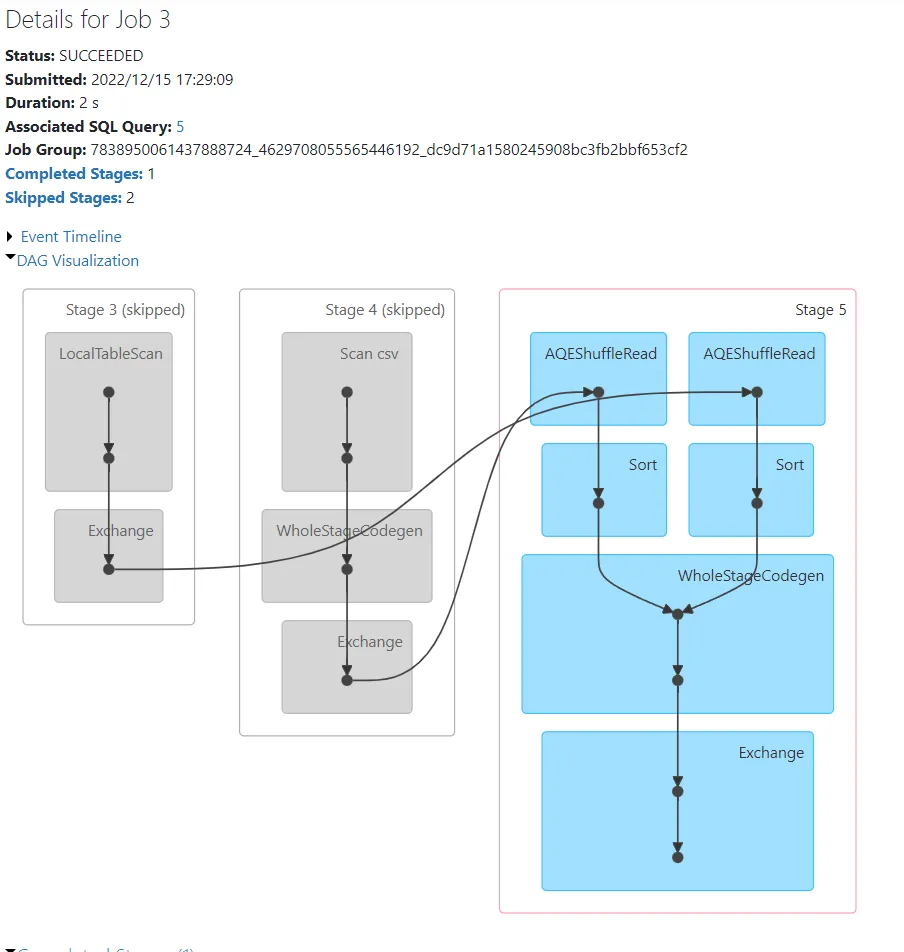
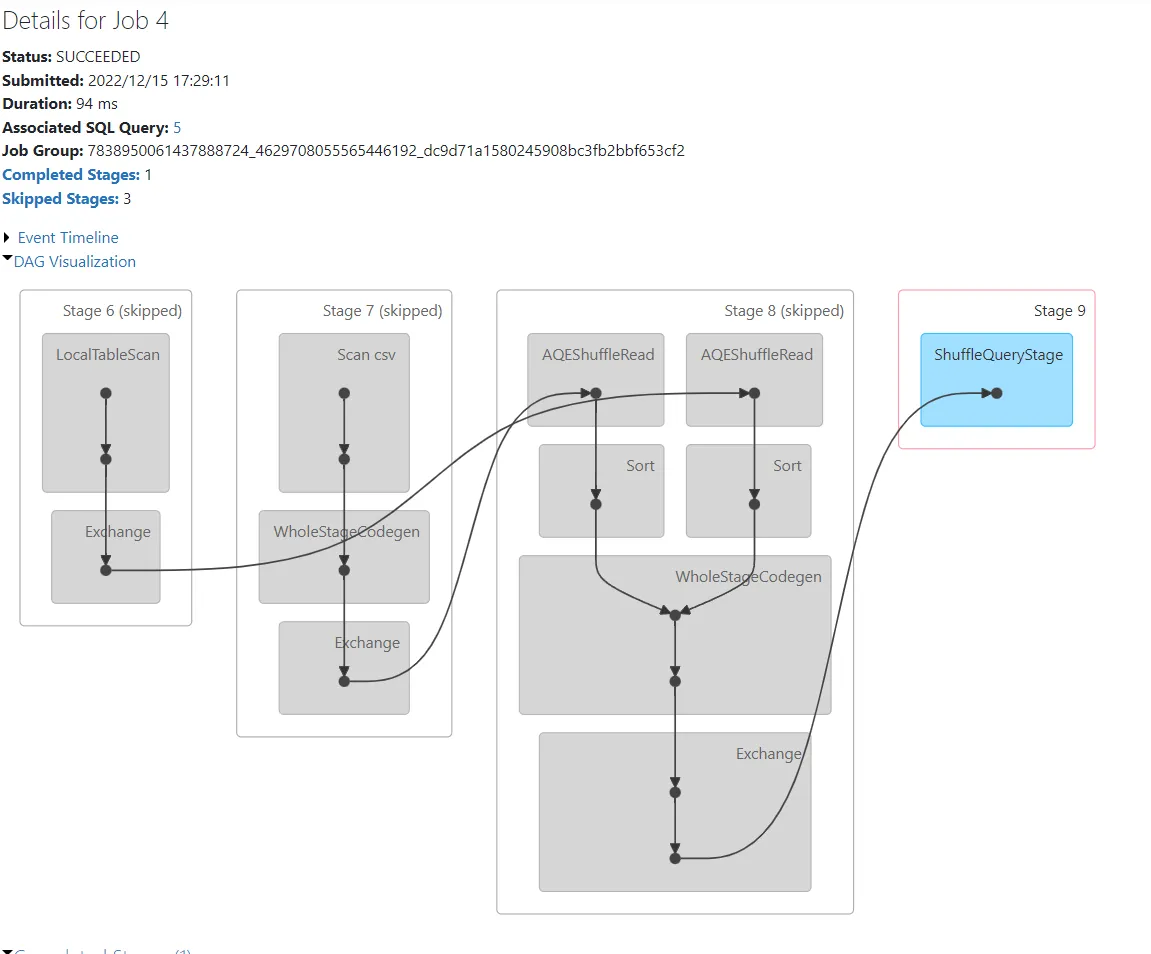
我在Spark的DAG中看到shufflequerystage框,它与Spark阶段中的excahnge框有何不同?请解释。
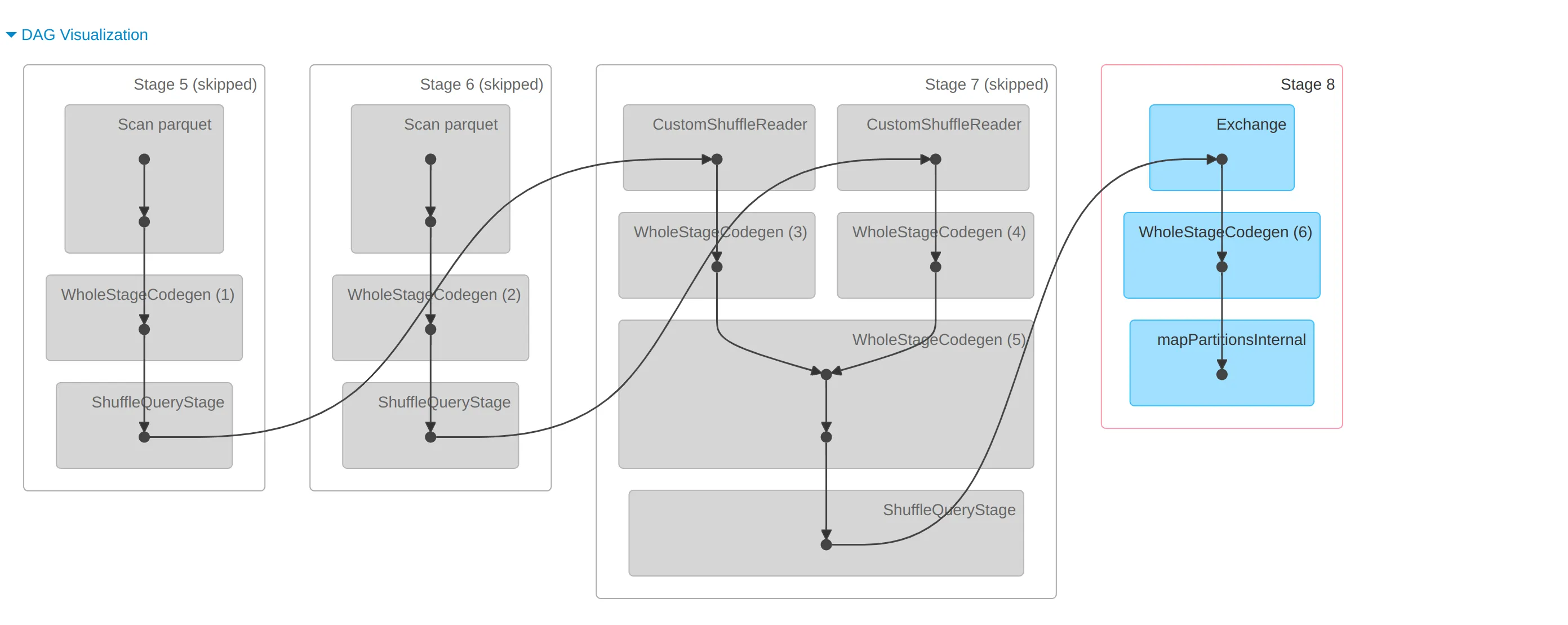
我在Spark的DAG中看到shufflequerystage框,它与Spark阶段中的excahnge框有何不同?请解释。
shufflequerystage的信息。case class ShuffleQueryStageExec(
override val id: Int,
override val plan: SparkPlan,
override val _canonicalized: SparkPlan) extends QueryStageExec {
...
}
所以ShuffleQueryStageExec扩展了QueryStageExec。让我们来看看QueryStageExec。代码注释很有启发性:
简而言之,查询阶段是查询计划的独立子图。查询阶段在继续查询计划的进一步操作之前,使其输出物质化。可以使用物化输出的数据统计信息来优化后续的查询阶段。
有两种类型的查询阶段:
- Shuffle查询阶段。该阶段将其输出物化到Shuffle文件中,并启动另一个作业来执行进一步的操作。
- Broadcast查询阶段。该阶段将其输出物化为驱动程序JVM中的数组。Spark在执行进一步的操作之前广播该数组。
ShuffleQueryStage是查询计划的一部分,其数据统计信息可用于优化后续查询阶段。这都是自适应查询执行(AQE)的一部分。有一些动作(收集,获取,跟踪,执行,...)会触发withFinalPlanUpdate函数,该函数又会触发getFinalPhysicalPlan函数。在这个函数中,会调用createQueryStages函数,这就是有趣的地方。
createQueryStages函数是一个递归函数,它遍历整个计划树,大致如下:
private def createQueryStages(plan: SparkPlan): CreateStageResult = plan match {
case e: Exchange =>
// First have a quick check in the `stageCache` without having to traverse down the node.
context.stageCache.get(e.canonicalized) match {
case Some(existingStage) if conf.exchangeReuseEnabled =>
...
case _ =>
val result = createQueryStages(e.child)
val newPlan = e.withNewChildren(Seq(result.newPlan)).asInstanceOf[Exchange]
// Create a query stage only when all the child query stages are ready.
if (result.allChildStagesMaterialized) {
var newStage = newQueryStage(newPlan)
...
}
Exchange并想要重复使用它,我们只需要这样做。但如果不是这种情况,我们将创建一个新的计划并调用newQueryStage函数。newQueryStagefunction的代码如下: private def newQueryStage(e: Exchange): QueryStageExec = {
val optimizedPlan = optimizeQueryStage(e.child, isFinalStage = false)
val queryStage = e match {
case s: ShuffleExchangeLike =>
...
ShuffleQueryStageExec(currentStageId, newShuffle, s.canonicalized)
case b: BroadcastExchangeLike =>
...
BroadcastQueryStageExec(currentStageId, newBroadcast, b.canonicalized)
}
...
}
ShuffleQueryStageExec!因此,对于每个尚未发生的Exchange,或者如果您不重用交换,则AQE将添加一个ShuffleQueryStageExec或一个BroadcastQueryStageExec。
希望这能让您更深入地了解它 :)import org.apache.spark.sql.functions._
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
spark.conf.set("spark.sql.adaptive.enabled", true)
val input = spark.read
.format("csv")
.option("header", "true")
.load(
"dbfs:/FileStore/shared_uploads/**@gmail.com/city_temperature.csv"
)
val dataForInput2 = Seq(
("Algeria", "3"),
("Germany", "3"),
("France", "5"),
("Poland", "7"),
("test55", "86")
)
val input2 = dataForInput2
.toDF("Country", "Value")
.withColumn("test", lit("test"))
val joinedDfs = input.join(input2, Seq("Country"))
val finalResult =
joinedDfs.filter(input("Country") === "Poland").repartition(200)
finalResult.show
== Physical Plan ==
CollectLimit (11)
+- Exchange (10)
+- * Project (9)
+- * SortMergeJoin Inner (8)
:- Sort (4)
: +- Exchange (3)
: +- * Filter (2)
: +- Scan csv (1)
+- Sort (7)
+- Exchange (6)
+- LocalTableScan (5)
== Physical Plan ==
AdaptiveSparkPlan (25)
+- == Final Plan ==
CollectLimit (16)
+- ShuffleQueryStage (15), Statistics(sizeInBytes=1447.8 KiB, rowCount=9.27E+3, isRuntime=true)
+- Exchange (14)
+- * Project (13)
+- * SortMergeJoin Inner (12)
:- Sort (6)
: +- AQEShuffleRead (5)
: +- ShuffleQueryStage (4), Statistics(sizeInBytes=1158.3 KiB, rowCount=9.27E+3, isRuntime=true)
: +- Exchange (3)
: +- * Filter (2)
: +- Scan csv (1)
+- Sort (11)
+- AQEShuffleRead (10)
+- ShuffleQueryStage (9), Statistics(sizeInBytes=56.0 B, rowCount=1, isRuntime=true)
+- Exchange (8)
+- LocalTableScan (7)