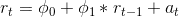我有一个包含五年时间序列的.csv文件,分辨率为每小时(商品价格)。基于历史数据,我想创建第六年价格的预测。
我已经阅读了一些关于这些过程的文章,并且基本上根据那里发布的代码编写了我的代码,因为我对Python(特别是statsmodels)和统计知识的了解非常有限。
以下是链接,供有兴趣的人使用:
为了做到这一点,在数据框中创建了额外的行,如下所示:
最后,当我使用statsmodels的.predict函数时:
我得到的预测结果是一条直线(见下文),这似乎完全不像一个预测。此外,如果我将范围扩展到整个6年时间跨度(2011-2016年),现在从第1825天到第2192天(2016年),预测线在整个期间都是一条直线。
我还尝试使用“statsmodels.tsa.statespace.sarimax.SARIMAX.predict”方法,该方法考虑了季节变化(在这种情况下是有意义的),但我遇到了关于“模块”没有属性“SARIMAX”的错误。但这是次要问题,如果需要可以深入讨论。
我已经阅读了一些关于这些过程的文章,并且基本上根据那里发布的代码编写了我的代码,因为我对Python(特别是statsmodels)和统计知识的了解非常有限。
以下是链接,供有兴趣的人使用:
http://www.seanabu.com/2016/03/22/time-series-seasonal-ARIMA-model-in-python/
http://www.johnwittenauer.net/a-simple-time-series-analysis-of-the-sp-500-index/
首先,这里是一个.csv文件的样本。在这种情况下,数据以每月的分辨率显示,这不是真实数据,只是随机选择的数字,以便在此处提供示例(在这种情况下,我希望一年足以开发第二年的预测;如果不行,则完整的csv文件可用):
Price
2011-01-31 32.21
2011-02-28 28.32
2011-03-31 27.12
2011-04-30 29.56
2011-05-31 31.98
2011-06-30 26.25
2011-07-31 24.75
2011-08-31 25.56
2011-09-30 26.68
2011-10-31 29.12
2011-11-30 33.87
2011-12-31 35.45
我的当前进度如下:
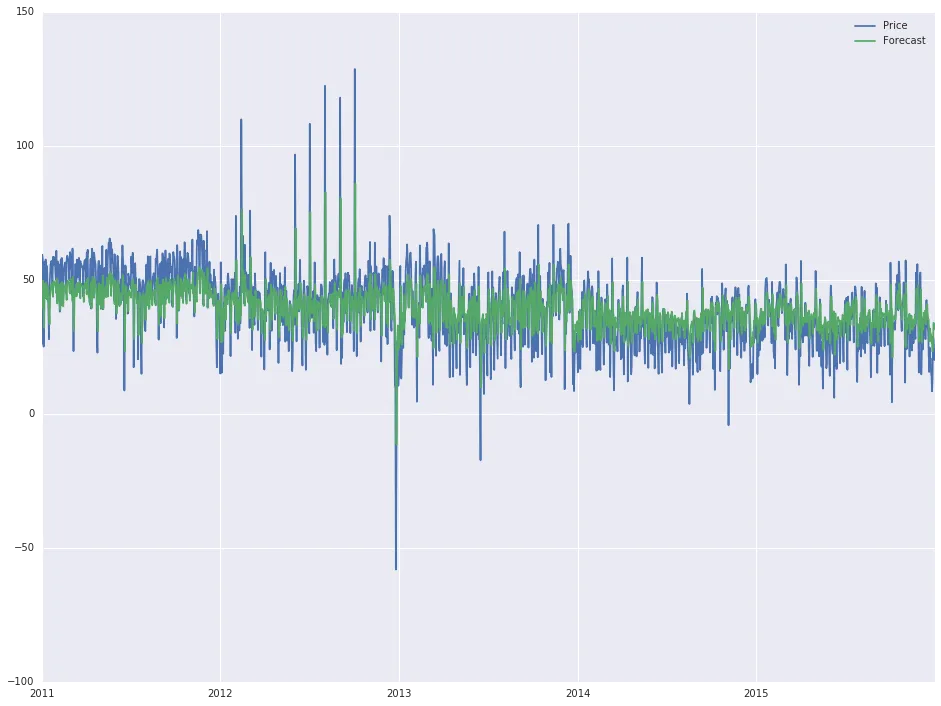
读取输入文件并将日期列设置为日期时间索引后,使用以下脚本开发可用数据的预测:
model = sm.tsa.ARIMA(df['Price'].iloc[1:], order=(1, 0, 0))
results = model.fit(disp=-1)
df['Forecast'] = results.fittedvalues
df[['Price', 'Forecast']].plot(figsize=(16, 12))
,它会产生以下输出:
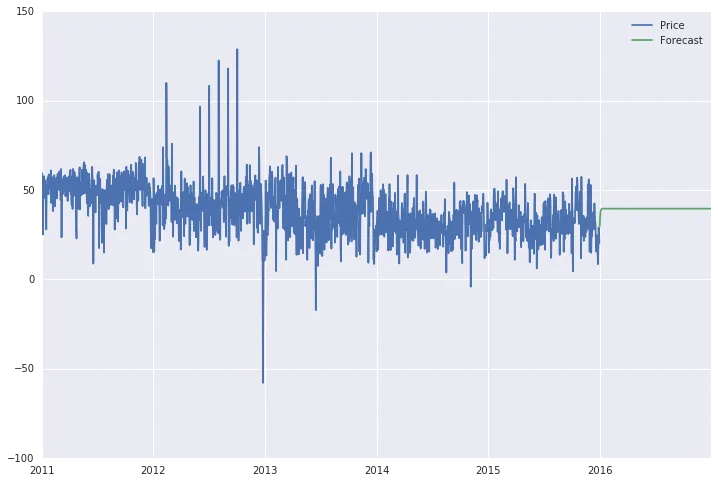
为了做到这一点,在数据框中创建了额外的行,如下所示:
start = datetime.datetime.strptime("2016-01-01", "%Y-%m-%d")
date_list = pd.date_range('2016-01-01', freq='1D', periods=366)
future = pd.DataFrame(index=date_list, columns= df.columns)
data = pd.concat([df, future])
最后,当我使用statsmodels的.predict函数时:
data['Forecast'] = results.predict(start = 1825, end = 2192, dynamic= True)
data[['Price', 'Forecast']].plot(figsize=(12, 8))
我得到的预测结果是一条直线(见下文),这似乎完全不像一个预测。此外,如果我将范围扩展到整个6年时间跨度(2011-2016年),现在从第1825天到第2192天(2016年),预测线在整个期间都是一条直线。
我还尝试使用“statsmodels.tsa.statespace.sarimax.SARIMAX.predict”方法,该方法考虑了季节变化(在这种情况下是有意义的),但我遇到了关于“模块”没有属性“SARIMAX”的错误。但这是次要问题,如果需要可以深入讨论。
我感觉自己在某些地方失去了掌控,但我不知道具体是哪里。谢谢阅读。干杯!