我有一个巨大的散点图(~100,000个点),是在 matplotlib 中生成的。每个点都有一个在 x/y 空间中的位置,我想生成包含总点数特定百分比的轮廓线。
在 matplotlib 中是否有可用的函数可以实现这个功能?我已经查看了 contour() 函数,但需要编写自己的函数才能按这种方式工作。
谢谢!
我有一个巨大的散点图(~100,000个点),是在 matplotlib 中生成的。每个点都有一个在 x/y 空间中的位置,我想生成包含总点数特定百分比的轮廓线。
在 matplotlib 中是否有可用的函数可以实现这个功能?我已经查看了 contour() 函数,但需要编写自己的函数才能按这种方式工作。
谢谢!
基本上,您想要某种密度估计。有多种方法可以实现:
使用某种二维直方图(例如matplotlib.pyplot.hist2d或matplotlib.pyplot.hexbin)(您也可以将结果显示为轮廓线-只需使用numpy.histogram2d然后轮廓线化结果数组)。
进行核密度估计(KDE)并绘制轮廓线。 KDE本质上是平滑的直方图。它不会让一个点落入特定的箱子中,而是向周围的箱子添加权重(通常呈高斯“钟形曲线”的形状)。
使用二维直方图简单易懂,但基本上提供“块状”结果。
执行第二个方法时可能会出现一些问题“正确”(即没有一种正确的方法)。我这里不会详细介绍,但如果您想统计地解释结果,则需要阅读相关资料(特别是带宽选择)。
无论如何,以下是差异的示例。我将以类似的方式绘制每个直方图,因此不会使用轮廓线,但您同样可以使用轮廓线绘制二维直方图或高斯KDE:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import kde
np.random.seed(1977)
# Generate 200 correlated x,y points
data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200)
x, y = data.T
nbins = 20
fig, axes = plt.subplots(ncols=2, nrows=2, sharex=True, sharey=True)
axes[0, 0].set_title('Scatterplot')
axes[0, 0].plot(x, y, 'ko')
axes[0, 1].set_title('Hexbin plot')
axes[0, 1].hexbin(x, y, gridsize=nbins)
axes[1, 0].set_title('2D Histogram')
axes[1, 0].hist2d(x, y, bins=nbins)
# Evaluate a gaussian kde on a regular grid of nbins x nbins over data extents
k = kde.gaussian_kde(data.T)
xi, yi = np.mgrid[x.min():x.max():nbins*1j, y.min():y.max():nbins*1j]
zi = k(np.vstack([xi.flatten(), yi.flatten()]))
axes[1, 1].set_title('Gaussian KDE')
axes[1, 1].pcolormesh(xi, yi, zi.reshape(xi.shape))
fig.tight_layout()
plt.show()
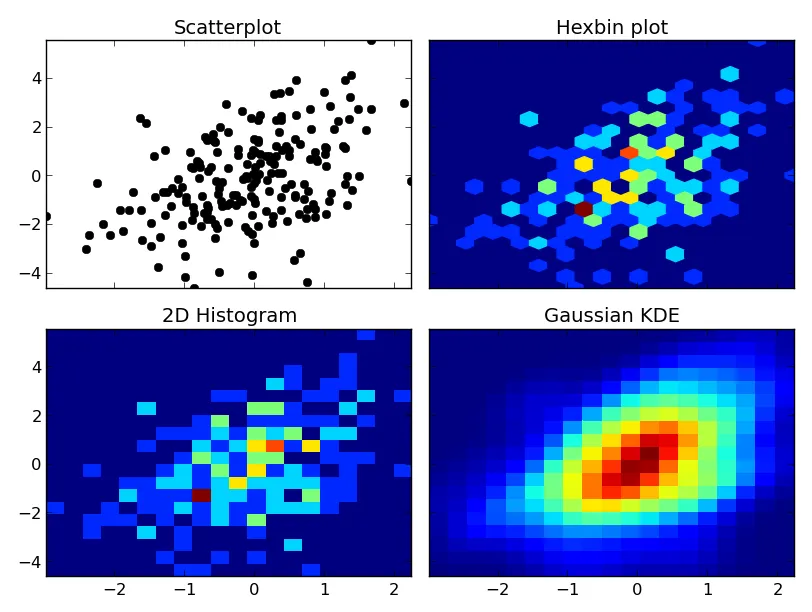
一个注意事项:当数据点数量非常大时,scipy.stats.gaussian_kde 的计算速度会变得非常缓慢。通过制作一个近似值来加速它非常容易——只需将二维直方图与正确半径和协方差的高斯滤波器模糊化即可。如果您需要,我可以提供一个示例。
还有一点需要注意:如果您正在使用非笛卡尔坐标系进行此操作,则上述方法都不适用!在球形壳上获取密度估计会变得更加复杂。
我有同样的问题。 如果你想要绘制包含某些点部分的轮廓线,可以使用以下算法:
创建二维直方图
h2, xedges, yedges = np.histogram2d(X, Y, bibs = [30, 30])
h2现在是一个包含整数的二维矩阵,表示某个矩形中点的数量。
hravel = np.sort(np.ravel(h2))[-1] #all possible cases for rectangles
hcumsum = np.sumsum(hravel)
让我们为h2 2d矩阵中的每个点给出包含数量等于或大于我们当前分析的点数的矩形的累积点数。
hunique = np.unique(hravel)
hsum = np.sum(h2)
for h in hunique:
h2[h2 == h] = hcumsum[np.argwhere(hravel == h)[-1]]/hsum
gaussian_kde的结果是概率密度函数(PDF)的估计值。因此,等高线值为0.1意味着90%的数据在等高线内部,依此类推。对于2D直方图,数值是原始计数,所以你需要进行归一化处理。希望这能稍微澄清一些事情。 - Joe Kingtonfast_kde函数:https://gist.github.com/joferkington/d95101a61a02e0ba63e5 - Joe Kington