I have a dataframe:
df = pd.DataFrame(np.random.randint(0,100,size=(5, 2)), columns=list('AB'))
A B
0 92 65
1 61 97
2 17 39
3 70 47
4 56 6
以下是5%分位数:
down_quantiles = df.quantile(0.05)
A 24.8
B 12.6
这里是用于低于分位数的值的掩码:
outliers_low = (df < down_quantiles)
A B
0 False False
1 False False
2 True False
3 False False
4 False True
我希望将df中低于分位数的值设置为所在列的分位数。可以按照以下方式进行操作:
df[outliers_low] = np.nan
df.fillna(down_quantiles, inplace=True)
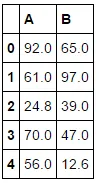
A B
0 92.0 65.0
1 61.0 97.0
2 24.8 39.0
3 70.0 47.0
4 56.0 12.6
但是肯定有更优雅的方法。我如何在不使用fillna的情况下完成这个操作呢?谢谢。
df[~outliers_low].fillna(down_quantiles, inplace=True)。 - EdChum