我知道Spark可以使用Scala、Python和Java操作,RDD用于存储数据。请解释一下Spark的架构以及它的内部工作原理。
3个回答
128
Spark围绕着弹性分布式数据集(RDD)的概念展开,这是一个容错的元素集合,可以并行操作。RDD支持两种类型的操作:转换操作(transformations),从现有数据集创建新的数据集;动作操作(actions),在数据集上运行计算后将值返回给驱动程序。
Spark将RDD转换操作称为有向无环图(DAG),并开始执行。
在高层次上,当RDD调用任何动作时,Spark会创建DAG并提交给DAG调度程序。
- DAG调度程序将操作符划分为任务阶段。阶段由基于输入数据的分区的任务组成。DAG调度器将操作符连锁起来。例如,许多映射操作符可以在单个阶段中调度。DAG调度程序的最终结果是一组阶段。 - 阶段被传递给任务调度程序。任务调度程序通过群集管理器(Spark Standalone/Yarn/Mesos)启动任务。任务调度程序不知道阶段之间的依赖关系。 - 工作者/从节点执行任务。
现在来看看Spark如何构建DAG。
这组命令隐式地定义了一个RDD对象的DAG(RDD血统),在调用操作时将使用它。每个RDD都维护着指向一个或多个父级的指针,以及关于它与父级之间关系类型的元数据。例如,当我们在RDD上调用
要显示RDD的血统,Spark提供了一个调试方法
第一行(从下往上)显示输入的RDD。我们通过调用
Spark将RDD转换操作称为有向无环图(DAG),并开始执行。
在高层次上,当RDD调用任何动作时,Spark会创建DAG并提交给DAG调度程序。
- DAG调度程序将操作符划分为任务阶段。阶段由基于输入数据的分区的任务组成。DAG调度器将操作符连锁起来。例如,许多映射操作符可以在单个阶段中调度。DAG调度程序的最终结果是一组阶段。 - 阶段被传递给任务调度程序。任务调度程序通过群集管理器(Spark Standalone/Yarn/Mesos)启动任务。任务调度程序不知道阶段之间的依赖关系。 - 工作者/从节点执行任务。
现在来看看Spark如何构建DAG。
在高级别上,可以对RDD应用两种转换,即窄转换和宽转换。宽转换基本上会导致阶段边界。
窄转换 - 不需要将数据在分区之间进行洗牌。例如,map,filter等。
宽转换 - 需要对数据进行洗牌,例如,reduceByKey等。
让我们举一个例子,统计每个严重级别的日志消息出现的次数。
以下是以严重级别开头的日志文件:
INFO I'm Info message
WARN I'm a Warn message
INFO I'm another Info message
并创建以下Scala代码以提取相同内容:
val input = sc.textFile("log.txt")
val splitedLines = input.map(line => line.split(" "))
.map(words => (words(0), 1))
.reduceByKey{(a,b) => a + b}
这组命令隐式地定义了一个RDD对象的DAG(RDD血统),在调用操作时将使用它。每个RDD都维护着指向一个或多个父级的指针,以及关于它与父级之间关系类型的元数据。例如,当我们在RDD上调用
val b = a.map()时,RDD b 会保留对其父级 a 的引用,这就是血统。要显示RDD的血统,Spark提供了一个调试方法
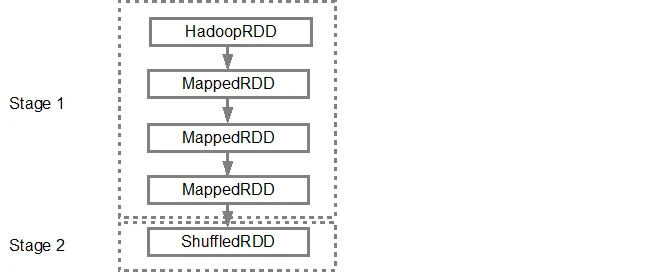
toDebugString()。例如,在splitedLines RDD上执行toDebugString(),将输出以下内容:(2) ShuffledRDD[6] at reduceByKey at <console>:25 []
+-(2) MapPartitionsRDD[5] at map at <console>:24 []
| MapPartitionsRDD[4] at map at <console>:23 []
| log.txt MapPartitionsRDD[1] at textFile at <console>:21 []
| log.txt HadoopRDD[0] at textFile at <console>:21 []
第一行(从下往上)显示输入的RDD。我们通过调用
sc.textFile()创建了这个RDD。请参见下面更详细的DAG图形,该图形是从给定的RDD创建的。

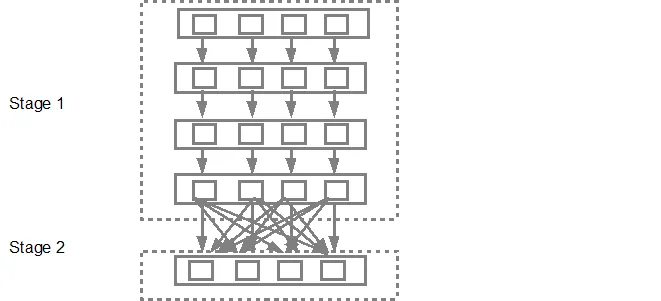
textFile中存在的分区数。例如,在此示例中考虑有4个分区,则将创建4组任务并并行提交,前提是有足够的从节点/核心。下图更详细地说明了这一点:
如果您需要更详细的信息,我建议您观看以下YouTube视频,其中Spark的创建者深入介绍了DAG、执行计划和生命周期。
- Sathish
6
嗨,Santish,我有一个快速的问题。您说reduceByKey是一种宽转换,因为它“需要对数据进行混洗”。您能详细解释一下混洗的含义吗?这是否意味着你只是在从不同的元组中添加值,所以你正在“混洗”数据? - user5041486
这应该给出一个非常详细的图形描述,说明什么是shuffle - https://databricks.gitbooks.io/databricks-spark-knowledge-base/content/best_practices/prefer_reducebykey_over_groupbykey.html - Sathish
@Sathish 很好的解释。 - PVH
讲解得非常清晰,但如果你想深入了解它在物理层面上是如何工作的,请参考此链接:https://jaceklaskowski.gitbooks.io/mastering-apache-spark/spark-DAGScheduler-Stage.html - siddhartha jain
嗨@Sathish,感谢您提供有关Spark在内部工作方面的所有细节;只有一个问题,您提供的视频已经超过7年了,您认为它们仍然可以作为Spark内部工作的良好参考,还是自那以后发生了很大变化?我对Spark相对较新,感谢您的帮助。 - Moein
这是一个很好的解释。谢谢! - ss301
3
下面的图表展示了Apache Spark内部的工作方式:
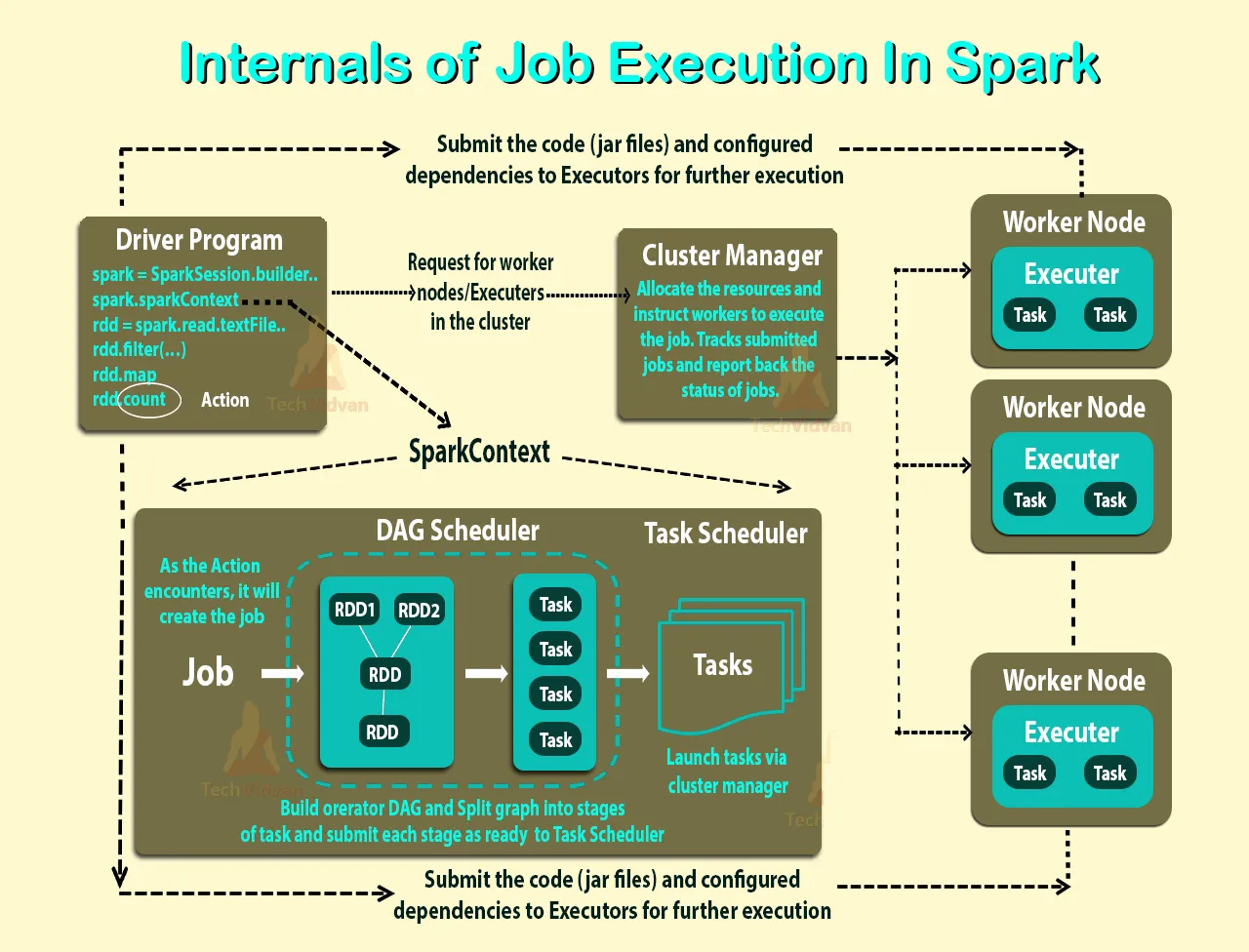
- Sharhabeel Hamdan
2
以下是我将要使用的 Apache Spark 术语:
作业:一段代码,从 HDFS 或本地读取一些输入数据,对数据执行一些计算,并写入一些输出数据。
阶段:作业被划分为多个阶段。阶段被分类为 Map 阶段或 Reduce 阶段(如果您曾经使用过 Hadoop 并且想进行关联,则更容易理解)。阶段基于计算边界进行划分,所有计算(运算符)不能在单个阶段中更新。这需要经过多个阶段来完成。
任务:每个阶段都有一些任务,每个分区一个任务。一个任务在一个执行器(机器)上执行一个数据分区。
DAG:DAG 指的是有向无环图,在当前上下文中,它是运算符的 DAG。
执行器:负责执行任务的进程。
驱动程序:负责在 Spark 引擎上运行作业的程序/进程。
主机:驱动程序运行的机器。
从机:执行器程序运行的机器。
Spark中的所有作业都由一系列操作符组成,并在一组数据上运行。作业中的所有操作符都用于构建DAG(有向无环图)。 DAG通过重新排列和组合操作符进行优化。例如,假设您必须提交一个包含映射操作后跟过滤操作的Spark作业。 Spark DAG优化器会重新排列这些操作符的顺序,因为过滤将减少需要执行映射操作的记录数。
Spark的代码库很小,系统分为各种层次。每个层次都有一些责任。这些层次彼此独立。
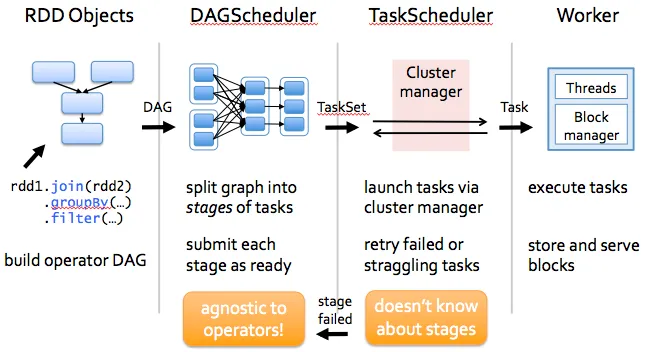
- 第一层是解释器,Spark使用Scala解释器,并进行了一些修改。
- 当您在Spark控制台中输入代码(创建RDD并应用运算符)时,Spark会创建一个运算符图。
- 当用户运行操作(如收集)时,该图被提交给DAG调度程序。DAG调度程序将运算符图分成(映射和归约)阶段。
- 阶段由基于输入数据的分区的任务组成。DAG调度程序将运算符连接在一起以优化图形。例如,许多映射运算符可以在单个阶段中安排。这种优化对于Spark的性能至关重要。DAG调度程序的最终结果是一组阶段。
- 阶段传递给任务调度程序。任务调度程序通过集群管理器( Spark Standalone/Yarn/Mesos)启动任务。任务调度程序不知道阶段之间的依赖关系。
- Worker在Slave上执行任务。每个JOB启动一个新的JVM。Worker只知道传递给它的代码。
Spark缓存要处理的数据,使其比Hadoop快100倍。Spark高度可配置,并且能够利用已经存在于Hadoop生态系统中的现有组件。这使得Spark呈指数增长,在很短的时间内,许多组织已经在生产中使用它。
- Arush Kharbanda
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接