有没有将2D视频转换为3D视频的算法(用眼镜观看)?
(就像将《阿凡达》转变为IMAX 3D体验一样。) 或者至少将其转变为适合进行一些3D观看的视频,如下所示:
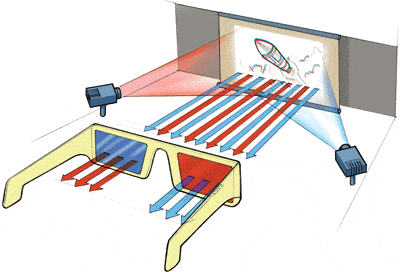
(来源: 3dglassesonline.com)
{kind=link}
或者
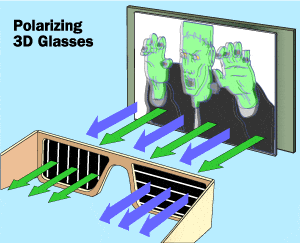
(来源: 3dglassesonline.com)
有没有将2D视频转换为3D视频的算法(用眼镜观看)?
(就像将《阿凡达》转变为IMAX 3D体验一样。) 或者至少将其转变为适合进行一些3D观看的视频,如下所示:
(来源: 3dglassesonline.com)
或者
(来源: 3dglassesonline.com)
嗯,斯坦福大学确实有一种算法将2D照片转换为3D模型。我想,对于电影来说应该更容易,因为你有多张照片而不仅仅是一张,所以通过比较相邻帧,可以提取关于深度的更多信息。
可以说,结果永远不会像从一开始就在3D中渲染/拍摄电影时那么好。
它通常无法正常工作的原因非常简单:假设你有一个场景,墙上有一个窗户,里面显示着一个海滩,旁边是一张照片,展示了一个墙上有窗户显示海滩的场景。算法怎么区分这两者呢?你如何检测现实中的深度和仅仅是平面照片之间的区别呢?
不,3D视频需要额外的信息(深度),而2D视频中根本没有这些信息。
如果你有一个场景的2D渲染图(例如《玩具总动员》中的场景),那么制作3D电影就很容易——你只需要改变场景的观看角度并重新渲染即可。
不完全是这样。算法应该如何理解场景内容并从中推断深度信息呢?请记住,3D视频需要深度信息。否则就无法知道两个帧部分要偏移多少。
您可以尝试将各种深度分配给各种程度的失焦,但我怀疑是否会产生可用的结果。
{kind=link}