Spark研究论文提出了一种新的分布式编程模型,替代了传统的Hadoop MapReduce,并宣称在许多情况下特别是在机器学习中简化了操作并显著提升了性能。然而,在这篇论文中,探索 具有有向无环图的弹性分布式数据集(RDD) 的内部机制似乎缺乏详细阐述。
是否通过研究源代码可以更好地了解它?
Spark研究论文提出了一种新的分布式编程模型,替代了传统的Hadoop MapReduce,并宣称在许多情况下特别是在机器学习中简化了操作并显著提升了性能。然而,在这篇论文中,探索 具有有向无环图的弹性分布式数据集(RDD) 的内部机制似乎缺乏详细阐述。
是否通过研究源代码可以更好地了解它?
即使我在网上寻找了解Spark如何从RDD计算DAG并随后执行任务的内容。
在高层次上,当RDD调用任何操作时,Spark创建DAG并将其提交给DAG调度程序。
DAG调度程序将运算符划分为任务阶段。一个阶段由基于输入数据的分区的任务组成。 DAG调度程序将运算符管道连接在一起。例如,许多map运算符可以在单个阶段中调度。 DAG调度程序的最终结果是一组阶段。
阶段传递给任务调度程序。任务调度程序通过群集管理器(Spark Standalone / Yarn / Mesos)启动任务。任务调度程序不知道阶段的依赖关系。
Worker在Slave上执行任务。
让我们来看看Spark如何构建DAG。
在高层次上,有两种转换可以应用到RDD上,即 narrow transformation 和wide transformation。 wide transformation 基本上会导致阶段边界。
narrow transformation - 不需要在分区之间传输数据。例如,Map、filter等。
wide transformation - 需要对数据进行洗牌,例如reduceByKey等。
让我们以计算每个严重性级别中出现多少日志消息为例,
以下是以严重性级别开头的日志文件,
INFO I'm Info message
WARN I'm a Warn message
INFO I'm another Info message
并创建以下 Scala 代码以提取相同内容,
val input = sc.textFile("log.txt")
val splitedLines = input.map(line => line.split(" "))
.map(words => (words(0), 1))
.reduceByKey{(a,b) => a + b}
这组命令隐式地定义了RDD对象的有向无环图(RDD lineage),在后面调用操作时会用到它。每个RDD都会保留一个指向其一或多个父级的指针,以及关于其与父级之间关系类型的元数据。例如,在RDD上调用val b = a.map()时,RDD b 会保留对其父级a的引用,这就是lineage。
为了显示RDD的lineage,Spark提供了一个调试方法toDebugString()。例如在splitedLines RDD上执行toDebugString(),将输出以下内容:
(2) ShuffledRDD[6] at reduceByKey at <console>:25 []
+-(2) MapPartitionsRDD[5] at map at <console>:24 []
| MapPartitionsRDD[4] at map at <console>:23 []
| log.txt MapPartitionsRDD[1] at textFile at <console>:21 []
| log.txt HadoopRDD[0] at textFile at <console>:21 []
第一行(从底部开始)显示输入的RDD。我们通过调用 sc.textFile() 创建了这个RDD。下面是给定RDD创建的DAG图的更具图表性的视图。

DAG构建完成后,Spark调度程序会创建一个物理执行计划。如上所述,DAG调度程序将根据转换将图形拆分为多个阶段,窄转换将被组合(管道化)为单个阶段。因此,对于我们的示例,Spark将创建以下两个阶段的执行:
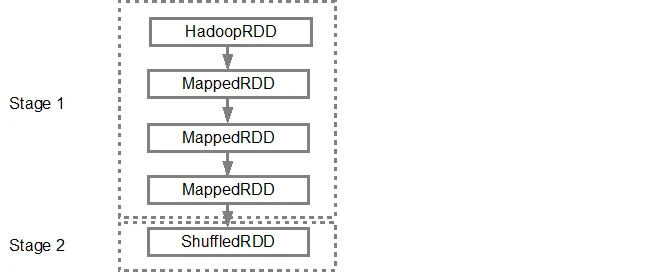
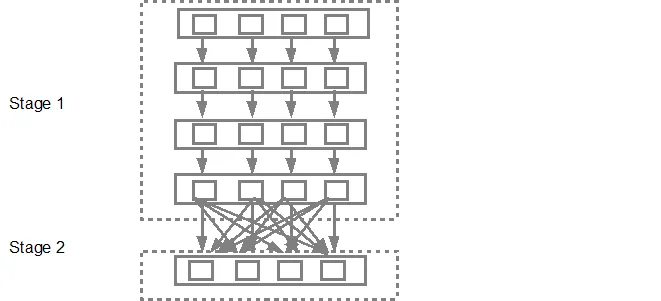
DAG调度程序随后将阶段提交到任务调度程序中。提交的任务数取决于textFile中存在的分区数。例如,在此示例中考虑我们有4个分区,那么将创建并提交4组任务,并行运行,前提是有足够的从节点/核心。下面的图表详细说明了这一点:
要获取更详细的信息,建议您观看以下YouTube视频,其中Spark的创建者详细介绍了DAG和执行计划以及生命周期。
从 Spark 1.4 版本开始,数据可视化功能通过以下三个组件实现,同时还提供了 DAG 的清晰图形表示。
Spark 事件的时间轴视图
执行 DAG
Spark Streaming 统计信息的可视化
更多信息请参见链接。