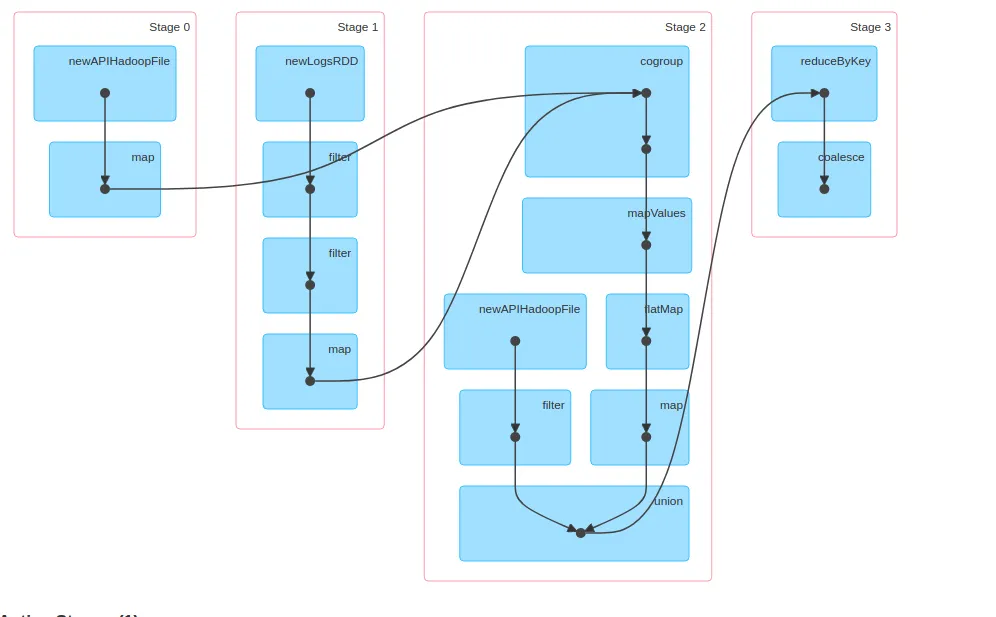
问题是我有以下DAG: 我认为当需要洗牌时,Spark将作业分为不同的阶段。考虑阶段0和阶段1。有些操作不需要洗牌。那么为什么Spark要将它们拆分成不同的阶段呢?我认为实际的跨分区数据移动应该发生在第2个阶段。因为这里我们需要。但是要,我们需要来自和的数据。因此,Spark保留这些阶段的中间结果,然后将其应用于吗?
你应该将一个“阶段”看作一系列在每个RDD的“分区”上执行的变换,而无需访问其他分区中的数据;换句话说,如果我可以创建一个操作T,该操作接收一个单个分区并生成一个新的(单个)分区,并将相同的T应用于RDD的每个分区-T可以由单个“阶段”执行。请注意,第0阶段和第1阶段对两个不同的RDD进行操作并执行不同的变换,因此它们不能共享相同的阶段。请注意,这两个阶段都不会操作其他阶段的输出-因此它们不适合创建单个阶段的“候选项”。请注意,这并不意味着它们无法“并行”运行:Spark可以安排同时运行这两个阶段;在这种情况下,“阶段2”(执行“cogroup”)将等待“阶段0”和“阶段1”完成,生成新的分区,将它们洗牌到正确的执行程序,然后对这些新分区进行操作。