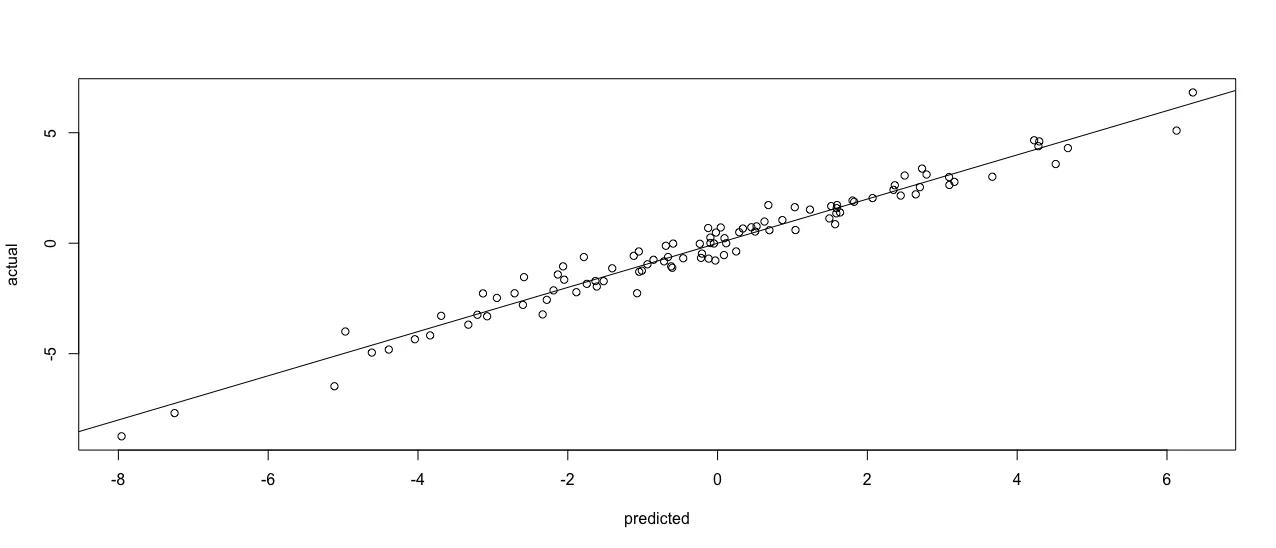
一种整洁的方法是使用modelsummary::augment()函数:
library(tidyverse)
library(cowplot)
library(modelsummary)
set.seed(101)
dd <- data.frame(x=rnorm(100),y=rnorm(100),
z=rnorm(100))
dd$w <- with(dd,rnorm(100,mean=x+2*y+z,sd=0.5))
m <- lm(w~x+y+z,dd)
m %>% augment() %>%
ggplot() +
geom_point(aes(.fitted, w)) +
geom_smooth(aes(.fitted, w), method = "lm", se = FALSE, color = "lightgrey") +
labs(x = "Actual", y = "Fitted") +
theme_bw()
这对于深度嵌套的回归列表尤其有效。
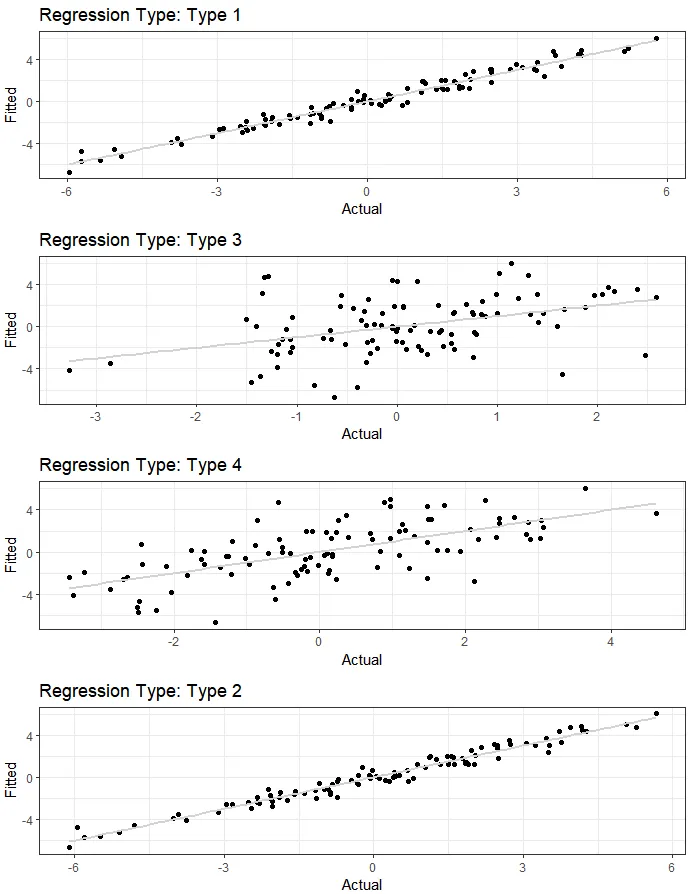
为了说明这一点,考虑一些嵌套的回归列表:
Reglist <- list()
Reglist$Reg1 <- dd %>% do(reg = lm(as.formula("w~x*y*z"), data = .)) %>% mutate( Name = "Type 1")
Reglist$Reg2 <- dd %>% do(reg = lm(as.formula("w~x+y*z"), data = .)) %>% mutate( Name = "Type 2")
Reglist$Reg3 <- dd %>% do(reg = lm(as.formula("w~x"), data = .)) %>% mutate( Name = "Type 3")
Reglist$Reg4 <- dd %>% do(reg = lm(as.formula("w~x+z"), data = .)) %>% mutate( Name = "Type 4")
现在,以上整洁的绘图框架的强大之处就得以体现...
Graph_Creator <- function(Reglist){
Reglist %>% pull(reg) %>% .[[1]] %>% augment() %>%
ggplot() +
geom_point(aes(.fitted, w)) +
geom_smooth(aes(.fitted, w), method = "lm", se = FALSE, color = "lightgrey") +
labs(x = "Actual", y = "Fitted",
title = paste0("Regression Type: ", Reglist$Name) ) +
theme_bw()
}
Reglist %>% map(~Graph_Creator(.)) %>%
cowplot::plot_grid(plotlist = ., ncol = 1)
abline和plot进一步阅读: https://stat.ethz.ch/pipermail/r-help//2013-February/347479.html - nilsole