如何使用Matplotlib在Python中利用数据列表绘制直方图?
168
- DataVizGuys
1
有趣的是,你的数据不是加起来等于1,而是约为4.88。 - Roman Pavelka
5个回答
290
如果您想要一个直方图,您不需要给x值附加任何“名称”,因为:
- 在
x轴上您将拥有数据的区间 - 在
y轴上是计数(默认)或频率(density=True)
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
np.random.seed(42)
x = np.random.normal(size=1000)
plt.hist(x, density=True, bins=30) # density=False would make counts
plt.ylabel('Probability')
plt.xlabel('Data');
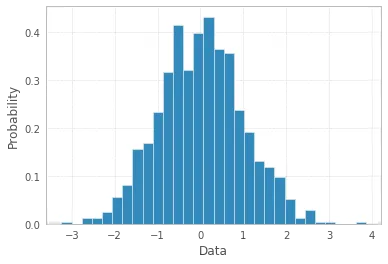
请注意,选择bins=30的数量是任意的,而选择“正确”的箱宽度有Freedman-Diaconis规则以更科学的方式进行:
,其中
IQR是四分位距,n是要绘制的数据点的总数
因此,根据这个规则,可以计算出bins的数量:
q25, q75 = np.percentile(x, [25, 75])
bin_width = 2 * (q75 - q25) * len(x) ** (-1/3)
bins = round((x.max() - x.min()) / bin_width)
print("Freedman–Diaconis number of bins:", bins)
plt.hist(x, bins=bins);
Freedman–Diaconis number of bins: 82
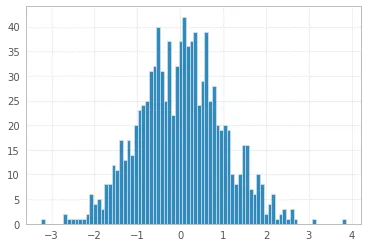
最后,您可以使用PDF线、标题和图例使您的直方图变得更加漂亮:
import scipy.stats as st
plt.hist(x, density=True, bins=82, label="Data")
mn, mx = plt.xlim()
plt.xlim(mn, mx)
kde_xs = np.linspace(mn, mx, 300)
kde = st.gaussian_kde(x)
plt.plot(kde_xs, kde.pdf(kde_xs), label="PDF")
plt.legend(loc="upper left")
plt.ylabel("Probability")
plt.xlabel("Data")
plt.title("Histogram");
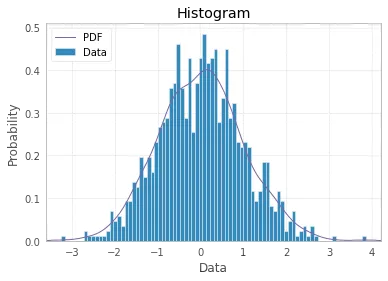
如果你愿意尝试其他机会,使用seaborn可以更快捷:
# !pip install seaborn
import seaborn as sns
sns.displot(x, bins=82, kde=True);
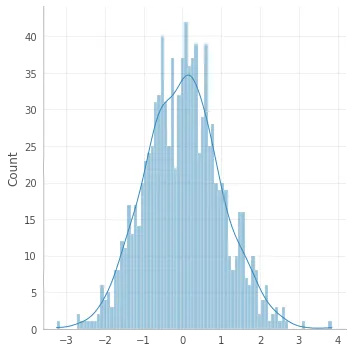
现在回到原帖。
如果您的数据点数量有限,使用条形图更有意义来表示您的数据。然后,您可以将标签附加到x轴:
x = np.arange(3)
plt.bar(x, height=[1,2,3])
plt.xticks(x, ['a','b','c']);
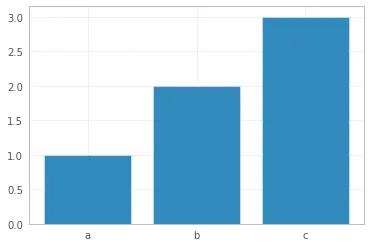
- Sergey Bushmanov
6
9记住,在Python中不需要在行末加分号! - Toad22222
16这是来自IPython笔记本单元格的摘录。尝试在没有分号的情况下执行它,看看有什么区别。我在SO上发布的所有代码片段都可以在我的电脑上完美运行。 - Sergey Bushmanov
7如果你想知道Sergey使用的分号是什么意思,可以参考这里和这里。在Jupyter笔记本(以前是IPython笔记本)中绘图时,分号用于抑制有关绘图对象的文本输出。请注意,这种用法是为了显示更干净的输出而不是改变代码行为。 - Wayne
3如果你遇到了“OverflowError: cannot convert float infinity to integer”的错误提示,只需要将小数点前的0去掉,例如将0.25改为25,将0.75改为75即可。请注意不要更改原本的意思。 - JustMe
我把点赞数改成了250个 :)。附言:喜欢这个详细的解释。 - Joker
@Jake,历史正在创造中。等待您来庆祝1250个赞。 - Sergey Bushmanov
27
如果您尚未安装matplotlib,请尝试运行此命令。
如果您尚未安装matplotlib,请尝试运行此命令。
> pip install matplotlib
导入库
import matplotlib.pyplot as plot
直方图数据:
plot.hist(weightList,density=1, bins=20)
plot.axis([50, 110, 0, 0.06])
#axis([xmin,xmax,ymin,ymax])
plot.xlabel('Weight')
plot.ylabel('Probability')
显示直方图
plot.show()
输出结果如下:
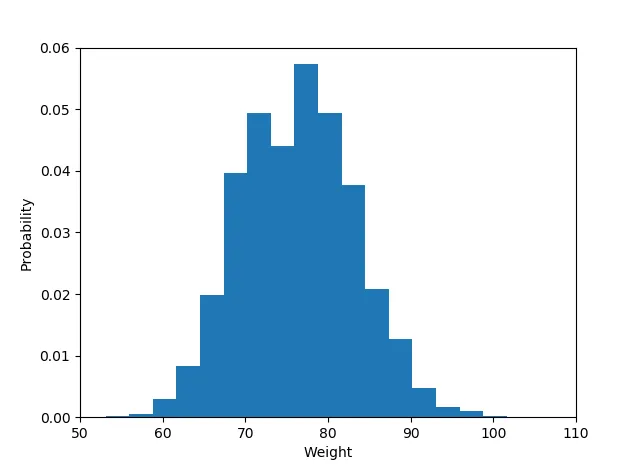
- Niraj
1
4“plot.axis([50, 110, 0, 0.06])” 这行代码对这个例子来说是没用的。另外,由于它在代码中硬编码了图形的区域大小,如果你的数据无法完全显示在这个区域内,你可能会困惑为什么图形没有正确显示。 - typhon04
6
这是一个老问题,但之前的回答都没有解决实际问题,即问题本身存在问题。首先,如果概率已经计算出来了,即直方图聚合数据以标准化方式可用,则概率应该加起来等于1。很明显它们没有,这意味着有些地方出了问题,可能是术语、数据或问题提出的方式有误。其次,标签是提供的(而不是区间),通常意味着概率是分类响应变量,使用条形图绘制直方图最好(或一些对pyplot的hist方法进行修改的方法),Shayan Shafiq的答案提供了代码。然而,请注意第1个问题,这些概率是不正确的,在这种情况下使用条形图作为“直方图”是错误的,因为它无法说明单变量分布的情况,由于某种原因(也许类别重叠并且观察值被多次计数?)在这种情况下不应称之为直方图。
直方图是单变量分布的图形表示(参见直方图|NIST/SEMATECH统计方法e-手册和直方图|维基百科),通过绘制代表感兴趣变量中选择类别的计数或频率的大小的条形来创建。如果变量在连续尺度上测量,那么这些类别就是区间(bin)。直方图创建过程的重要部分是选择如何对分类变量的响应类别进行分组(或不分组),或者如何将可能值的域分成间隔(在哪里放置bin边界)以用于连续类型变量。所有观察结果都应该被表示,并且每个结果只能在图中出现一次。这意味着条形的大小之和应等于观察次数的总数(或它们的面积,这是一种较少见的方法)。或者,如果直方图被标准化,则所有概率必须加起来等于1。
如果数据本身是一个“概率”列表作为响应,即观测值是每个研究对象的某种概率值,则最好的答案就是简单地使用
然后条形图不应该被用作直方图,而应该简单地进行操作。
结果是一个数组的元组,第一个数组包含观测计数,即将显示在图形y轴上的内容(它们总共为13个观测),第二个数组是x轴的区间边界。
可以检查它们是否等间距。
直方图是单变量分布的图形表示(参见直方图|NIST/SEMATECH统计方法e-手册和直方图|维基百科),通过绘制代表感兴趣变量中选择类别的计数或频率的大小的条形来创建。如果变量在连续尺度上测量,那么这些类别就是区间(bin)。直方图创建过程的重要部分是选择如何对分类变量的响应类别进行分组(或不分组),或者如何将可能值的域分成间隔(在哪里放置bin边界)以用于连续类型变量。所有观察结果都应该被表示,并且每个结果只能在图中出现一次。这意味着条形的大小之和应等于观察次数的总数(或它们的面积,这是一种较少见的方法)。或者,如果直方图被标准化,则所有概率必须加起来等于1。
如果数据本身是一个“概率”列表作为响应,即观测值是每个研究对象的某种概率值,则最好的答案就是简单地使用
plt.hist(probability),也许还有分组选项,并且已经可用的x标签的使用是可疑的。然后条形图不应该被用作直方图,而应该简单地进行操作。
import matplotlib.pyplot as plt
probability = [0.3602150537634409, 0.42028985507246375,
0.373117033603708, 0.36813186813186816, 0.32517482517482516,
0.4175257731958763, 0.41025641025641024, 0.39408866995073893,
0.4143222506393862, 0.34, 0.391025641025641, 0.3130841121495327,
0.35398230088495575]
plt.hist(probability)
plt.show()
带着结果
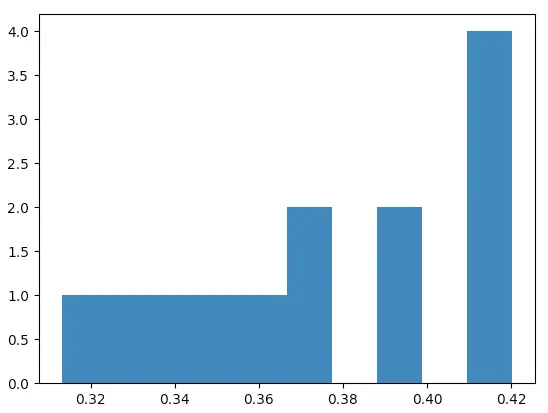
(array([1., 1., 1., 1., 1., 2., 0., 2., 0., 4.]),
array([0.31308411, 0.32380469, 0.33452526, 0.34524584, 0.35596641,
0.36668698, 0.37740756, 0.38812813, 0.39884871, 0.40956928,
0.42028986]),
<a list of 10 Patch objects>)
结果是一个数组的元组,第一个数组包含观测计数,即将显示在图形y轴上的内容(它们总共为13个观测),第二个数组是x轴的区间边界。
可以检查它们是否等间距。
x = plt.hist(probability)[1]
for left, right in zip(x[:-1], x[1:]):
print(left, right, right-left)
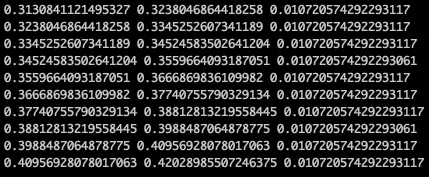
例如,对于3个箱子(我在13个观测值的情况下做出的判断),将得到以下直方图
plt.hist(probability, bins=3)
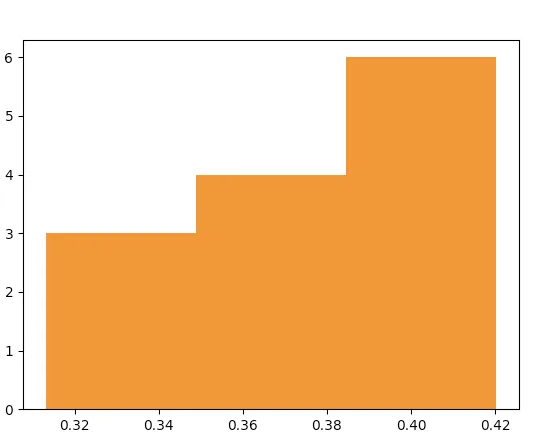
使用“behind the bars”绘制的图表数据

- predmod
1
你做得太好了!这个问题有缺陷。很好的发现。 - Rich Lysakowski PhD
6
尽管问题似乎要求使用
我假定有一个名字样本列表对应于给定的概率以绘制图表。这里简单的条形图可用于解决给定的问题。可以使用以下代码:
matplotlib.hist() 函数绘制直方图,但可以说在同样的要求下使用该函数是行不通的,因为问题的后半部分要求将给定的概率用作条形的 y 值,将给定的名称(字符串)用作 x 值。我假定有一个名字样本列表对应于给定的概率以绘制图表。这里简单的条形图可用于解决给定的问题。可以使用以下代码:
import matplotlib.pyplot as plt
probability = [0.3602150537634409, 0.42028985507246375,
0.373117033603708, 0.36813186813186816, 0.32517482517482516,
0.4175257731958763, 0.41025641025641024, 0.39408866995073893,
0.4143222506393862, 0.34, 0.391025641025641, 0.3130841121495327,
0.35398230088495575]
names = ['name1', 'name2', 'name3', 'name4', 'name5', 'name6', 'name7', 'name8', 'name9',
'name10', 'name11', 'name12', 'name13'] #sample names
plt.bar(names, probability)
plt.xticks(names)
plt.yticks(probability) #This may be included or excluded as per need
plt.xlabel('Names')
plt.ylabel('Probability')
- Shayan Shafiq
5
这是一种非常迂回的方法,但如果您想制作直方图,已知bin值但没有源数据,则可以使用np.random.randint函数生成每个bin范围内正确数量的值以进行图形绘制,例如:
import numpy as np
import matplotlib.pyplot as plt
data = [np.random.randint(0, 9, *desired y value*), np.random.randint(10, 19, *desired y value*), etc..]
plt.hist(data, histtype='stepfilled', bins=[0, 10, etc..])
关于标签,您可以将x轴刻度与条形图对齐,得到如下结果:
#The following will align labels to the center of each bar with bin intervals of 10
plt.xticks([5, 15, etc.. ], ['Label 1', 'Label 2', etc.. ])
- Connor Wilmers
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 20 如何使用matplotlib绘制collections.Counter直方图?
- 4 使用matplotlib绘制直方图或散点图
- 17 Matplotlib - 已经分组的数据如何绘制阶梯状直方图
- 28 使用 NumPy 直方图输出绘制 Matplotlib 直方图
- 27 在matplotlib中从直方图数据绘制折线图
- 15 Python / Matplotlib绘制datetime.time的直方图。
- 7 如何使用matplotlib中的直方图输出绘制散点图?
- 36 如何从数据列表创建直方图并使用matplotlib绘制
- 4 使用 matplotlib 利用坐标系绘制一条线
- 3 在 Pandas 中使用 Matplotlib 对分组数据进行直方图绘制