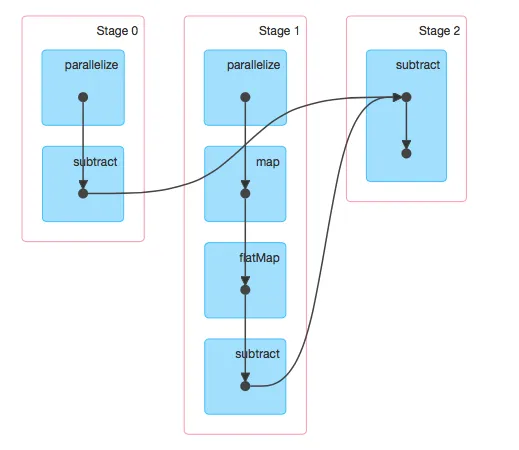
我想更好地了解Spark内部机制,但不确定如何解释作业的DAG结果。
受http://dev.sortable.com/spark-repartition/描述的示例启发,
我在Spark shell中运行以下代码,以获取从2到200万的质数列表。
现在我的问题是:我只调用了一次subtract函数,为什么DAG中会出现三次此操作? 此外,是否有任何教程可以解释一下Spark如何创建这些DAG? 提前致谢。
val n = 2000000
val composite = sc.parallelize(2 to n, 8).map(x => (x, (2 to (n / x)))).flatMap(kv => kv._2.map(_ * kv._1))
val prime = sc.parallelize(2 to n, 8).subtract(composite)
prime.collect()
执行后,我检查了SparkUI并观察了图中的DAG。现在我的问题是:我只调用了一次subtract函数,为什么DAG中会出现三次此操作? 此外,是否有任何教程可以解释一下Spark如何创建这些DAG? 提前致谢。