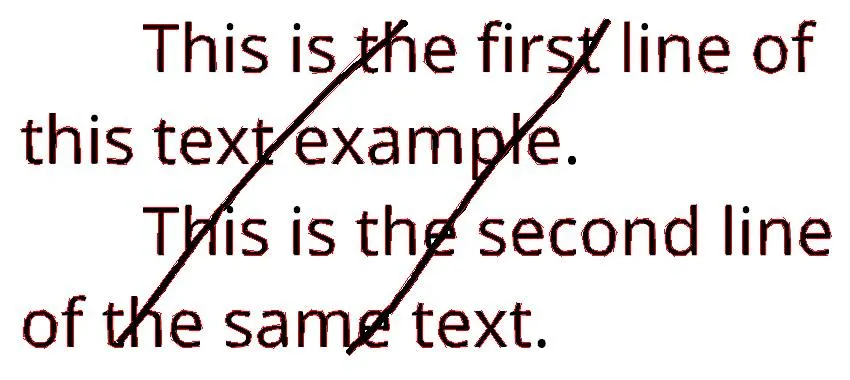我有一些图像,上面有一些随机线条噪声,比如下面这个:

我想对它们进行预处理,以便去除不需要的噪声(扭曲书写的线条),从而可以与OCR(Tesseract)一起使用。
我脑海中出现的想法是使用膨胀来去除噪声,然后在第二步中使用腐蚀来修复书写的缺失部分。
为此,我使用了这段代码:
import cv2
import numpy as np
img = cv2.imread('linee.png', cv2.IMREAD_GRAYSCALE)
kernel = np.ones((5, 5), np.uint8)
img = cv2.dilate(img, kernel, iterations=1)
img = cv2.erode(img, kernel, iterations=1)
cv2.imwrite('delatedtest.png', img)
遗憾的是,膨胀并没有奏效,噪声还存在。
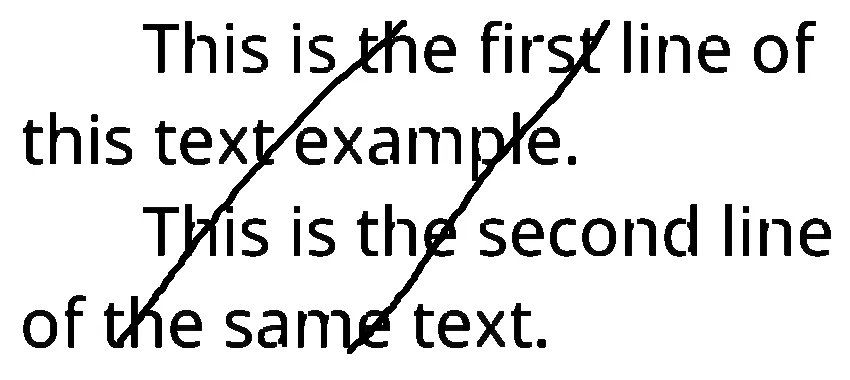
我尝试改变核形状,但情况变得更糟:部分或完全删除了文字。
我还发现一个答案说可以通过
将具有两个或更少相邻黑色像素的所有黑色像素转换为白色来消除这些线条。
对我来说似乎有点复杂,因为我是计算机视觉和opencv的初学者。
任何帮助将不胜感激,谢谢。