我正在尝试用Python而不是R来重现此网站上的此绘图:
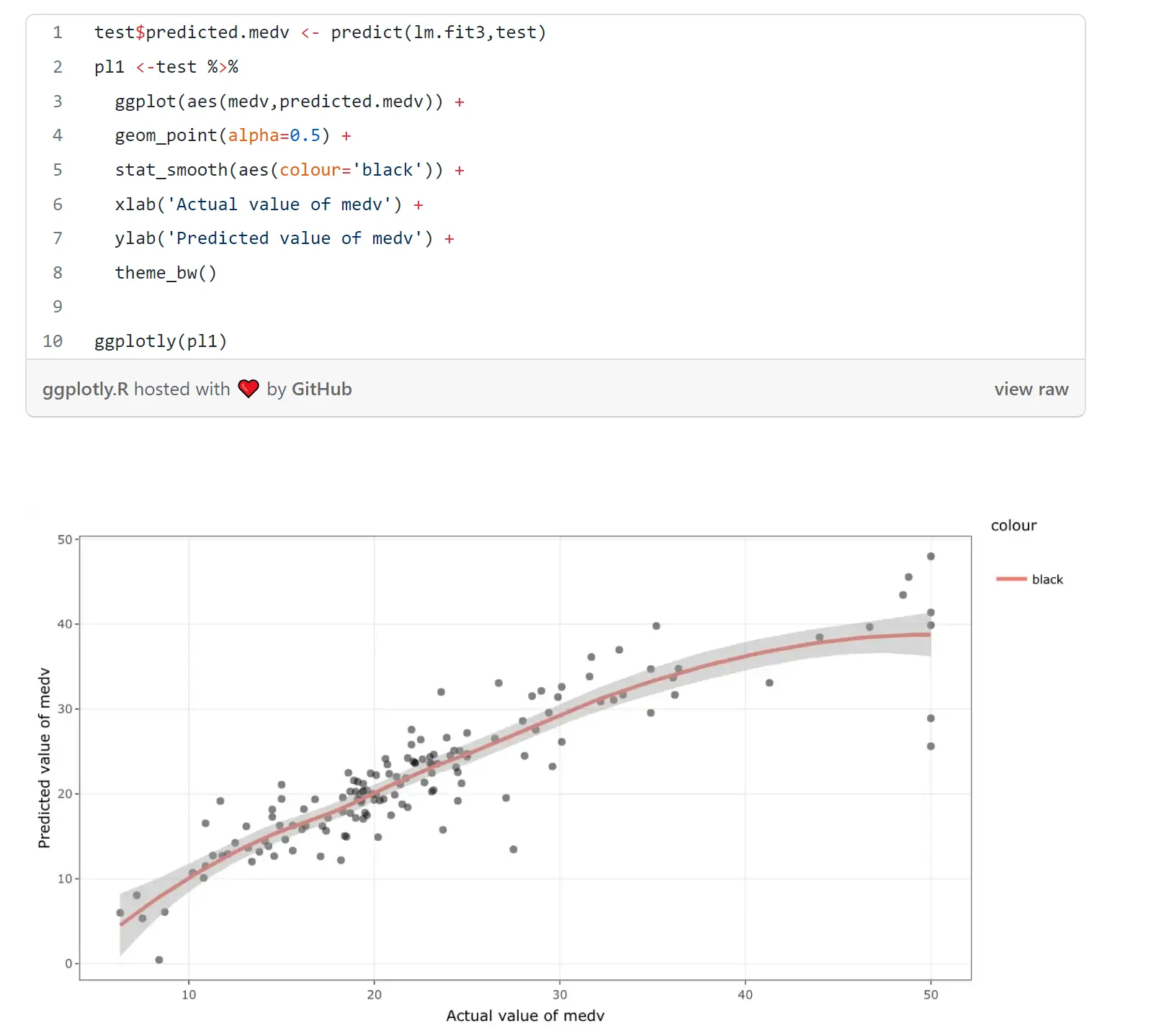
背景
我有一个叫做boston(流行的波士顿房屋教育数据集)的数据框。
我使用statsmodels API创建了一个带有一些变量的多元线性回归模型。 一切正常。
import statsmodels.formula.api as smf
results = smf.ols('medv ~ col1 + col2 + ...', data=boston).fit()
我从波士顿数据集中创建出一个数据帧,其中包括实际值和上述线性回归模型所预测的值。
new_df = pd.concat([boston['medv'], results.fittedvalues], axis=1, keys=['actual', 'predicted'])
这就是我卡住的地方。当我试图在散点图上绘制回归线时,出现了下面的错误。
from statsmodels.graphics.regressionplots import abline_plot
# scatter-plot data
ax = new_df.plot(x='actual', y='predicted', kind='scatter')
# plot regression line
abline_plot(model_results=results, ax=ax)
ValueError Traceback (most recent call last)
<ipython-input-156-ebb218ba87be> in <module>
5
6 # plot regression line
----> 7 abline_plot(model_results=results, ax=ax)
/usr/local/lib/python3.8/dist-packages/statsmodels/graphics/regressionplots.py in abline_plot(intercept, slope, horiz, vert, model_results, ax, **kwargs)
797
798 if model_results:
--> 799 intercept, slope = model_results.params
800 if x is None:
801 x = [model_results.model.exog[:, 1].min(),
ValueError: too many values to unpack (expected 2)
以下是我在线性回归中使用的自变量:
{'crim': {0: 0.00632, 1: 0.02731, 2: 0.02729, 3: 0.03237, 4: 0.06905},
'chas': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0},
'nox': {0: 0.538, 1: 0.469, 2: 0.469, 3: 0.458, 4: 0.458},
'rm': {0: 6.575, 1: 6.421, 2: 7.185, 3: 6.998, 4: 7.147},
'dis': {0: 4.09, 1: 4.9671, 2: 4.9671, 3: 6.0622, 4: 6.0622},
'tax': {0: 296, 1: 242, 2: 242, 3: 222, 4: 222},
'ptratio': {0: 15.3, 1: 17.8, 2: 17.8, 3: 18.7, 4: 18.7},
'lstat': {0: 4.98, 1: 9.14, 2: 4.03, 3: 2.94, 4: 5.33},
'rad3': {0: 0, 1: 0, 2: 0, 3: 1, 4: 1},
'rad4': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0},
'rad5': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0},
'rad6': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0},
'rad7': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0},
'rad8': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0},
'rad24': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0},
'dis_sq': {0: 16.728099999999998,
1: 24.67208241,
2: 24.67208241,
3: 36.75026884,
4: 36.75026884},
'lstat_sq': {0: 24.800400000000003,
1: 83.53960000000001,
2: 16.240900000000003,
3: 8.6436,
4: 28.4089},
'nox_sq': {0: 0.28944400000000003,
1: 0.21996099999999996,
2: 0.21996099999999996,
3: 0.209764,
4: 0.209764},
'rad24_lstat': {0: 0.0, 1: 0.0, 2: 0.0, 3: 0.0, 4: 0.0},
'rm_lstat': {0: 32.743500000000004,
1: 58.687940000000005,
2: 28.95555,
3: 20.57412,
4: 38.09351},
'rm_rad24': {0: 0.0, 1: 0.0, 2: 0.0, 3: 0.0, 4: 0.0}}
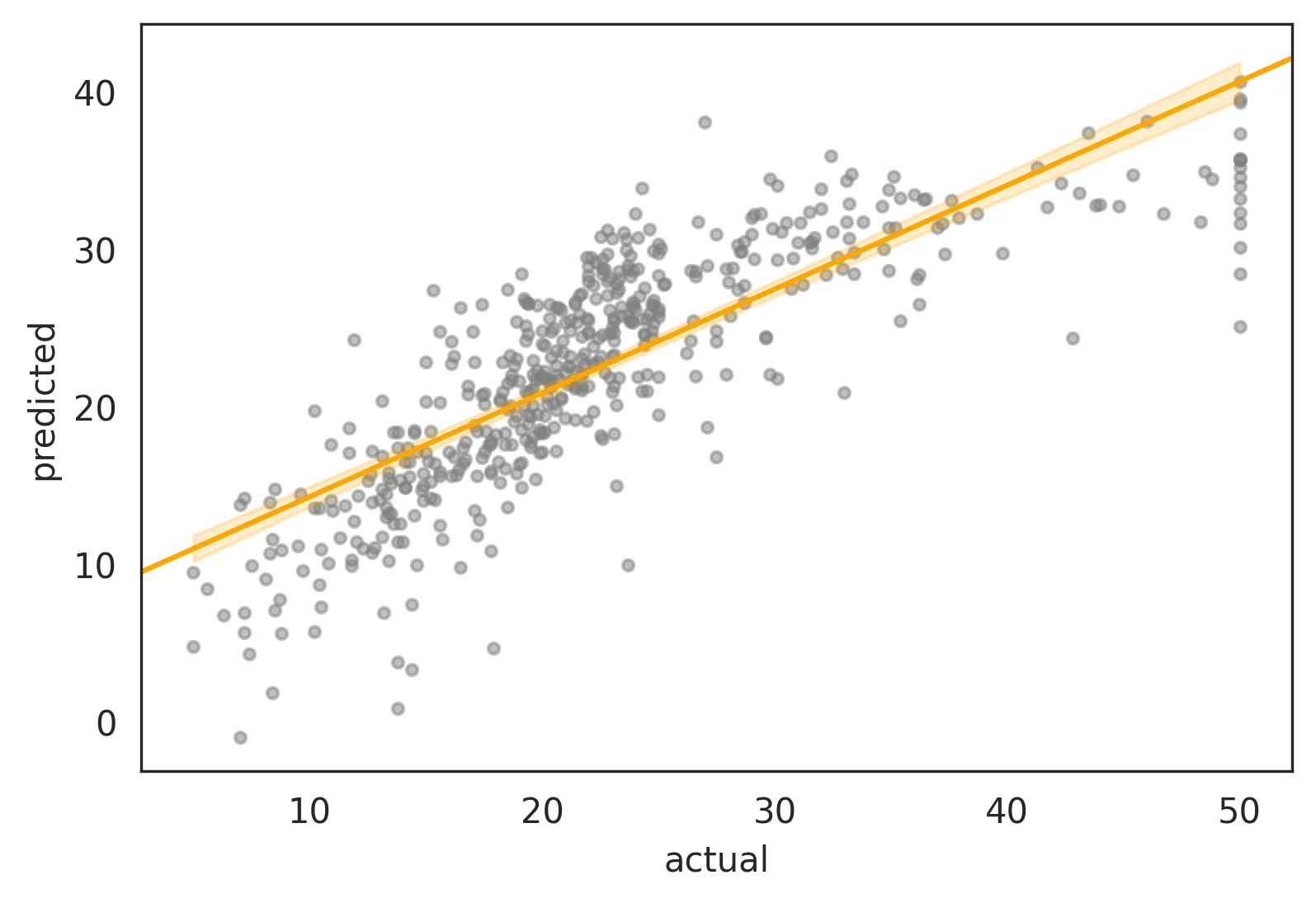
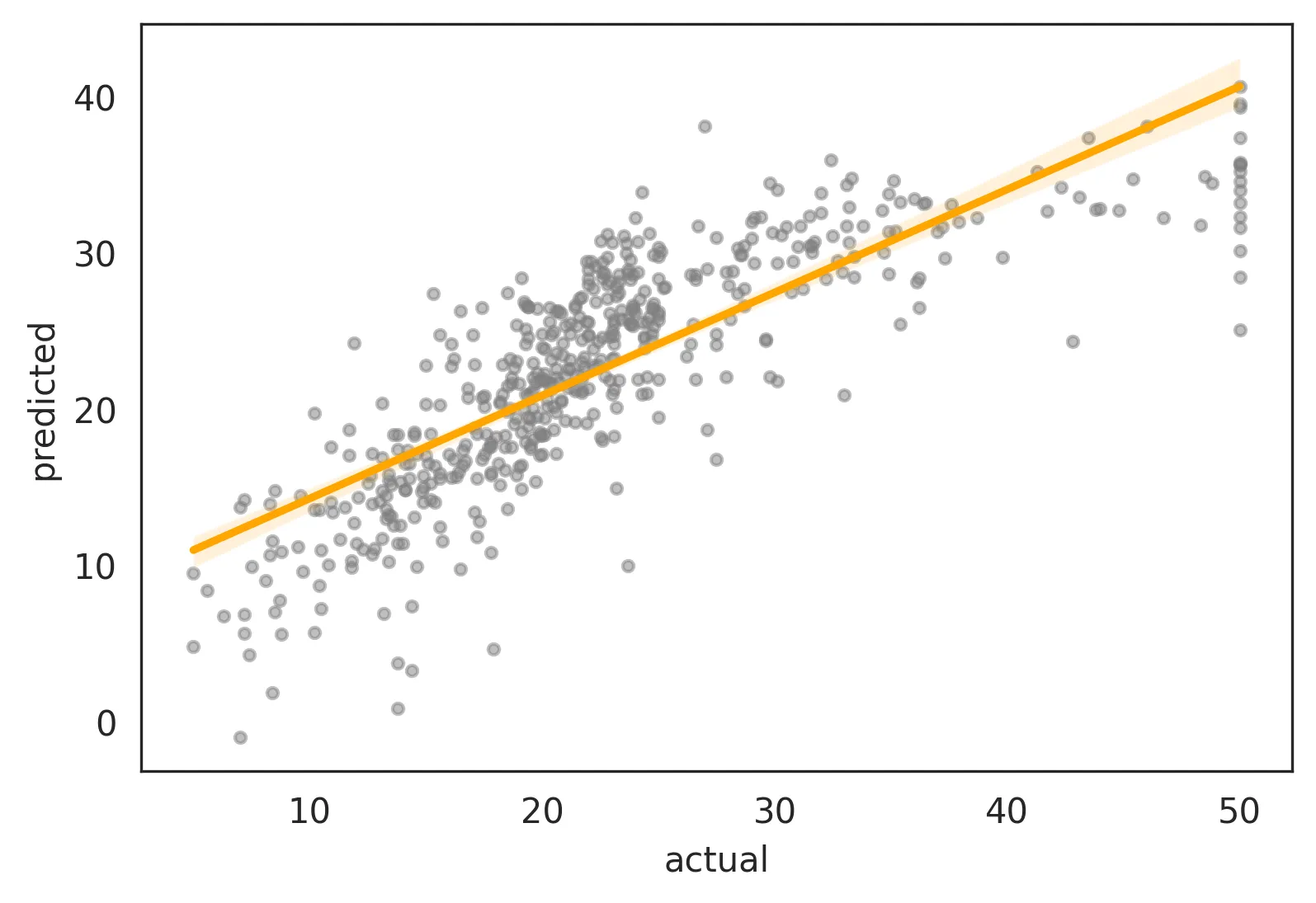
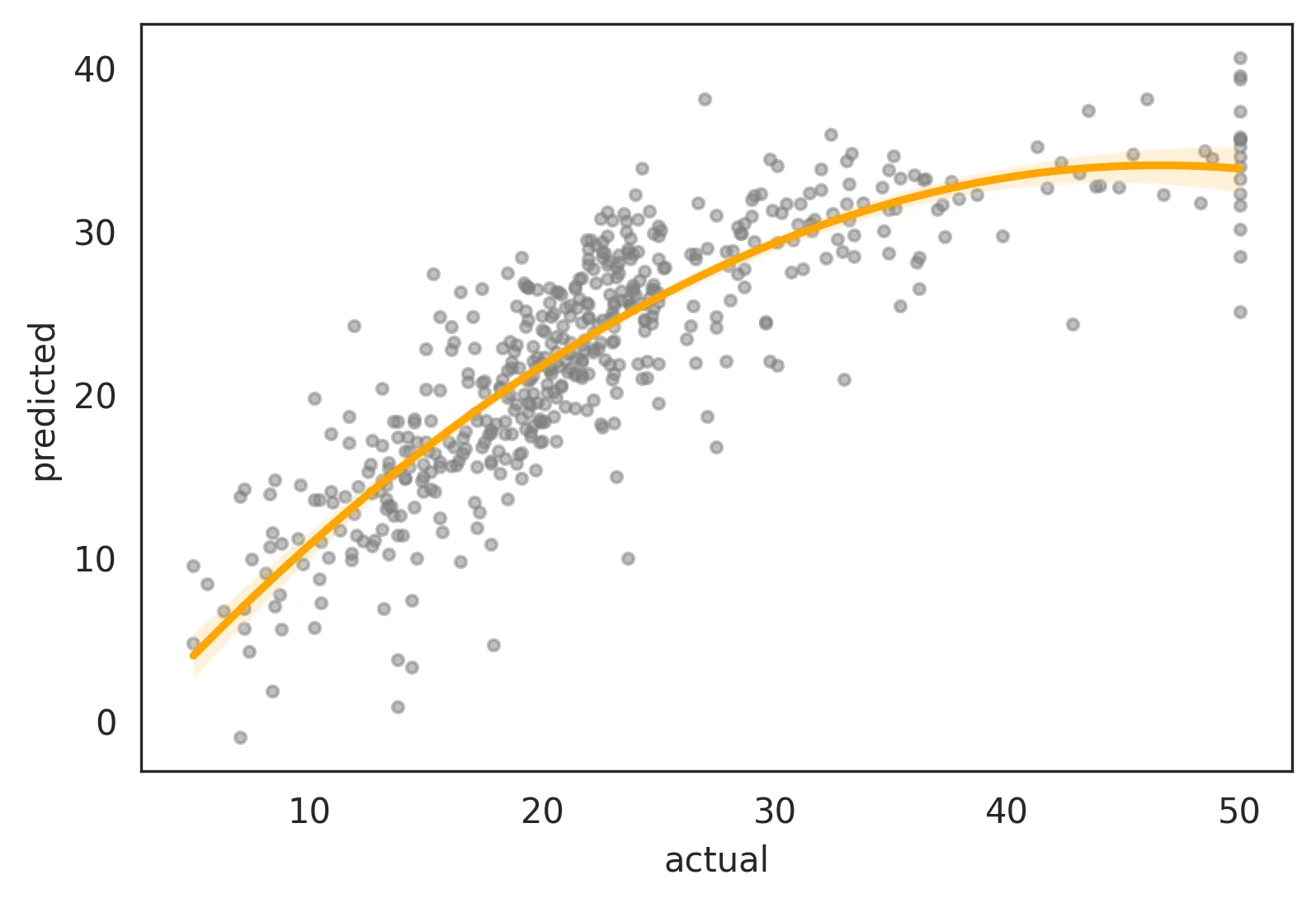
y=x直线。 - Katsu