已知高斯(正态)随机变量的均值和方差,我想计算其概率密度函数(PDF)。
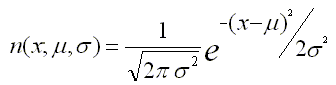
我参考了这篇文章:Calculate probability in normal distribution given mean, std in Python,
还有scipy文档:scipy.stats.norm
但是当我绘制曲线的PDF时,概率超过1!请参考此最小工作示例:
import numpy as np
import scipy.stats as stats
x = np.linspace(0.3, 1.75, 1000)
plt.plot(x, stats.norm.pdf(x, 1.075, 0.2))
plt.show()
我得到了什么:
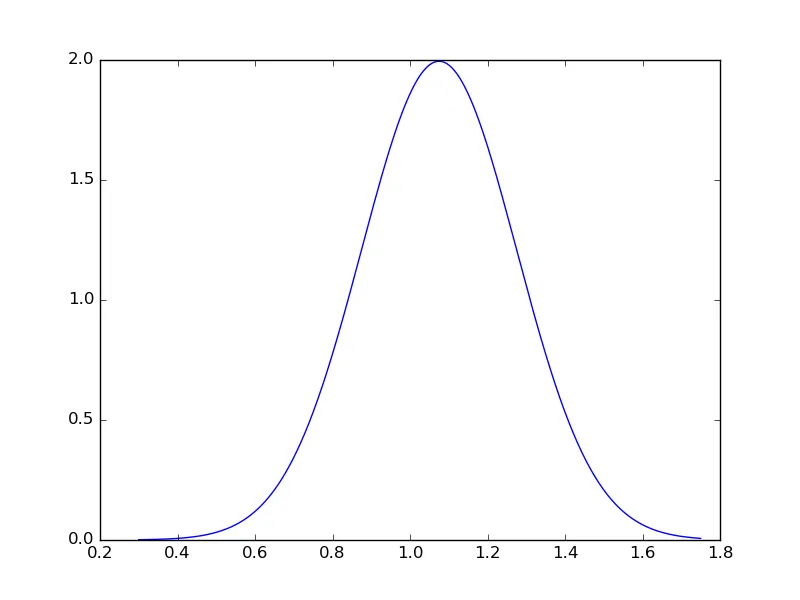
如何可能获得200%的概率得到平均值1.075?我是否在这里有任何误解?有没有办法纠正这个问题?
exp(-x**2/2)/sqrt(2*pi)。为了将mu和sigma引入关系中,分别引入了loc和scale。指定这些意味着用(x-loc)/scale替换x,并将最终结果除以scale,从而形成上述所述的高斯PDF。 - Ébe Isaac