假设我有两个DataFrame,分别是df1和df2
我会先进行一个join操作,然后再进行一个coalesce操作。
df1.join(df2, Seq("id")).coalesce(1)
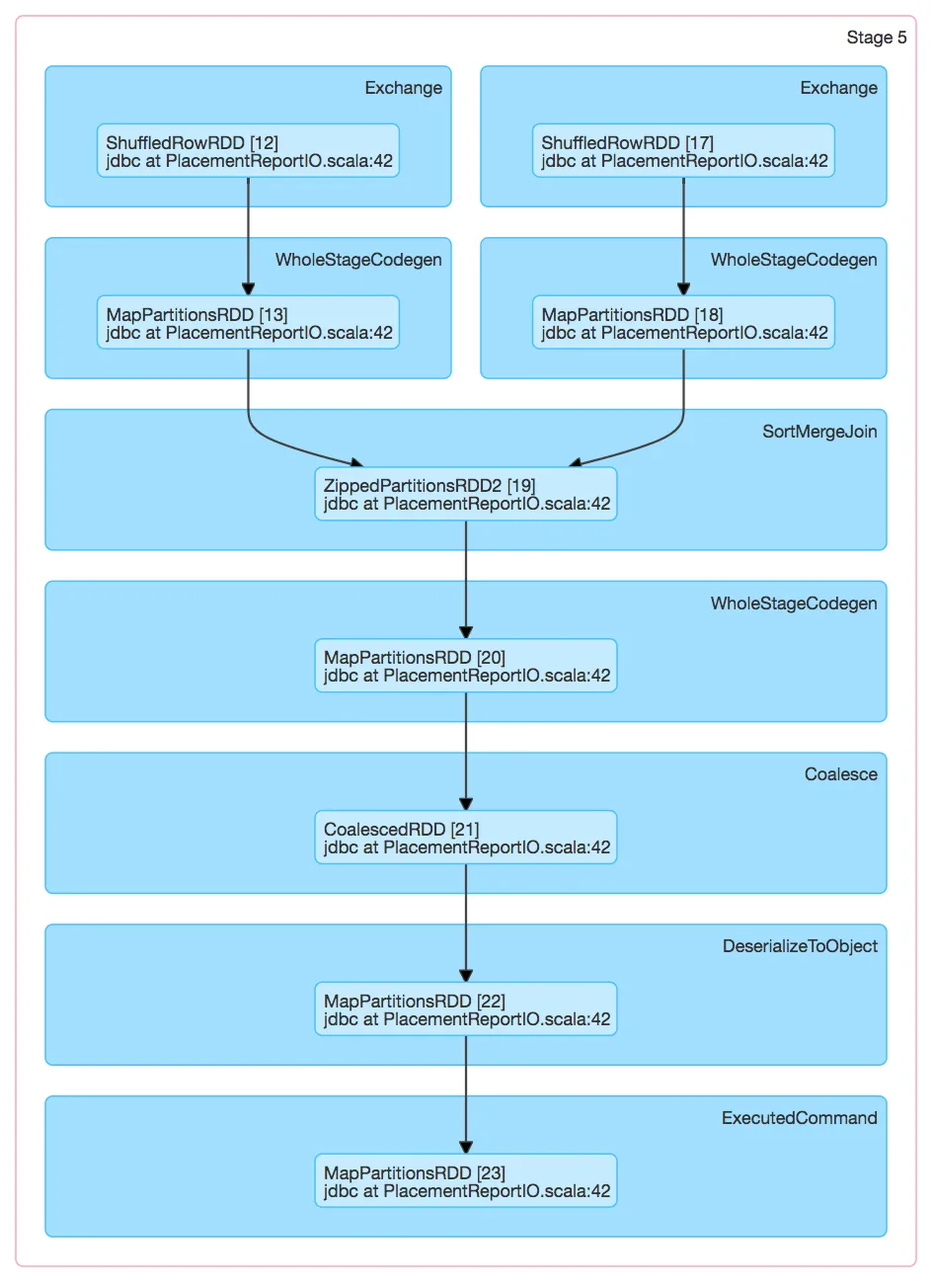
看起来Spark创建了2个阶段,第二个阶段中发生SortMergeJoin的计算只由一个任务执行。
因此,这个唯一的任务需要将两个完整的数据集都存储在内存中(参考:http://spark.apache.org/docs/latest/tuning.html#memory-usage-of-reduce-tasks)。
你能确认吗?
(我本来以为排序会使用spark.sql.shuffle.partitions设置,并有第三个额外的阶段执行合并操作。)
参考DAG