有人能解释一下RDD转换的结果是什么吗?它是新的数据集(数据的副本)还是仅是到旧数据块的过滤指针的新集合?
6个回答
13
RDD 转换允许您在 RDD 之间创建依赖关系。这些依赖关系是生成结果(程序)的步骤。每个 RDD 在血统链中(依赖关系的字符串)都有一个用于计算其数据的函数,以及指向其父 RDD 的指针(依赖项)。Spark 将把 RDD 依赖关系分成阶段和任务,并将它们发送到工作节点执行。
因此,如果您这样做:
val lines = sc.textFile("...")
val words = lines.flatMap(line => line.split(" "))
val localwords = words.collect()
words将是一个包含对lines RDD的引用的RDD。当程序被执行时,首先会执行lines函数(从文本文件中加载数据),然后在结果数据上执行words函数(将行拆分为单词)。Spark是惰性的,因此除非调用一些触发作业创建和执行的转换或操作(例如在此示例中使用collect),否则不会执行任何操作。
因此,一个RDD(包括转换后的RDD)不是“一组数据”,而是程序中的一步(可能是唯一的一步),告诉Spark如何获取数据以及要对其执行什么操作。
- pzecevic
2
转换操作是基于现有RDD创建新的RDD。基本上,RDD是不可变的。 Spark中的所有转换都是惰性的。RDD中的数据在执行操作之前不会被处理。
RDD转换的示例: map、filter、flatMap、groupByKey和reduceByKey。
- user1261215
1
这个答案并没有回答技术细节,比如当返回一个转换后的RDD时会发生什么(比如问题中的,它是一个指针还是其他什么?)。由于在执行操作之前什么也不会发生,那么返回的转换后的RDD有什么用呢?如果从未执行过任何操作,里面有什么呢? - jack
2
正如其他人所提到的,RDD(弹性分布式数据集)维护了一个列表,其中记录了程序应用的所有转换。这些转换是惰性计算的,因此尽管(例如在REPL中)您可能会得到一个参数类型不同的结果(例如应用地图后),但“新”的RDD还没有包含任何内容,因为没有强制原始RDD评估其谱系中的转换/过滤器。方法(如
count,各种缩减方法等)将导致应用传输。checkpoint方法也应用所有RDD操作,并返回一个结果为传输的RDD,但没有谱系(这可以是性能优势,特别是对于迭代应用)。- Timothy Perrigo
1
所有答案都是完全有效的。我只想添加一张快速图片 :-)
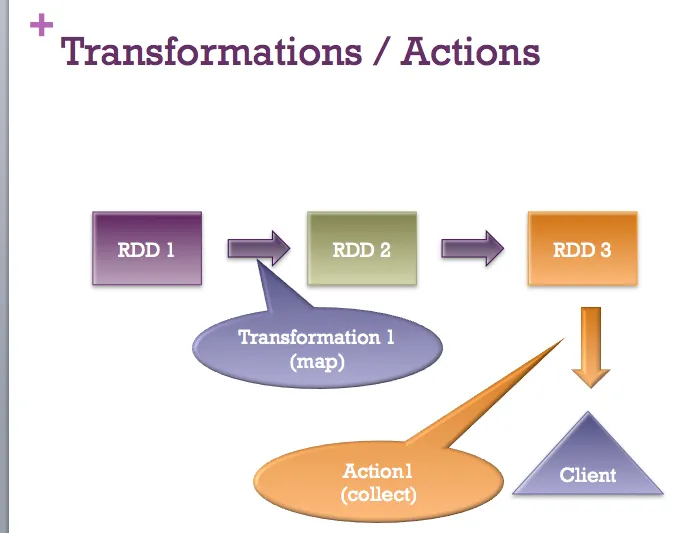
- Sujee Maniyam
1
转换操作是一种将RDD数据从一种形式转换为另一种形式的操作。当您在任何RDD上应用此操作时,您将获得具有转换数据的新RDD(Spark中的RDD是不可变的,记住吗?)。像map、filter、flatMap等操作都是转换操作。
现在需要注意的一点是,当您在任何RDD上应用转换操作时,它不会立即执行操作。它将使用应用的操作、源RDD和用于转换的函数创建一个DAG(有向无环图)。并且它将使用引用继续构建此图,直到您对最后一个排队的RDD应用任何操作操作。这就是为什么Spark中的转换是惰性的原因。
现在需要注意的一点是,当您在任何RDD上应用转换操作时,它不会立即执行操作。它将使用应用的操作、源RDD和用于转换的函数创建一个DAG(有向无环图)。并且它将使用引用继续构建此图,直到您对最后一个排队的RDD应用任何操作操作。这就是为什么Spark中的转换是惰性的原因。
- ROOT
1
其他回答已经给出了很好的解释。这里是我的一些想法:
为了更好地了解返回的RDD中有什么,最好检查RDD抽象类中的内容(引用自源代码):
内部,每个RDD都由五个主要属性来描述: - 一个分区列表 - 用于计算每个拆分的函数 - 依赖其他RDD的列表 - 可选地,用于键值RDD的Partitioner(例如,指定RDD是哈希分区的) - 可选地,每个拆分的首选位置列表(例如,HDFS文件的块位置)
为了更好地了解返回的RDD中有什么,最好检查RDD抽象类中的内容(引用自源代码):
内部,每个RDD都由五个主要属性来描述: - 一个分区列表 - 用于计算每个拆分的函数 - 依赖其他RDD的列表 - 可选地,用于键值RDD的Partitioner(例如,指定RDD是哈希分区的) - 可选地,每个拆分的首选位置列表(例如,HDFS文件的块位置)
- jack
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接